




すでに提供されている着脱可能なファイバーカプラーを使用できる
PICと光ファイバーの接続部の拡大図が下の画像である。要するにこの接続部もPIC構築時にまとめて構築できるので構築が容易、という話である。

基板にV字型の溝を掘り、そこにファイバーを配することでファイバーの中心に光が通るように工夫されている(左図)。ここに通すのは1波(中央図)だけでなく、複数波(右図)も可能
実際にこれを利用して、32本のファイバーを集積した例が下の画像である。127μmピッチで32chなので全体の幅は4mmほど。仮にファイバー1本あたり100Gbpsを流したとして、3.2Tbps/4mm=0.8Tbps/mmとなり、2022年の目標にかなり近いところまでは来ているわけだ。
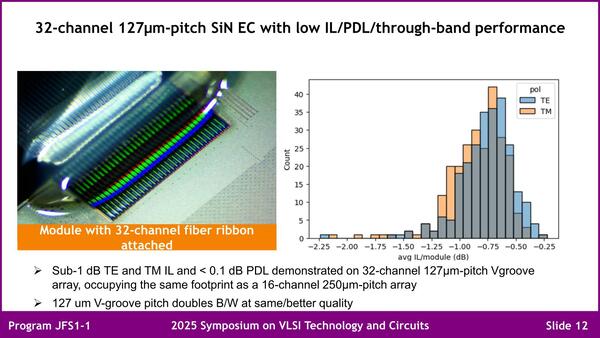
ちなみに普通は送受信で別々の光ファイバーを使うことになるが、例えば送信と受信を別々の波長にして1本のファイバーで通信することも可能だし、そもそもWDMでファイバー1本あたり8波長多重にすれば、送受信を別のファイバーにしても3.2Tbps/mmが実現できるので、このあたりはいくらでもやりようがある
このFiber Attachを利用した、Detachable(つまり着脱可能)なファイバーのソリューションをすでに提供しているのがイスラエルのTeramountで、すでにこのGFのFiber AttachをベースにしたUniversal Photonic Couplerその他を提供している。

これは概念図というか模式図であるが、要するにGPUのダイの脇にCPOのダイがあり、そこからファイバーが出てGPU同士の接続などに使える、というものだ

もちろん、必ずしもこれを使わなければいけないというものではなく、例えばBroadcomは独自のFAU(Fiber Array Unit)を提供しているわけだが、要は自社開発しなくても、すでにソリューションとして存在しているのがポイントである。実際、ASICを模したチップへのPlug/Unplugのデモも行なわれている。

機械的強度は今ひとつに見えるが、その代わり最小面積での実装が可能に見える。もっと強度が欲しければ、TeraVERSEを使うのがいいだろう
他にもAyar LabsがやはりDetachable Fiber Couplerをすでにデモしており、複数のソリューションから選ぶことが可能というのも、採用を検討している企業にはうれしい部分だろう。

Ayar Labsは2015年設立のCPOにフォーカスしたスタートアップだが、実は日本のコンポーネントメーカーとの協業も多い
最後にレーザーソースの統合の話だ。先にも少し書いたが、Fotonixではレーザー光源は外部から入力する形になっている。その統合方法が下の画像で、ダイを構成したあとのリフロー(はんだ付け)プロセスで精度を確保して統合できるとしている。

実際にはダイを切り出した後で、通常ならワイヤリングなどを行なう段階でこのレーザーソースを統合する形になる
全体としては、すでにFotonixでは確実性の高い方法で設計や製造がすでに可能になっていることを強く印象付ける講演となった。すでに第2世代、つまり45nm RF SOI CMOSプロセスに移行しているということで、このあたりはTSMCの65nm SOIよりもやや進んでいる。
その一方で、EICの方は自社で作れない(12LPPでも32Gbpsはギリギリというか少し手に余るだろう)ので、これはTSMCあたりに委託しなければいけないのが同社のウィークポイントになっている。このあたりを今後どう舵取りしていくのかが気になる部分だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























