



再学習のシミュレーションや大規模モデルの追加学習にも
基盤モデルの再学習を“ゼロ”に NTTが学習効果を引き継ぐ「ポータブルチューニング」技術
2025年07月09日 15時50分更新

基盤モデルの出力を補正する独立モデルを再利用
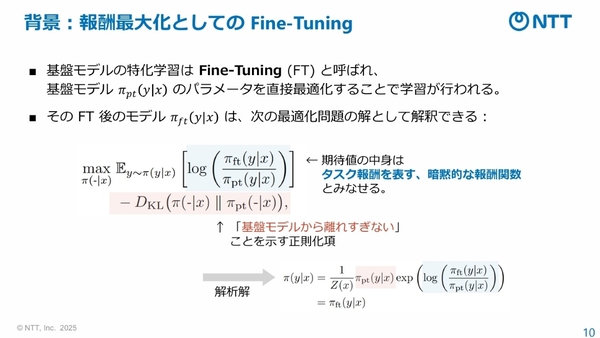
ポータブルチューニングでは、通常の特化学習が、学習時には「暗黙的なタスク報酬(与えられたタスクに対する各出力の期待値)」を学習し、推論時にはその暗黙的なタスク報酬の値を最大化すると解釈できることに着目している。
特化学習を報酬最大化として解釈
この解釈に基づき、この暗黙的なタスク報酬を直接モデル化(報酬モデル)するのが、本技術のポイントとなる。学習時には暗黙的ではなく直接的に報酬モデルを学習し、推論時にも報酬モデルの値を最大化する方向で基盤モデルの出力を補正する、新たな学習の枠組みを導出する。また、その学習過程を解析することで、モデル自身からの出力に関する報酬期待値は抑制し、正解データに対する報酬値は大きくする方向に報酬モデルの学習が進み、実際に報酬学習として期待される学習を発揮することも確認しているという。

タスク報酬を直接モデル化する新たな学習の枠組み
そして、出力補正を学習済みの報酬モデルを、他の基盤モデルの推論時にも再利用することで、特化学習と同様の効果を与えることができる。最初の学習および推論のコストが、報酬モデルの分だけ増えるものの、精度が高く、追加学習を必要としない学習転移が実現する。ただし、本技術では、出力(トークンの確立分布)で補正するため、トークン集合である語彙(ボキャブラリ)が一致している必要がある。
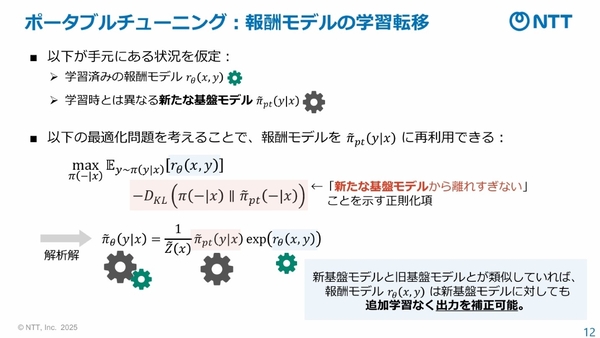
報酬モデルによる学習転移
ポータブルチューニングの性能を実験したところ、画像タスク、言語タスク共に、特化学習や指示学習に匹敵する精度で再学習ができたという。言語タスクでは、パラメータ数が0.5B(ビリオン)の基盤モデルから最大14Bの基盤モデルへの転移が検証されている。「特化学習の場合、チューニングが不十分であると精度が下がってしまうが、ポータブルチューニングによる学習転移は報酬モデルを再利用すればよいため、安定した精度が得られるのもポイント」と千々和氏。
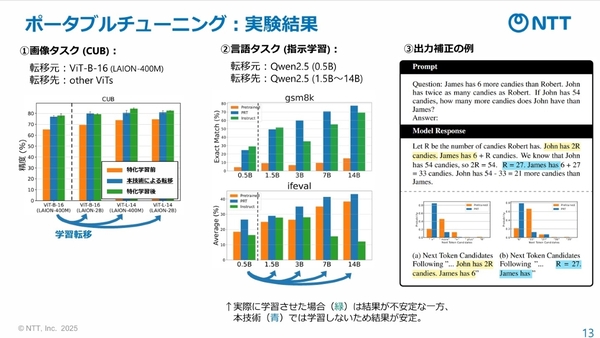
ポータブルチューニングの実験結果
再学習のシミュレーションや大規模モデルの追加学習にも
本技術は、基盤モデルの最新化・マイグレーションはもちろん、「再学習の事前シミュレーション」にも応用できるという。学習転移した基盤モデルを比較検証することで、精度を担保した上で、実際に再学習をするといった試行錯誤がしやすくなる。
大規模モデルの追加学習コストを低減することも可能だ。小規模な報酬モデルのみで追加学習させていくことで、学習時の計算コストを大幅に削減できる。「アダプター的な使い方ができ、かつ他のアダプター手法とも併用できる」(千々和氏)
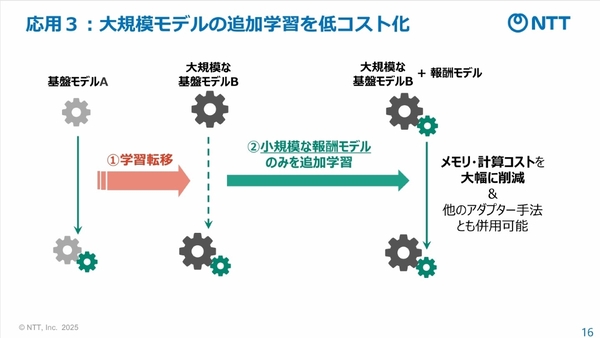
大規模モデルの追加学習を低コスト化
今後は、NTTの独自LLMである「tsuzumi」の基盤モデルの更新や、多様なAIを相互連携させる「AIコンステレーション」における大量の基盤モデルの自動更新において、本技術を活用する予定だという。
竹内氏は、「まずは、ボキャブラリという制限の内で有効性を引き続き検証していく。2026年度を目途に、商用化できるかどうかの有用性を明らかにしたい」と展望を述べた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



