



RTX 5070、RTX 4060 Ti、RTX 3060 Ti、RTX 2060 SUPERと比較
GeForce RTX 5060 Tiの16GB版を検証、“xx60 Tiの欠点”は克服できたのか?
2025年04月16日 22時00分更新

RTX 5070に勝てるAI処理もある
ここからはAI系の検証に入る。まずはUL Procyonを利用し、LLM(大規模言語モデル)系テストである「AI Text Generation Benchmark」を試そう。大小4つの学習モデルにそれぞれ7つのテキスト生成タスクを課し、出力されるトークン(単語)生成スピードおよび最初のトークンまでの待ち時間からスコアーを導き出す。
総合スコアーのほか、その算出の根拠であるトークン生成スピードと、最初のトークンまでの時間を比較する。
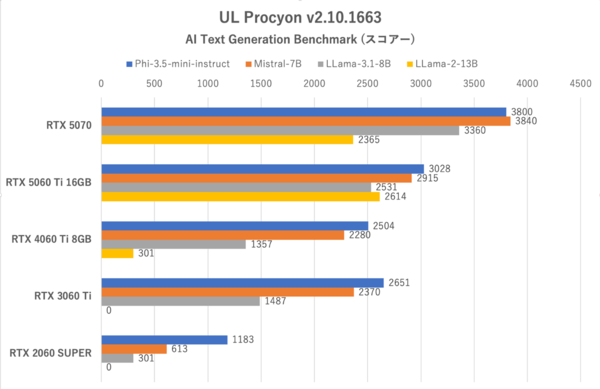
UL Procyon:AI Text Generation Benchmarkのスコアー。学習モデルはPhi-3.5-mini-instructが最も軽く、LLama-2-13Bが最も重い
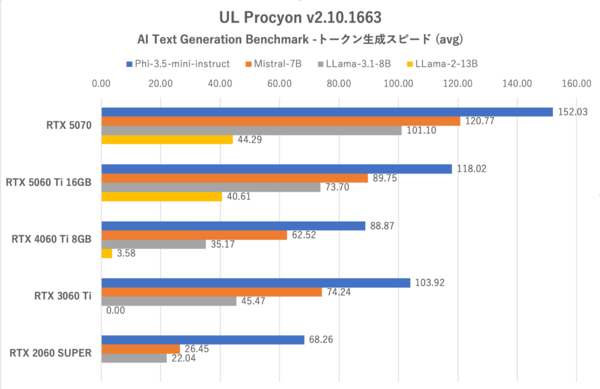
UL Procyon:AI Text Generation Benchmarkにおけるトークン生成スピード。テストごとに平均値で集計している
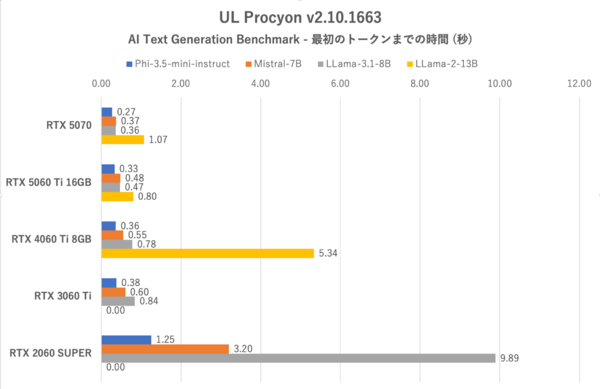
UL Procyon:AI Text Generation Benchmarkにおける最初のトークンまでの時間
今回用意したGeForceの中で、4本のテストを完走できたのはRTX 4060 Ti 8GBまで。RTX 3060 TiとRTX 2060 SUPERに関しては、4本目のLLama-2-13Bはエラーでスコアーが算出できなかった。
総合スコアーのトップはほかの検証と同様にRTX 5070だが、唯一LLama-2-13Bにおいては最初のトークンまでの時間において、RTX 5060 Ti 16GBに負けている。学習モデルが大きくVRAM 12GBのRTX 5070では持て余し気味になるためであり、VRAMに余裕のあるRTX 5060 Ti 16GBが優位に立つようだ。
LLMについてもう少し掘り下げるために、「MLPerf」と「LM Studio」も使って検証しよう。まずMLPerfでは学習モデル「llama-2-7b-chat-dml」を利用する。これは4つの課題(「Content Generation」「Creative Writing」「Summarization, Light」「Summarization, Moderate」)を出し、その際のトークン生成スピードや最初のトークンまでの時間を計測するものである。
UL Procyonとの違いは学習モデルのサイズ違いやお題の内容のほか、総合スコアーというものを出さないという点にある。全部グラフにするとデータが多いので、最も軽いお題と最も重いお題に注目してみたい。
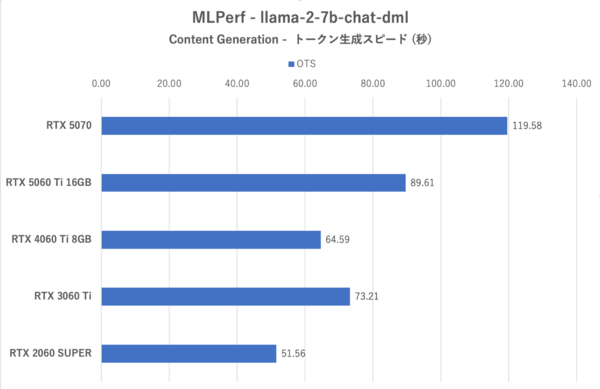
MLPerf:4つのお題のうち最も軽いContent Generationにおけるトークン生成スピード
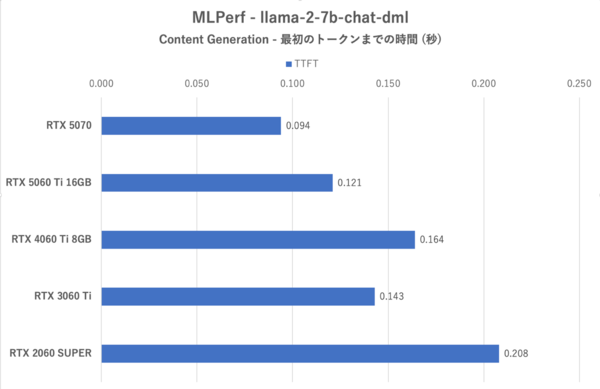
MLPerf: Content Generationにおける最初のトークンまでの時間
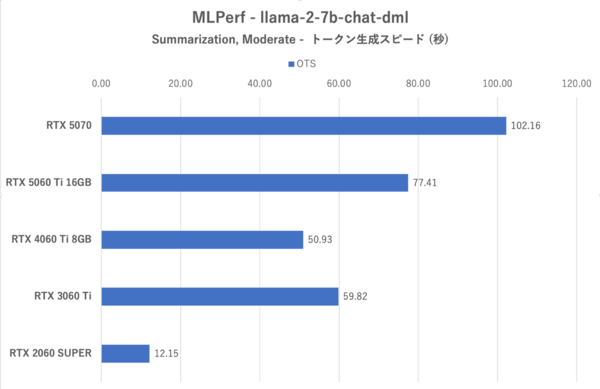
MLPerf:4つのお題のうち最も重いSummlization, Moderateにおけるトークン生成スピード
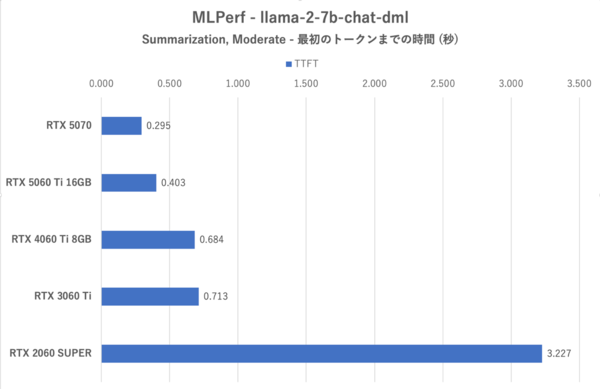
MLPerf:Summlization, Moderateにおける最初のトークンまでの時間
RTX 3060 TiおよびRTX 2060 SUPERの成績がかんばしくないこと、RTX 5070が最も優秀であるという傾向に変わりはない。このテストの場合、VRAM 8GBでは終盤のテストでかなり不利になるが、その点RTX 5060 Ti 16GBは余裕がある。一方で、RTX 4060 Ti 8GBはRTX 3060 Tiよりもトークン生成スピードも最初のトークンまでの時間もRTX 3060 Tiに劣るが、これはメモリー帯域の細さが災いしている。
RTX 4060 TiはVRAM 8GBしか持たないがゆえにここでの評価はいまひとつだが、RTX 5060 Ti 8GBがあった場合、RTX 4060 Ti 8GBと比べるとどうなるか? VRAMは両者同じように枯渇するがメモリー帯域はRTX 5060 Ti 8GBのほうが上になる。今回レビュー用機材に8GB版をお借りできなかったのが何より残念だ。
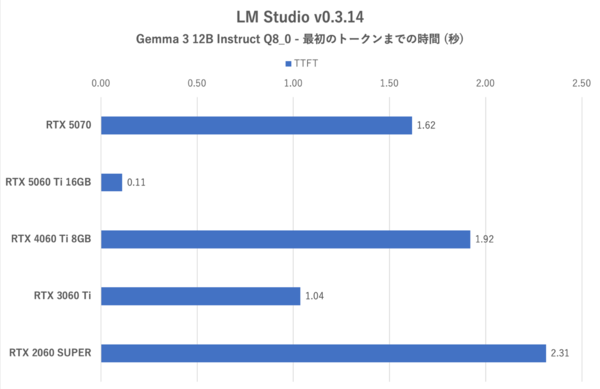
続いては、「LM Studio」による検証だ。ここではもっと大きな「Gemma 3 12B instruct Q8_0(容量約12.5GB)」を使用する。GPUオフロードは最大化(CPUは極力使わない)、シードも共通の固定値とした。
テストは「消えた1ドルの謎」(下記の囲みを参照)を解説させるというものだ。1度回答を得るたびにモデルをロードしなおして再出力。こちらもトークン生成スピードと最初のトークンまでの時間に着目し、各々3回の平均値で比較する。
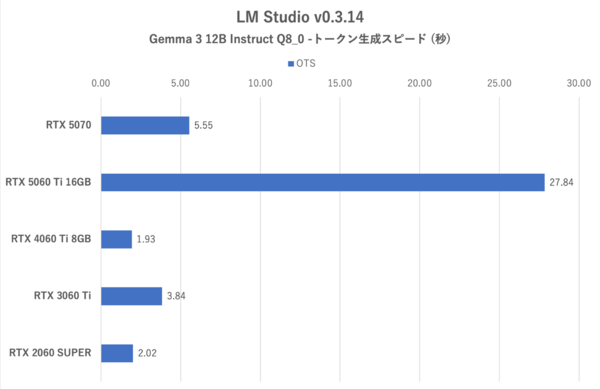
LM Studio:Gemma 3 12B Instruct Q8_0における最初のトークンまでの時間
LM Studio:Gemma 3 12B Instruct Q8_0におけるトークン生成スピード
学習モデルのダウンロードサイズが12GBを超えると、さすがにVRAM 12GB以下では厳しくなってくる。RTX 5060 Ti 16GBだけはVRAMに余裕があるため、トークン生成スピードはRTX 5070を圧倒するし、最初のトークンが出力される時間も圧倒的に短くなる。
3DMarkのようなグラフィックパフォーマンスは、RTX 4060 Ti 8GBに比べてせいぜい30%アップ止まりだが、VRAMへのプレッシャーが強いローカルAI処理では、RTX 5060 Ti 16GBのほうが4倍近いアウトプットを叩き出せることもあるのだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第35回
自作PC
DLSS 4.5の画質と性能を検証!プリセットを変えるとGeForceのフレームレートはどのぐらい落ちる? -
第34回
PCパーツ
いまさら聞けないNVIDIAのDLSSを最新の4.5までまるっと解説 もうドットバイドットの画質を超えている -
第33回
トピックス
NVIDIA「GeForce RTX 5050」4万4800円から 7月下旬発売 -
第32回
自作PC
GeForce RTX 5060をゲーム11本でベンチマーク、「これでいい」と「VRAM 8GBはつらい」のせめぎ合い -
第31回
自作PC
GeForce RTX 5060、旧世代に動画エンコードやAIの強さを見せつける -
第30回
自作PC
GeForce RTX 5060をプレビュー、VRAM 8GBでも安ければ許される? -
第29回
自作PC
GeForce RTX 5060 Ti 8GBは今のPCゲーム環境では“理”のある選択ではない -
第28回
自作PC
GeForce RTX 5060 Ti 16GBをゲーム13本で性能検証、RTX 5070の微妙な立ち位置が浮き彫りに -
第26回
PCパーツ
NVIDIAがGeForce RTX 5060 Ti&RTX 5060を投入、299〜429ドル帯の最新GPU -
第25回
自作PC
フレームレート集計に革命!?NVIDIAのAIフレームワーク「Project G-Assist」でベンチマークライターは失業する? - この連載の一覧へ

































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")













