




SambaNovaは連載510回で説明したあと、連載792回でHotChips 24での説明を元にSN40Lを紹介したが、この時にはいろいろ謎が残った。なのだが、ISSCCのInvited Industryセッション(Session 16)で同社が"SambaNova SN40L: A 5nm 2.5D Dataflow Accelerator With Three Memory Tiers for Trillion Parameter AI"(Session 16.4)として不明な点を明らかにしてくれたので、連載792回で間違っていた部分の訂正もかねて解説したい。
SN40Lの脇に12本づつのRDIMMスロットを用意して
メモリーの実装を実現
まず不明点というか間違っていた点の訂正から。EETimesの2022年9月28日の記事の最後の写真には"SambaNova unveiled its SN30 RDUーwith two compute chiplets and 1 TB of direct-access DDR in this package."というキャプションが付いており、「どうやったらこのパッケージにDDRメモリーを全部収められるんだ?」と相当頭をひねった結果が下の画像だったわけだが、案の定こんなことはなかった。

連載792回で筆者が想定したSambaNova SN30の構造
下の画像はSN40Lを2つ搭載したXRDLU基板の写真だが、SN40Lの脇に12本づつのRDIMMスロットが用意されている。常識的な実装で一安心である。
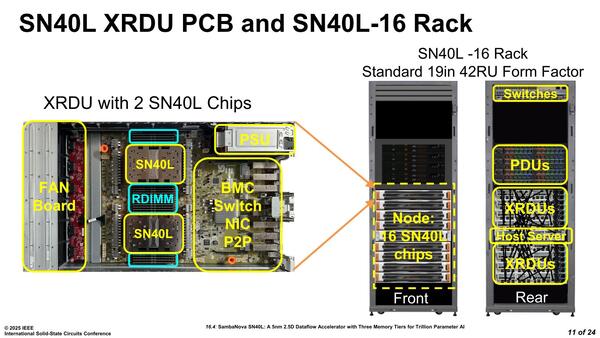
SN40Lを2つ搭載したXRDLU基板。最初からこの写真を出していてくれれば、パッケージ内にDIMMを突っ込むなんていうアイディアをひねりだす必要はなかった
ということでここからはISSCCでの発表を。下の画像はHotChipsのものと同じであるが、それぞれのSN40Lには12本のRDIMMスロットが接続される。ということでスロットあたり128MB、12スロットで1.5TBという計算かと思われる。

右上および左下のHBMのようなものはダミーであり、実際には1つのチップに2つのHBMが接続される構造。「だったら片側に寄せればパッケージが小型化できるのに」と思うが、おそらくチップを180度回転させて接続している関係で、こういう構造にせざるを得なかったのだろう
それはいいのだが、これが12ch(つまりチップあたり6ch)なのか、6ch(チップあたり3ch)なのか、というのが次の疑問である。メモリー階層図(下図)を見ると、HBMは1.6TB/秒、RDIMMは100GB/秒となっている。
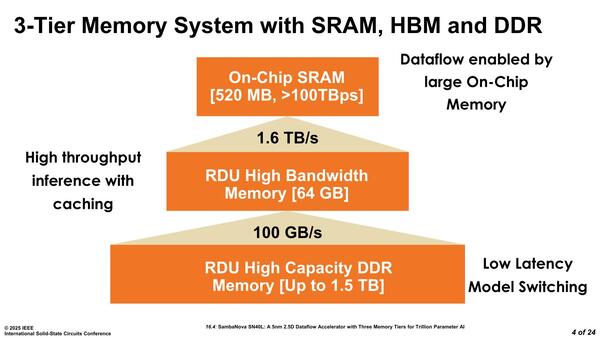
HBMはチップあたりHBMが2スタックで1.6TB/秒、容量64GBとなっており、つまり1スタックで800GB/秒、32GBという計算になるので、おそらくHBM3eをベースにしているものと思われる
前提として、DDR5の場合2 DIMM/chで安定して動作するのはDDR5-4400までとされており、実際これを超えるとまともに動かないケースがほとんどである。仮にDDR5-4400とすると1chあたり35.2GB/秒、これを3chにすると105.6GB/秒になって、ちょうど100GB/秒という計算になる(あるいは安定性を重視してDDR5-4200とかDDR5-400駆動の可能性もある。これでも四捨五入すればだいたい100GB/秒である)。
一方1 DIMM/chであればそれこそDDR5-6400まで可能なのだが、一応DDR5-4800の場合を考えると1chあたり38.4GB/秒で、これが6chだと230.4GB/秒になって数字が合わない。つまり最初から1chあたり2DIMM構成であることを前提にチップあたり3ch/6 DIMM、SN40L全体で6ch/12 DIMM構成を取ることにしたものと思われる。
ここでなぜ12ch構成にしなかったか? であるが、おそらくパッケージの限界(DDR5は1chあたり288ピンの信号線を必要とする。もちろん電源やGNDのように共通化できるものもあるが、それでも1ch増やすと100本以上は平気で増えるので、6chと12chでは1000本近くピン数が変わってくる)ことと、そもそも高速なメモリーという意味ではHBMがあり、ここで無理して12ch構成にして帯域を上げてもそれほど大きな性能向上にはつながらない(仮にDDR5-6000だとしても288GB/秒程度にしかならず、1.6TB/秒のHBMとのギャップは大きい)し、むしろ消費電力が増えるだけという判断があったのだと思われる。
実際のところDDR5-6000×12chとDDR5-4400×6ch×2 DIMMでは、DIMM全体の消費電力は倍近く変わる。性能面での寄与がそれほどないわりに消費電力が増える、というあたりも嫌われたのだろう。
それでも、最大で1.5TBもあればかなり大規模なLLMであってもすべてをオンメモリーで処理できることになる。これがCelebrasならSwarmX経由でMemory Xからパラメーターをロードする必要があるし、NVIDIAのGPUを含むその他のAIアクセラレーターだったらホスト(NVIDIAならGrace CPU、その他ならXeonなりEPYCなり)からPCIe(かNVLink)経由などでパラメーターを転送するしかない。
"Low Latency Model Switching"というのは、こうしたホスト経由での転送よりはるかに迅速にパラメーターの入れ替えやロードが可能になる、という意味である。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































