



ロードマップでわかる!当世プロセッサー事情 第816回
シリコンインターポーザーを使わない限界の信号速度にチャレンジしたIBMのTelum II ISSCC 2025詳報
2025年03月24日 12時00分更新

シリコンインターポーザーを使わない限界の信号速度にチャレンジ
次にM-Busである。M-Busはチップの下辺全面にPHYが配されており、これ全体で2つのチップ間を接続する形だ。帯域は238GB/秒となかなかの速度である。シリコンインターポーザーを介していないことを考えると信号速度は32GT/秒を超えない程度だろう。ざっくり試算すると29.5GT/秒で8192bitだとちょうど238GB/秒になる。
この場合、ディファレンシャルでしかも双方向では配線数そのものは3万2768本に達する。一列に並べると配線ピッチは0.76μmというすさまじいものになる。もちろんこれを接続するバンプの方は横一列に並んでいるわけではないにしても、結構高密度なバンプになりそうだ。この速度は、シリコンインターポーザーを使わない限界にチャレンジした結果という感じがする。なお、ここで出てくる"Synchronous connection to the high-speed ring"は後で出てくる。
一方、DCM同士を接続するX-Busの方は、帯域66GB/秒とされる。ここで言う36%の帯域向上はTelumとの比較であるが、20.8Gbps→29.3333Gbpsだと41%ほどの向上になる。なにかしらオーバーヘッドになる要因があって、実際には36%の向上に留まるようだ。CPUコア(とL2)に配されるクロックメッシュは5.5GHz駆動なので、X-BusとのI/Fは3:1で変換するというシンプルなものになっている。

29.3333Gbpsで66GB/秒ということは、バス幅は18bitという計算になる。これはTelumも同じ構成だ
A-Busに関しては速度の説明がない。その代わりといってはなんだが、信号の暗号化方法に関する説明があった。実際の通信にあまり複雑な暗号化を使うとスループットに深刻な影響があるので、データの暗号化はAES-256で行なっているが、その前段階である暗号化鍵の受け渡しを工夫することで、鍵を盗まれにくくするというものだ。
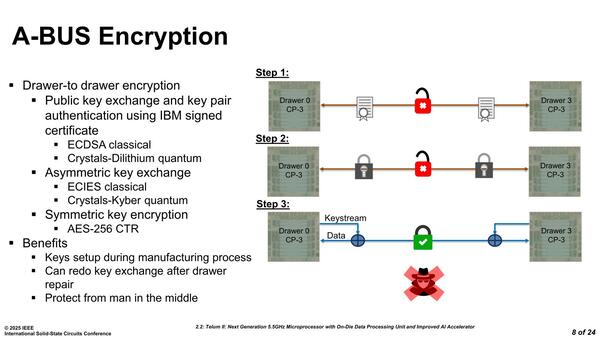
最初に公開鍵暗号を使って通信路を確立、その通信路を使って鍵を交換し、以後はその鍵を利用してAES-256で暗号化するという手順である
この方法をとった理由の1つは、下段のBenefitsの真ん中の"Can redo key exchange after drawer repair"である。Telum IIは高信頼性用途向けであり、当然ホットスワップに対応している。つまり故障が発生した場合には、電源を落とさずに問題のDrawerだけを交換するというものだ。
ただこれをやると暗号化の鍵が異なるため、もう一度鍵の交換から始めなければいけない。Telum IIでは公開鍵(と秘密鍵)が、チップの製造時に埋め込まれているので、簡単にStep 1からやり直すことで直ちに通信を復旧できるのがメリットというわけだ。
2次キャッシュはSamsungのHigh Density SRAMを利用しているが、SamsungのSRAMセルをそのまま使っているのではなくNBL(Negative Bit Line)を利用しているほか、エラーの検出や修正をできる高信頼性の構造を構築している。

2次キャッシュに使用されているSamsungのHigh Density SRAM。1ブロックあたり36MB。Telum IIではこれが10ブロックで360MBとなる。ここまで大容量なのは、z15まで利用していたeDRAM(Embedded DRAM)ベースの3次キャッシュがSamsungのプロセスになってからプロセスの問題で利用できなくなり、その分2次キャッシュを大容量化させてカバーする方針にしたのが主な理由と思われる
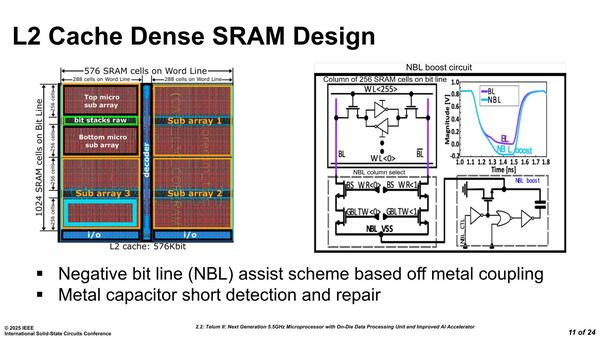
NBLは容量結合を利用して負電圧を発生させ、これを利用して書き込みを確実に行なう技法のひとつ
また、2次キャッシュは容量的にも面積的にも多く、当然消費電力も大きいので、細かく電圧制御するようになっている。この2次キャッシュは個々のCPUコアとは独立に動作する格好になっており、それもあっておそらくブロックごとに細かく電力制御しているようだ。
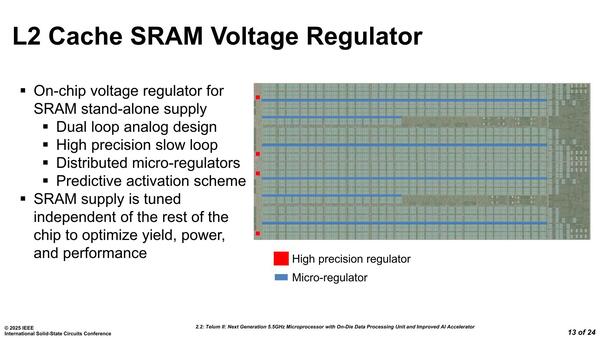
赤い部分はDC-DC Switching Regulator、水色部分がLDOだと思われる
ところで上で「2次キャッシュは個々のCPUコアでとは独立に動作する」と書いたが、論理構造的には個々のCPUコアとDPUが、それぞれ1ブロック分の2次キャッシュを占有できるようになっている(つまり1ブロックは未使用)。なのだがそれとは別のレベルですべての2次キャッシュがリングバスを構築し、さらにそのリングバスのショートカットとなるクロスバーまで配されているという、あまり見ない構造である。
連載790回のスライドで、Telumでも8つの2次キャッシュが双方向のリングバスを構成している様子が示されていたが、さらに横方向のショートカットが追加された。ちなみに、Telum IIもこれまたTelum同様に以下の機能が搭載されている。
- 同一チップ内の非アクティブなコアの2次キャッシュを3次キャッシュとして扱う
- 異なるチップ内の非アクティブなコアの2次キャッシュを4次キャッシュとして扱う
このあたりが「論理的には各2次キャッシュがCPUコアのプライベートだが、物理構造的には異なる」ゆえんである。先ほどM-Busの説明でリングに同期とあったのは、この2次キャッシュのリングバスの速度に同期しているという意味である。
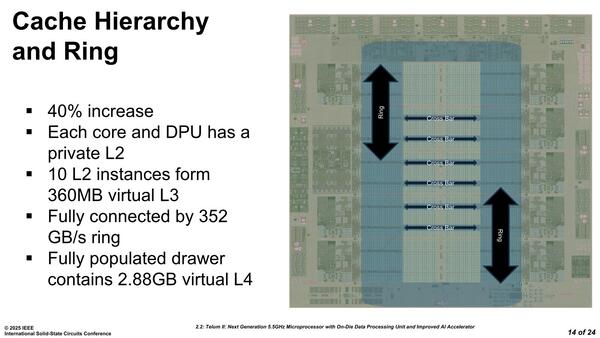
普通はPrivate L2と書いたら、それぞれのコアと連携して動く(ZenコアやインテルのPコアも同じだ)のだが、Telum IIではこのあたりが独特の実装である
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























