



オンプレミスVMware環境から、意識を変え、工夫を凝らしてGKE化・マネージドDB化
スクエニのゲーム基盤、試行錯誤重ねた“数百台のアプリ”のGoogle Cloud移設
2025年03月12日 08時00分更新

Cloud SQL編:マネージドDB化における構成見直しでコスト最適化
データベースに関しては、フルマネージドなデータベース「Cloud SQL」への移設を進めている。その経緯やマネージドDB化で苦労した点を語ったのは伊賀一貴氏だ。
当初、移設先を検討していた際には、Spannerはアプリケーションの書き換えが発生すること、Cloud SQLは計画メンテナンスの停止期間が懸念となり、「GCE(Google Compute Engine) MySQL」の採用を決定していたという。しかし、2023年に「Cloud SQL Enterprise Plus」のエディションが登場したことでCloud SQLに方向転換。2025年内には全データベースが移設完了する予定だ。

スクウェア・エニックス カスタマーエクスペリエンスデザインセンター オンラインビジネス推進ディビジョン(プラットフォーム開発グループ) SRE 伊賀一貴氏
決め手となったのは、Cloud SQL Enterprise Plusかつ“HA構成”時に、計画メンテナンスのダウンタイムが「ほぼゼロ(Near zero downtime)」になることだ。伊賀氏は、「実測だと0.5秒程度で接続回復する。サービスに影響なくメンテナンスができる強力な機能」と説明する。Near zero downtimeの対象となるのは、障害時や定期メンテナンス時、そして、スケールアップ・スケールダウンにおいても構成変更が可能になる。

Near zero downtimeの対象
こうして開始されたCloud SQLへの移設。完全MySQL互換なためアプリケーションの変更は不要で、性能も申し分ない。「性能要件が厳しい」(伊賀氏)という同社の負荷試験にも一発クリアして、CPU使用率にも優位性があったという。「Database Migration Service」を利用することで一対一の移行も容易であった。
もちろん、順調なことばかりではなかった。「良いものは高いというのが世の常」(伊賀氏)で、高性能ゆえにコストは高くついた。HA構成は、アクティブ・スタンバイなため、2つのインスタンス分のコストも生じる。すべてEnterprise Plusで試算すると、従来の1.5から2倍となり、構成を再検討せざるを得なかったという。
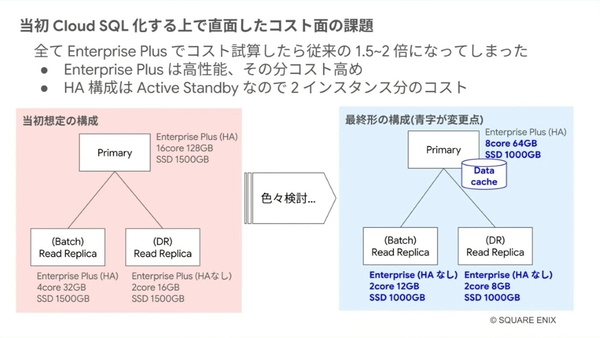
コストの面で構成を変更
まずは、データベースの用途に応じて、エディションやHA構成を見直した。PrimaryはそのままEnterprise PlusかつHA構成に、数分の停止が許容できるリードレプリカ(Read Replica)はEnterpriseかつHAなしと、エディションが混在する構成に変更。スペックに関しても、Enterprise PlusはCPU性能が高いため、core数を従来の半分に、半分になったメモリは「Data cache」というEnterprise Plusの機能でカバーした。ストレージを、自動拡張に任せて容量ぎりぎりで運用することも、効果的だったという。

スペックの全体的な見直し
このData cacheとは、コストパフォーマンスが高いLocal SSDがベースとなる、buffer poolの2次キャッシュである。最低375GB以上と大容量であり、かつ永続SDDと比べても最大3倍高速という特徴を持つ。「OSメモリが最速なため、サービスの設計や要件に応じて検討する必要があるが、メモリの部分をData cacheにメモリに任せることでコスト最適化につながる」と伊賀氏。
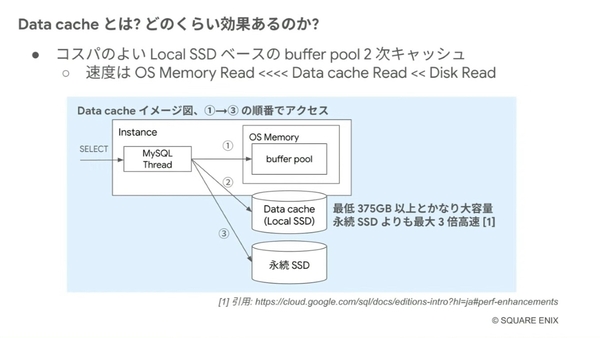
Data cacheとは
また、Cloud SQLへの移設にあわせて、DB集約もした。これは、Enterprise Plusが、「障害から自動復旧して、Near zero downtimeのオペレーションが多いからこそ」(伊賀氏)踏み切れたという。具体的には、小規模・中規模のデータベースを、MySQL native replicationでGCE relay slaveにまとめ、Database Migration ServiceでひとつのCloud SQLインスタンスに移行するという方法をとっている。現在進行中であり、サーバー台数の削減とCUD(確約利用割引)適用によって大幅なコスト最適化が見込まれるという。
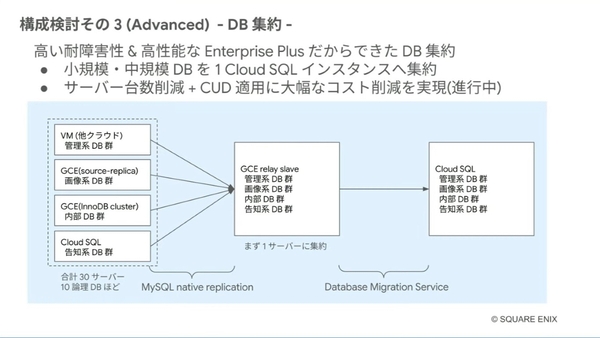
DBの集約でさらなるコスト最適化
最後に伊賀氏は、今後期待するアップデートとして、「障害時のbuffer pool warmup」「Near zero downtimeのメジャーバージョンアップグレードへの対応」「Retry実装不要なManaged Proxy / Connection pool」を挙げている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



