



オンプレミスVMware環境から、意識を変え、工夫を凝らしてGKE化・マネージドDB化
スクエニのゲーム基盤、試行錯誤重ねた“数百台のアプリ”のGoogle Cloud移設
2025年03月12日 08時00分更新

Google Cloudは、2025年3月6日、次世代インフラをテーマとしたイベント「Modern Infra Summit '25」をハイブリッドで開催。
本記事では、「ゲーム基盤システム移行クエスト そしてGoogle Cloudへ…」と題するスクウェア・エニックスのセッションを紹介する。同社が数年かけて進めてきた、オンプレVMwareベースのアプリケーションをGoogle Cloudへ移設するプロジェクトについて語られた。

某タイトルを想起させるセッション名
数十msecオーダーのAPI性能が求められたゲーム基盤の移行
詳細は伏せられたが、移行を進めたゲーム基盤は、ゲームプレイにおいて重要な役割を担うシステムであり、高性能で安定した動作が求められていた。新作ゲームのリリースやイベント時には大量のリクエストが集中し、“ネットワークが瞬断”すると数百件のエラーが発生してしまう。加えて、ユーザー体験のために、“数十msecオーダーのAPI性能”が要求されていた。
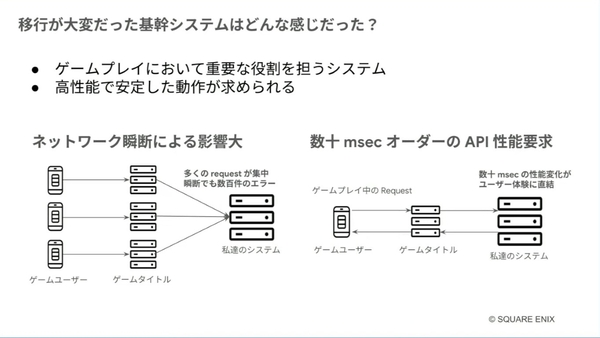
移行を進めたゲーム基盤システムシステム
移行前は、すべてのアプリケーション、データベース、Redis(インメモリデータベース)をオンプレのVM上に載せていた。アプリケーションは数百台でリクエストが最大数万rps、データベースも数百台でデータ数も数十TBという規模感である。
スクウェア・エニックスでは、2022年に同システムをGoogle Cloudに移行するプロジェクトに着手。現在、アプリケーションは「Google Kubernetes Engine(GKE)」に移設済みで、データベースは「Cloud SQL Enterprise Plus」に移設中。Redisは「Memorystore for Redis」を、その他にも、Elastic、Sysdig、New Relic、Confluentなどを採用している。本セッションでは、アプリケーションとデータベースにフォーカスして詳細が語られた。
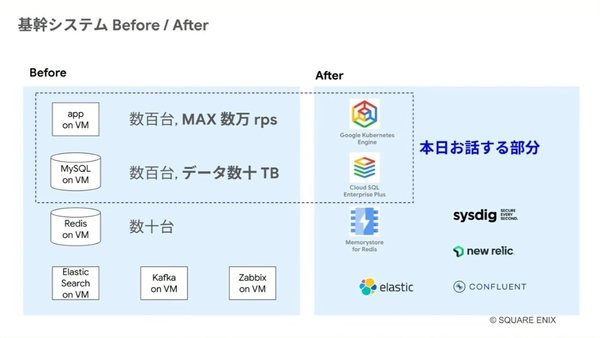
ゲーム基盤システムのBefore / After
GKE編:“落ちる前提”へのメンタルモデル転換、クラウドでの性能改善に試行錯誤
アプリケーションのオンプレVMからGKEへのマイグレーションについて説明したのは、ゲーム基盤移行のために加わったという佐藤雅宏氏だ。

スクウェア・エニックス カスタマーエクスペリエンスデザインセンター オンラインビジネス推進ディビジョン(プラットフォーム開発グループ) SRE チームリーダー 佐藤雅宏氏
ここでは、GKEベースになることで必要となった“2つの意識変革”とそれに伴う改善策について取り上げられた。
ひとつ目が、「プロセスの稼働特性」だ。もともとはオンプレであったため、安定稼働することを前提に、アプリケーションが組まれていた。基本、プロセスは動き続け、「落ちる=VMに何かが起きた」なため、障害発生時も仕方がないという意識があったという。加えて、ランタイムやミドルウェア、OSなども固定されたバージョンになりがちで、定期的なバージョンアップにも意識を割くことはなかった。
これが、Kubernetesになると、「アプリケーションがいつ落ちても大丈夫」という状態を保つ必要がある。Podのオートスケールやバージョンアップなど、さまざまなタイミングでプロセスは停止。そもそも3カ月に1回マイナーバージョンアップ時に、アプリケーションを落とさなければならない。
いつ落ちても動作し続けるアプリケーションには、「Time Out」と「PreStop(Podが停止命令から持ちこたえる時間)」の調整が重要になるという。ポイントは、リクエスト全体のTimeoutよりPreStopを長く設定することだ。もうひとつ重要になるのが、「Queueを用いた進捗管理」だ。アプリケーションやWorkerは、進捗状況やタスクの一覧を適宜Queueに保存、起動時にはQueueの状況に応じてタスクを再開する。
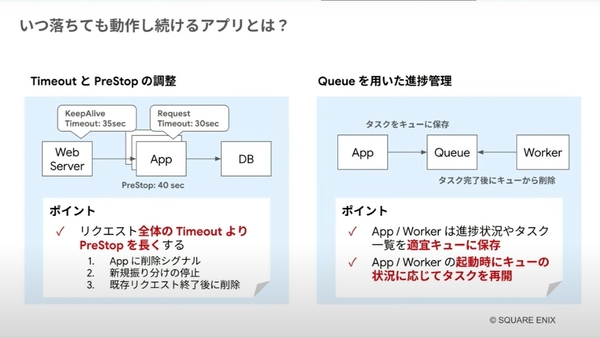
いつ落ちても動作し続けるアプリケーションで重要なこと
もうひとつの意識改革が、「距離によるネットワークの信頼性」だ。物理機器が距離的に近いオンプレでは、安定したネットワークで瞬断や遅延が発生しにくく、1から3msec程度の超低レイテンシーであった。
クラウドに移行することで、不安定なネットワークになり瞬断や遅延も定常的に発生。レイテンシーも2から10msec程度と遅くなり、必然的にAPI性能も劣化する。「ゲーム基盤システムの要件は、数十msecオーダーのAPI性能であったため、性能改善が必須であった」と佐藤氏。
しかし、Google Cloudにも協力してもらうが、クラウド環境での性能改善の方法は見つからない。そこでtcpdumpによって“パケットレベル”で調査、性能劣化の原因をひとつひとつ特定していった。
実際にとった改善策のひとつが、Cloud DNSへの名前解決回数の削減だ。GKE上のPodは名前解決したいドメインに対して複数回の問い合わせをする。これをフルドメインで記載することで、名前解決の回数が1回になるようにした。また、本環境では、Google マネージド SSL 証明書のタイプによる速度差が発生したため、従来の証明書を利用することでAPIを高速化している。

Cloud DNSへの名前解決回数の削減
データベース接続時のパケット送受信回数も削減した。「1回あたりのパケット送信はたいしたことはないと思えるかもしれないが、クラウド環境だとそれだけで5msecほどかかってしまう」と佐藤氏。データベース接続のたびに定型的なSQLクエリが発行されるため、不要なパケットの往復が増えていたという。それを、ライブラリの接続パラメータを調整することで改善している。

データベース接続時のパケット送受信回数の削減
このような地道な努力でAPI性能は要件を満たし、GKEへの移設は無事完了している。



