




フィンの数ではなくナノシートの数を増減させる技術
NanoFlex
最適化の一助となるのが、NanoFlexと呼ばれる技術である。もともとTSMCはN3の時点でFinFlexと呼ばれる、特性を変えた3種類のトランジスタを用意、これを組み合わせることで望む特性を簡単に得やすくする技術を提供していた。
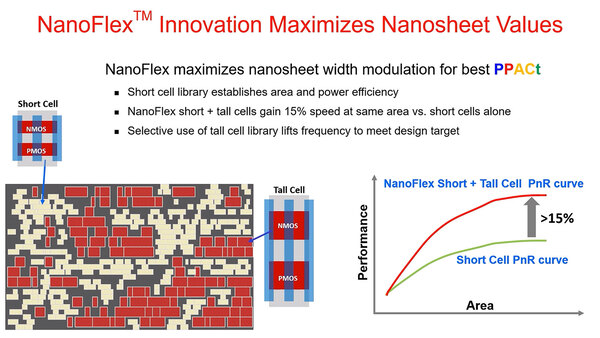
NanoFlexの概要。Short Cellはシートの数が少なく、高密度/省電力型、一方Tall Cellはシートの数が大きく、高速型となる。実際にはShortとTallだけでなく、複数の選択肢があると思われる
実際には複数のフィン数の組み合わせ(NMOS/PMOSでそれぞれ3/2枚、2/2枚、2/1枚となる構成)をあらかじめ用意し、これを利用して簡単に回路を構築できるようにするというものだが、NanoFlexはフィンの数ではなくナノシートの数を増減させて同じことが可能になるようにしている。
実際にN3EおよびN2プロセスを利用し、Cortex-A715コアを稼働させたときの性能/消費電力の比較も示された。下の画像は省電力同士、つまりN3Eなら2-1構成のもので、一方N2はShort Cellを利用したNanoFlex HDを利用したもので、ピークでは14%高速ないし35%の省電力、0.6V付近では15%高速ないし24%の省電力化が実現できたとする。
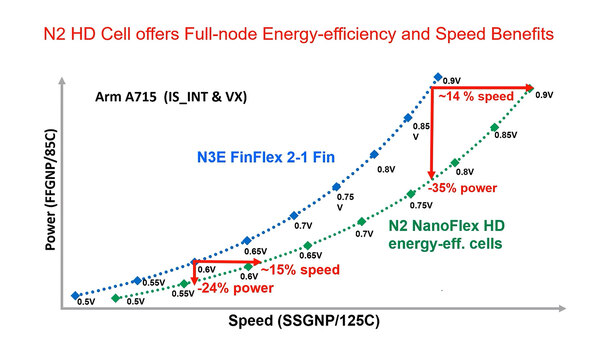
省電力ということもあり、電圧の範囲は0.5V~0.9Vまでとなっている
一方高速同士、つまりN3EがFinFlex 3-2、N2がTall Cellを使ったNanoFlex HPの場合の比較が下の画像だ。動作周波数の向上は12%ないし12.5%とやや小さめだが、その代わり38%ないし30%と省電力同士の場合よりも電力削減効果が大きいものとなっているとする。
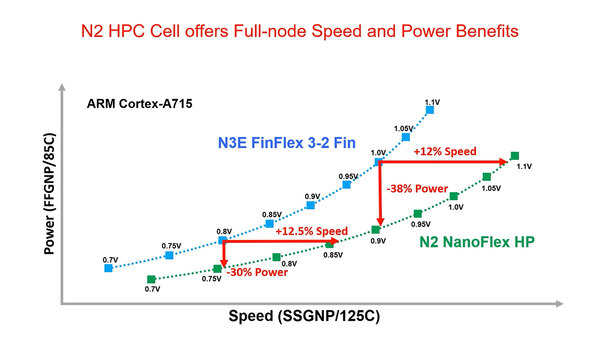
こちらは高速型なので0.7V~1.1Vとやや電圧が高めになっている。省電力効果が大きいのは、この電圧が高めな部分も関係しているのだろう
ちなみにNanoFlexはHD Short Cell/HD cell/HPC cellの大きく3種類に向けたソリューションとなっている。
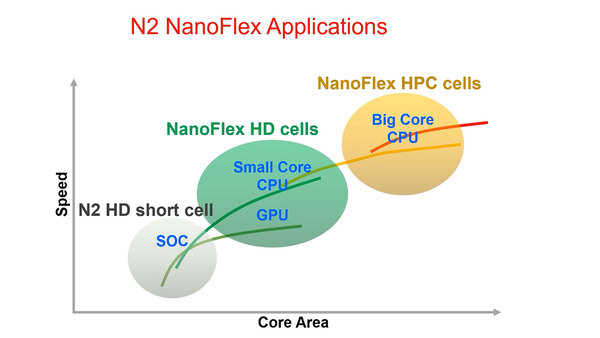
NanoFlex HDの中には、実際には2~3種類のシート構成が用意され、これを使い分けるかたちになっているものと思われる。これはHD short cell/HPC cellでも同じことだ
そのN2世代のトランジスタの基本的な特性が下にある4つの画像となる。細かくは説明しないが、既存のN3Eと比較しても十分性能改善がなされていることが、実際のシリコンでのデータを元に示されたことは大きい。

DIBLはPMOSで30mV/V、NMOSで24mV/Vとかなり低めなのだが、ゲート長で正規化しての結果となっている。ゲート長そのものは公開されていない
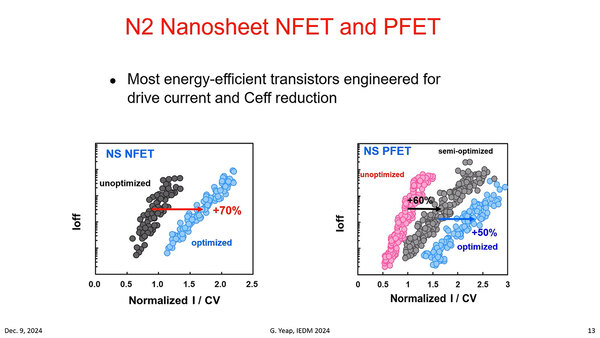
Ioff(トランジスタオフ時のリーク電流)の比較。縦軸がリーク電流、横軸がレイテンシーの逆数である。傾向としてはグラフが右にずれればずれるほど、リークが少ないことになる。PMOSのSemi-optimizedというのがどういう状況なのが気になるところ
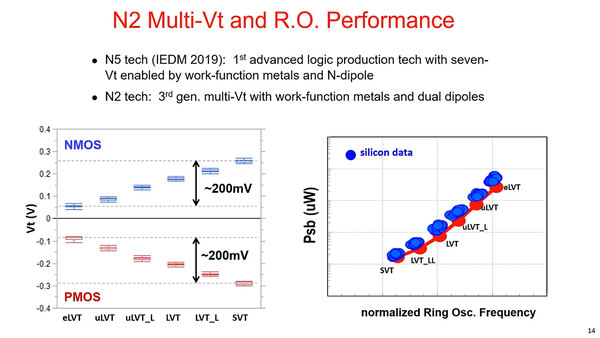
複数電圧での動作。右グラフはRing Oscillatorを構成して、動作周波数(横軸)と消費電力(縦軸)をプロットしたもの。赤がシミュレーション、青が実際のデータとのこと
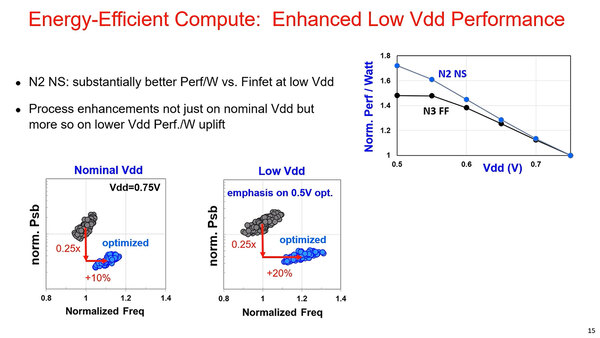
低電圧時の振る舞い。N3と比較して、0.5V付近ではさらに効率が改善するとしている
興味深いのSRAMである。何度か書いたが、トランジスタの微細化が進んでもSRAMの密度が上がらない、というのが目下の問題である。これはトランジスタそのものの大きさより配線の方がむしろ阻害要因になっているからだが、それでも2nmでは38.1Mbit/mm2まで密度を上げられたとしている。
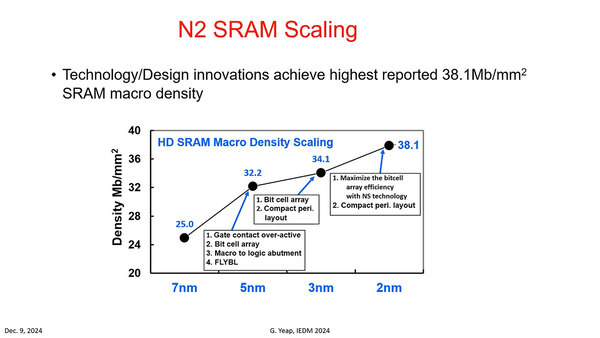
とはいえN3からでは34.1Mb→38.1Mbで11%程の増加でしかないのだが。トランジスタ数そのものは15%増なので、やはり配線がネックではある
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























