




Ru配線にAGを併用すると配線遅延を大幅に改善できる
下の画像はそのRu配線で、配線ピッチとアスペクト比を変えながらいろいろ試作した結果である。アスペクト比を4まで引き上げると、どんどん配線領域の面積が増大し、これにともない配線抵抗が下がっているのがわかる。

左が測定結果、右が試作した配線の断面のTEM写真である。一番上が20nmピッチでアスペクト比が2、中央が25nmピッチでアスペクト比2、一番下が20nmピッチでアスペクト比4となる
そのRuの最適化の効果を検討したのが下の画像である、Thin Filmとあるように、これはまだパターニング(配線構成)の前段階、まだエッチングを行なわず全面Ruの膜が覆っている段階での比較である。ここでは接着層やRuの蒸着条件、および蒸着後の主要な処理などについて4種類の最適化技法を行ない、その結果を比較したものである。
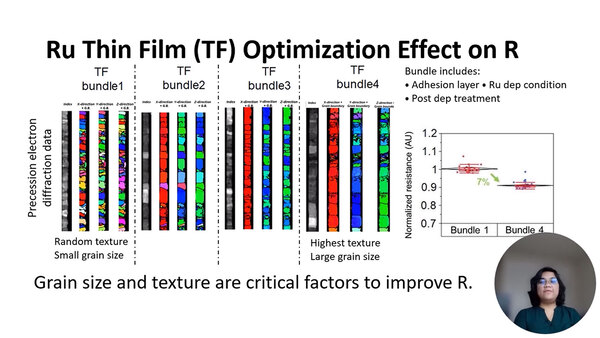
Ru最適化の検討結果。Bundle 1~4の写真に示されるナノスケールの結晶粒の評価には、精密電子回折法を使用したとのこと
Bundle 1とBundle 4で比較すると、Bundle 4の方が配線抵抗が7%ほど減少したとしている。では大きめの結晶になるといいのか? というとそういうわけでもないようで、実際にはOptimization Package 3が一番性能が良く、16%の抵抗削減が実現できたそうだ。
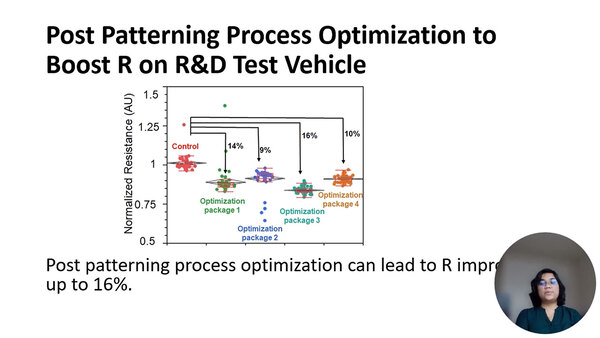
実際に量産に移るにあたっては、もう少し細かく分析をして本当の意味で最適なパラメーターを導き出すことになるのだろうが、当然どんなパラメーターでこれを実現したのか、という話は論文にも記されていない
次がAGの効果を示すパラメーターである。要するに誘電体の中にAGを構築するにあたり、どの程度のAGだと効果的か、を示すものだ。横軸は溝の高さそのものである。結果から言えば、部分的にAGを入れるだけでも25%程度寄生容量を減らせ、100%のAGを構成できればさらに効果が高まる可能性がある、としている。

中央のグラフで、例えば比率が0.1というのは、溝の底に10%の高さのAGがあり、残りは全部誘電体で埋められているというもの。1.0は全体が誘電体ではなくAGで構成されていることを示す。ちなみにこれは実験結果を元にシミュレーションした結果とのこと
下の画像は実際にAGあり/なしでRuベースの配線層を構築したもので、配線ピッチ25nmでも間の溝にAGが構成できることを示している。

この写真は論文にはないもの。まだAGの形状やRuの配線の断面形状などに結構ばらつきがあるあたりは、量産までにはまだ道のりが長そうな予感がする
下の画像、は実際にサブトラクティブで形成したRu配線層とその上層の配線層との接続されている様子と、さらに信号の劣化を比較したものである。少なくともこのレベルで言えば、VIAとの接続による信号の劣化などは確認できず、通常のCu配線の場合と明示的な差はない、という結論になったとする。

上層の配線層の材料は明示されていないが、おそらくCuベースと思われる。VIAは色から見てこれもCuで、M0~M3あたりで使われるTa(タングステン)ではない模様。あくまでもテスト用なので問題はないだろう
また配線層の構成にあたっては、VIAのPunch-throughという現象を防ぐ必要がある。これは垂直方向の貫通VIAがAGを「突き抜けてしまう」ことだ。

記事冒頭の画像右側の写真がこれ。VIAが正しくRu配線につながっている(一番左のVIA)ものもあるが、あとの5本のVIAは全部変な場所になっている。ただそうした場合でもAGが潰れたり、誘電体をVIAが突き抜けたりしていないことが確認できたとする
従来はこれを防ぐため、隣接する次のVIAにAGが構成されないように、余分なパターニング作業が必要になっていた。ところが今回意図的にVIAを本来の位置とずらして構成したところ、確かにVIAは変な位置に構築されたが、それがAGを壊したり突き抜けたりしていなかった。要するにAGを利用するための余分なパターニング作業を省けることが確認できた、としている。
結論としては、Ruを利用することでより微細化した配線層を現状のプロセスの延長で製造可能であり、配線抵抗を大幅に減らせるほか、AGを併用することで寄生容量も減らせ、結果として配線遅延の問題を大幅に改善でき、今後のトランジスタ微細化にともなう配線密度向上にも耐えられる「可能性がある」ことが示された、とする。
問題はまだ実際に高密度配線が可能かどうかは不明なことで、次はピッチ10nm台の配線層構築などを実際に行なってその特性を調べる必要がある。また(これはCoも同じだが)Ruは熱伝導率が低いことや、貴金属ということでコストが高いこと、あと変わったところでは他元素と混ざりやすく、リサイクルが大変といった問題もある。こうした問題を解決しつつ、実際に製品に採用されるようになるのは、これも早くて2030年代以降だろうと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































