




チャネル長6nmのRibbon FETが優位
それ以上でも以下でもダメ
次はShort Channelに関する検討である。Short Channel、日本語では短チャネル効果などというが、チャネルを短くするといろいろ不都合が生じることが知られている。

赤い矢印が刺さっているグレーの部分を短くすると不都合が生じる
具体的にはしきい値電圧の低下、DIBLの悪化、サブスレッショルド係数の劣化、電流非飽和、Punch Throughなどで、これは別にRibbon FETに限らずFinFETやその前のプレーナー型のトランジスタでも発生していた事柄である(個々の説明はここでは割愛する)。
では短いとなにが発生するか? という話であるが、下の画像がこれを模式図的に示したものだ。中央のSiNR(Silicon Nano Ribbon)がチャネルそのものであり、その周囲をHigh-K素子で囲い、さらにその外側に金属ゲート(MG:Metal Gate)が存在している。
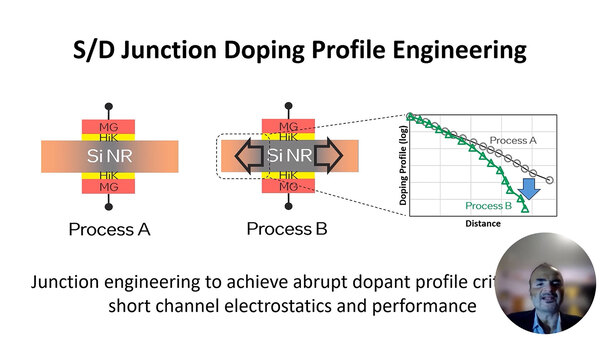
このスライドも論文には含まれていないが、わかりやすい図ではある
このチャネル、素子そのものはシリコンがベースであるのだが、そこに不純物をドーピングすることで特性を改良している。ところがゲート長が10nm以下になると、前述したShort Channelの問題に加え、チャネル内に残留ドーピング、つまりに均一にドーピングなされず、ドーピングが濃い部分が残ってしまう現象が発生。このドーピングにより、電荷移動量が低下することで性能が劣化する問題がある、としている。
ただしこれは適切なドーピングプロファイルを管理することで、チャネル長が10nm以下の場合でも性能を改善できるとしている(具体的にどう適切に管理するのか、は言及がない)。上の画像右のグラフは、なにもしない場合がProcess A、プロファイルを管理したのがProcess Bで、残留ドーピングを減らせることを示している。
具体的にゲート長が18nmと100nmの場合で比較したのが下の画像である。一番右はトランジスタの利得を比較したもので、ゲート長100mmだとProcess AとProcess Bで違いがないが、ゲート長18nmの場合、Process BはProcess Aに対し、最大で34%の利得向上が可能になっているとする。

これにより、Process Bは特にペナルティなくDIBLを削減できるとしている
中央と右はゲート長18nmの状態でDIBLの特性とRextを比較したもので、Process BはRextがほぼ変わらないにも関わらず、DIBLを-5mV/V削減できた、としている。
さて、18nmは100nmに比べれば短いとは言え、CPPを考えると十分に長い。今回の目的は表題にもあるように、ゲート長を6nmとしたRibbon FETの構築である。その成果が下の画像である。
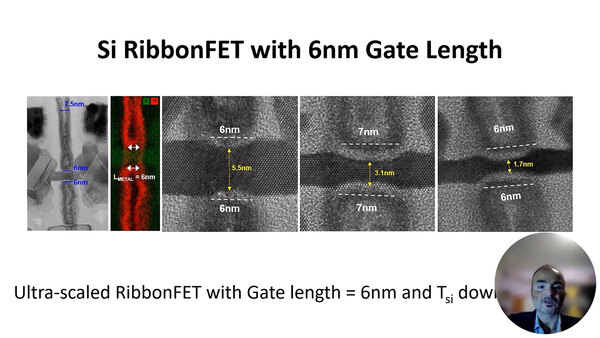
ゲート長を6nmとしたRibbon FETの構築。EDXは元素別に色分けした形で撮影できる。緑がSi、赤がHfを示す
左端はゲート長6nm、フィン厚み5.5nmのトランジスタのTEM(Transmission Electron Microscope:透過型電子顕微鏡)写真と、そのゲート周辺のEDX(Energy Dispersive X-ray:元素マッピングX線)写真である。説明によれば、ゲートのパターニング/エッチング工程を慎重に最適化したことで、均一なゲート長を持つプロファイルが得られた、としている。
その右にあるのが、ゲート長6nm/フィン厚み5.5nm、ゲート長7nm/フィン厚み3.1nm、ゲート長6nm/フィン厚み1.7nmという、寸法を変えた3種類のRibbon FETのTEMでの写真であり、いずれもうまくRibbon FETの成型に成功している。
この3種類のRibbon FETについて、DIBLを測定したのが下の画像の左側である。論文によれば、フィンの厚みが5.5nmの特性は「予想通り」劣悪で、NMOSとPMOSの両方でDIBLが180mV/Vおよび220mV/Vという、Short Channel効果がモロに発揮された結果になっている。
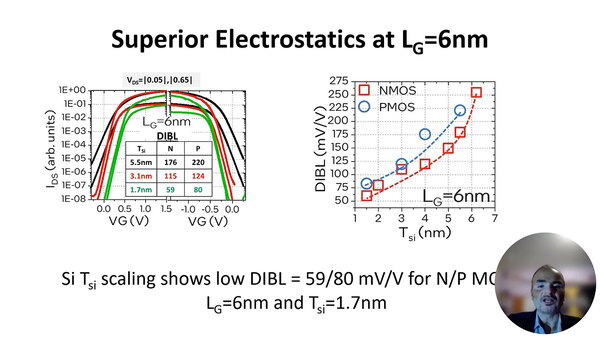
Ribbon FETのDIBL測定結果。この結果「だけ」を見れば、フィン厚みを1.5nmにするのが一番好ましい
ところがフィン厚みを3.1nmおよび1.7nmにすると、DIBLが低減されることが明確に示されている。実際1.7nmではDIBLが59mV/Vおよび80mV/Vで、5.5nmの場合のほぼ3分の1になる。3.1nmではそこまではいかないが、それでも5.5nmに比べて30~40%の低減が可能である。
この傾向を、フィンの厚みを横軸にして示したのが右側であり、NMOS/PMOSともにフィンの厚みを減らすと単調にDIBLも減っており、チャネル長が長い時にあった飽和の傾向は、このグラフからは見られないとする。
下の画像の左側はゲート長6nmの際の、フィンの厚みを変更した場合のDIBLとピークの利得をプロットしたものである。NMOSの場合は、フィンの厚みを6nm→3nmに減少させても性能へのペナルティはほとんどないが、PMOSの場合はフィンの厚みを減らすとRextが大幅に増える関係で、性能の低下が著しいとされる。

論文ではこの左側の結果について、Ribbon FETのスケーラビリティを際立たせているとまとめている。確かにFinFETの世代ではここまで厚みに敏感に特性が変わったりはしない
右側のグラフは、ゲート長6nmの場合における、フィンの厚みとスレッショルド電圧の関係をまとめた物である。そもそもゲート長が短いとしきい値電圧が増加する(=動作のための消費電力が増える)傾向にあるが、今回はWF(Work Function:仕事関数 金属内の電子を外部に放出させるために必要な最小の仕事量)を工夫することで、このしきい値の増加を上手く帳消しにできたとしており、厚み1.7nmの場合のしきい値は0V、3.1nmでは-0.1V弱と大幅に下げることに成功したとしている。
論文では最終的に、フィンの厚み5.5nmおよび3nmにおける電子注入速度が1.13x10e7cm/sになることを計測できたとしており、これはCPPが45nmのプロセスで、チャネル長6nmという短チャネルのRibbon FETが優位であることを示しているとまとめている。
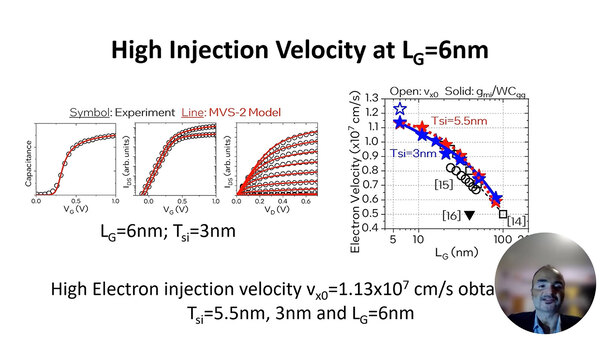
論文では計測方法についても触れているが、あまりに専門的すぎるので割愛。ちなみに5.5nmおよび3nmで同程度の電子注入速度を持つことは、先行する研究とも一致しているとしている
この論文はあくまでもフィンが1枚のトランジスタを試作し、その特性を調査したというものであって、これが量産につながるという話ではない。おそらくこれに近い特性のトランジスタが採用されるのは相当先(Intel 6A?)になるだろうし、その頃にはRibbon FETの次のCFETに移行している頃だろう。そういう遠い未来向けの基礎研究、と考えるのが妥当だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































