



ロードマップでわかる!当世プロセッサー事情 第803回
トランジスタの当面の目標は電圧を0.3V未満に抑えつつ動作効率を5倍以上に引き上げること IEDM 2024レポート
2024年12月23日 12時00分更新

12月7日~11日にかけ、サンフランシスコでIEDM(International Electron Device Meeting) 2024が開催された。今年はIEDMの開催70周年となっており、昨年にもまして多くの発表が行なわれた。
今年のテーマは"Shaping Tomorrow's Semiconductor Technology"となっており、実際次世代向けのプロセスに関する話題が多く発表されている。
IEDMのトップページ。「明日の半導体技術を磨く」のだそうだ
TSMCもN2プロセスの詳細やその次の世代向けのCFET(Complementary FET:後述)の試作などを発表しているし、ほかにもimecをはじめ各社がいろいろな成果を公開している。これを全部説明していると1年くらいかかるので、いくつかを紹介するにとどめたいわけだが、幸いにもインテルがIEDMの直前にプレビューを公開しており、こちらの記事で概略が紹介されている。
2005年まではプロセス微細化による高性能化が続く
プレビューはプレビューでしかないので、いくつか選んでもう少し詳細に説明しよう。今回のテーマは、下の画像の左側上から2番目、"Transistor Scaling Innovations"という招待講演だ。ちなみに正式タイトルは28-1 "The Incredible Shrinking Transistor - Shattering Perceived Barriers and Forging Ahead"である。

左上の2つが招待講演。残りの7つが論文となるが、うち右下の2つはほかの機関/大学との共同論文だ
まずはムーアの法則がなんだかんだと言いながらまだ成立し続けていることに触れ、引き続きムーアの法則が業界の牽引力になっているとしたうえで、話を2005年まで、2005年~現在、今後の3つに分割した。
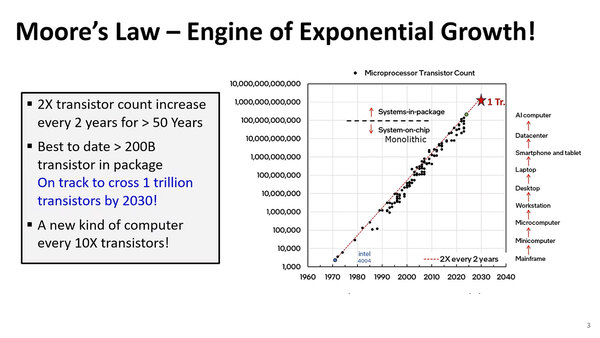
NVIDIAのBlackwellがチップ1個あたりのトランジスタ数が1040億個だから、2年で2倍だと2030年にはチップ1個あたり8320億個で、1兆個に近いところまで行く計算だが、そう素直にいくだろうか? もっともCelebrasのWSEはすでに1兆個を超えている(WSE-3 で2.6兆個)が、あれはまた別だろう

このスライドでは2003~2012年になっているが、これは90nm世代でインテルが歪シリコン、HKMG(High-K Metal Gate)、FinFETなどを最初に投入したのがこの時代に集中しているからである
2005年までというのは黄金時代、あるいはフリーランチの時代などとも呼ばれているが、要するにこの時代はプロセスを微細化すると、動作周波数が上がり、トランジスタ密度も上がるのに、電圧が下がるお陰で消費電力が変わらないというものであった。
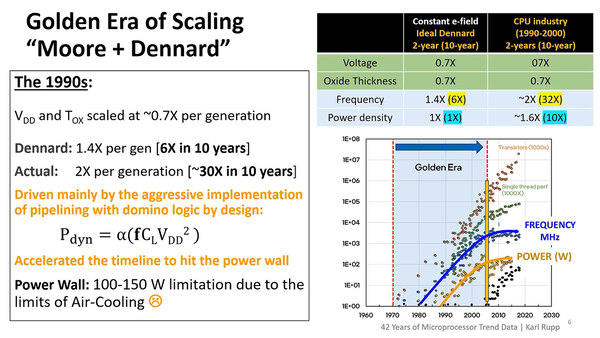
デナード則は世代ごとに1.4倍の速度向上だったが、実際にはより高性能を求めて世代ごとに2倍の速度向上を実現してしまい、その結果として早めに黄金時代が終焉を迎えたという気もしなくはない。もっとも1.4倍のまま留めても、2010年まで持ったかどうかは怪しいが
これはデナード則と呼ばれるもので、1974年にIBMのRobert H. Dennard博士が提唱した経験則である。正確に言えば、プロセスを1世代進めると、トランジスタの寸法が30%(面積で言えばほぼ半分に)縮まることで、利用できるトランジスタの数が2倍になる。
一方駆動電圧も0.7倍になり、消費電力は半分になる(駆動電圧の2乗に比例するので)。しかも寸法が0.7倍ということは遅延も0.7倍になるので、動作周波数で言えば1.4倍高速に動かせるという、夢のような話である。
実際のところ、上の画像の右図にあるように、1970年代から2004年頃まではこの夢のようなプロセス微細化による高性能化が続いた。これに歯止めがかかったのは、直接的には微細化にともなうリーク電流の急増である。ただこのあと以下のように、デナード則が崩壊することになった。
- 寸法の微細化が思うように進まない
- 微細化しても遅延がそんなに減らない
- 駆動電圧をそれほど下げられなくなった
- 消費電力はなにもしないとむしろ増える
上の画像で2005年あたりを境に、動作周波数がさっぱり上がらなくなり、またPowerも100W超で頭打ちになったのは、左の下にあるように空冷で許容できる消費電力は100~150W程度であり、この消費電力の枠の中でもう動作周波数が上がらなくなったという実情である。
特に駆動電圧が下げられないことが、消費電力を下げるうえで一番大きな障害になっているとする。

サブスレッショルド領域と呼ばれる、ある一定のしきい値以下の電圧でのトランジスタの動作の振る舞いが、通常領域と異なるのが問題。具体的に言うと、遅くなる
※お詫びと訂正:記事初出時、NVIDIAのBlackwellのトランジスタ数に誤りがありました。記事を訂正してお詫びします。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























