




ユニコードでは複数の絵文字を結合させて
別の絵文字を表現することもある
Unicodeが一般的になって、日本語を含めて、さまざまな言語の文字を自由に使えるようになったが、「文字」を取り出す、あるいは数えるのが面倒になったのも確かだ。というのも、1つの文字が必ずしも1つのコードポイントで表現されるとは限らないからだ。
たとえば絵文字では、複数の絵文字をゼロ幅接合子(Zero Width Joiner:ZWJ、U+200D)で結合することで、別の絵文字を表現することがある。たとえば、「🐦 鳥(bird)」(U+1F426)と「🔥 火」(U+1F525)をゼロ幅接合子でつなげたものは、「🐦🔥フェニックス」(Unicode Emoji 15.1で定義)の絵文字になる。
コードだと「U+1F426」「U+200D」「U+1F525」なのだが、表示上は1つの文字に見える。なお、こうした組み合わせは、ユニコード仕様書で定められ、誰かが勝手に作っているわけではない。
漢字の場合には、異字体がある。こちらはコードポイントの後ろに「異字体セレクタ」が付く。簡単に言えば、ユニコードは32bitのコードポイントを使うが、人間が認識する文字である「書記素クラスタ」(grapheme cluster)は、複数のコードポイントから構成されることがある。文字列から、書記素クラスタを認識して境界を決定する処理を「テキスト・セグメンテーション」という。
これは人間が見たときに「1文字」に見えるようなコードポイントのつながりを認識して、切れ目を見つけるのが「テキスト・セグメンテーション」である。ユニコードの処理では、分割された1文字(人の目に見える1文字)を「書記素」(grapheme)と表現することがある。
テキスト・セグメンテーションに関しては、ユニコードでは「Unicode Standard Annex #29 (UAX#29) Unicode Text Segmentation」(https://unicode.org/reports/tr29/)に定義がある。
PowerShellなどで、文字列を正しく分割するには、.NETの「StringInfoクラス(System.Globalization)」(https://learn.microsoft.com/ja-jp/dotnet/api/system.globalization.stringinfo?view=net-8.0)を使うのが簡単だ。
まずは、文字(書記素)の先頭位置を求める。PowerShellでは、内部は、リトルエンディアンのUTF16(これをWindowsではUnicodeと呼ぶ)でエンコードされている。このため、一部のコードポイントは、サロゲートペアを使って16ビット文字コード2つで表現されている。
StringInfoクラスの「ParseCombiningCharacters」メソッド(https://learn.microsoft.com/ja-jp/dotnet/api/system.globalization.stringinfo.parsecombiningcharacters?view=net-8.0#system-globalization-stringinfo-parsecombiningcharacters(system-string))は、文字列を受け取って、その書記素の先頭部分の位置を返すものだ。これを使うことで、文字の「境界」を得られる。
具体的には、PowerShellのコマンドラインで以下のようにする。
[System.Globalization.StringInfo]::ParseCombiningCharacters(<文字列>)
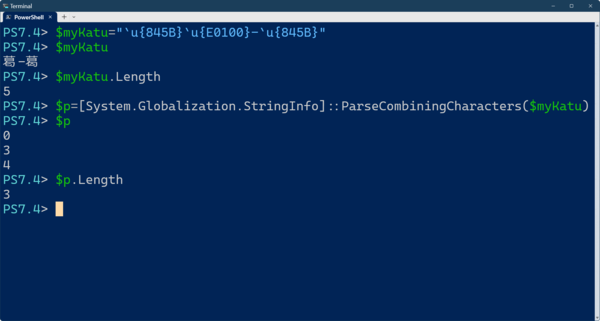
「`u{845B}`u{E0100}-`u{845B}」は、ユニコードのコードポイントによる文字定義で、具体的には、「葛󠄀-葛」という文字列になる。UTF16では、5つのワードから構成されるが、ParseCombiningCharactersメソッドを使うと、文字の切れ目は、0文字目、3文字目、4文字目となることがわかる
このメソッドは、書記素の先頭の位置を返す。たとえば、「葛󠄀-葛」という文字列は、コードポイントとしてみると、以下の図のようになっている。
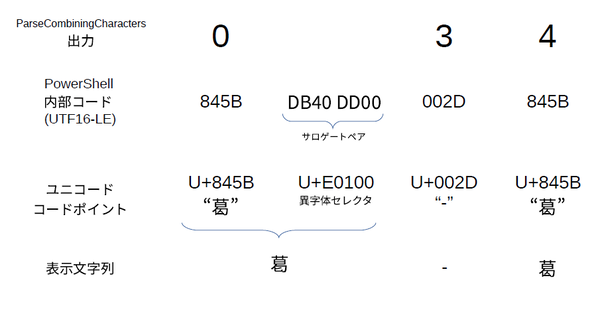
「葛󠄀-葛」という文字列は、人間には3つの文字に見えるが、ユニコードコードポイントとしては4つある。さらに異字体セレクタは、UTF16ではサロゲートペアとして表現されるため、16bitワードとしては5つになる。ParseCombiningCharactersは、書記素の先頭部分として0番目、3番目、4番目を返す。ここが文字列として扱う場合の文字の切れ目となる
この文字列に対して、ParseCombiningCharactersを実行すると、「0、3、4」という位置が返る。これは、文字の先頭が0文字目、3文字目、4文字目にあるということだ。入力が面倒そうだが、正直にキーを打つ必要はなく、先頭部分は、「“[stringinfo”+Tabキー」で、後半は「“]::p”+Tabキー」で開きカッコまで補完できる。
なお、いわゆる文字数(書記素クラスタの数)は、ParseCombiningCharactersがいくつ整数を出力しているかを数えるだけでいいので、
([System.Globalization.StringInfo]::ParseCombiningCharacters($x)).Length
で求めることができる(コマンドラインならMeasure-Objectコマンドを使うこともできる)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第521回
PC
Windowsでアプリをインストールしたときに警告が表示する「Defender SmartScreen」と「Smart App Control」 -
第520回
PC
WindowsターミナルのPreview版 v1.25では「操作」設定に専用エディタが導入 -
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")























