



ロードマップでわかる!当世プロセッサー事情 第789回
切り捨てられた部門が再始動して作り上げたAmpereOne Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月16日 12時00分更新

高密度/省電力な構成のAmpereOne
スケジューラーは192エントリーと、決して多くない。なんなら前回のOryonの方が倍以上ある。実行ユニットは全部で12とあるが、FPUが3つ、ロード/ストアーが4つなのでALUは5つ。実質的には1サイクルで4つのALU命令と、これに付随するロード/ストアー命令を1サイクルで2つ実行できる、という構成である。
FP/Vectorも同じで、3つと言いつつ1つはストアーデータだったりするので、実質2命令+2ロードといった形で、決して高性能ではない(この構成を見るとSVEのサポートはなくNeon止まりな気がする)。
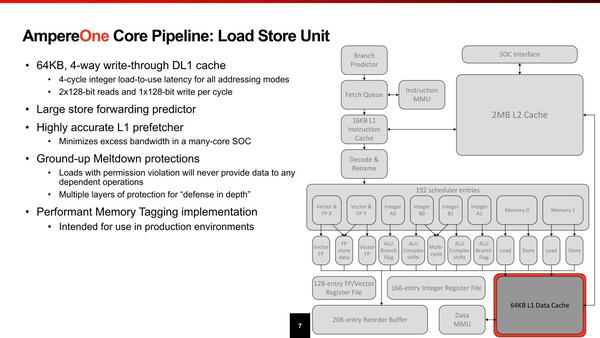
NEONユニット2つがフルに動いてもカバーできる帯域があることになる。それはともかくメルトダウン対策が当初からなされているというのもおもしろいが、これはArmのMemory Taggingを実装しているとのことだ
レジスターファイルはALUが168、Vectorが128で、これもそれほど多くない。ただALUは実質4+2命令(Vectorなら2+2命令)ということを考えるとこの程度で十分なのだろう。むしろこの規模でありながら、分岐予測を1サイクルに2つ実施できるのが目を惹く。この規模の他のプロセッサーは1サイクルあたり1つだったことを考えると、ピーク性能を高めるよりも実効性能を落とさないことに力点が置かれているように感じる。
ロード/ストアーユニットは当然L1 Dキャッシュと密接に関係しているわけだが、Load-to-useは4サイクルと結構高速だし、store forward predictor(書き出したデータをプログラムの中で再び使うという処理で、メモリーまで書き出し終わるのを待って読み直すのは遅くなりすぎる、書き出しを掛けてもその値を保持していたレジスタファイルを破棄せずに再利用できるようにする仕組みだが、それを事前予測することで効率的にStore forwardを実行できるようにする)というメカニズムは初めて目にした。
TLBはそれなりに重厚ではあるが、これはサーバー向けということを考えればそれほど不思議ではないし、極端に多いわけでもない。
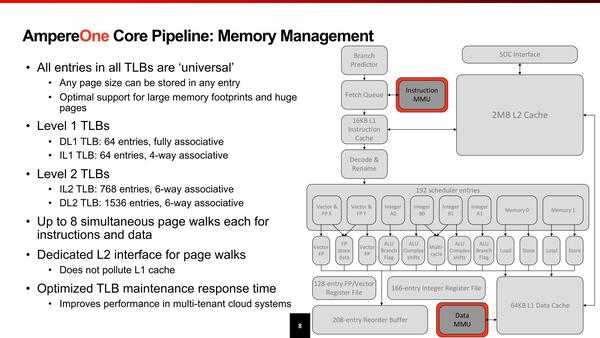
メモリー管理。これだけのPage Walkを可能にするとなると消費電力にインパクトがありそうだが、それもあってTLBのサイズは控えめなのかもしれない
おもしろいのは、TLBが任意のページサイズをサポートできる(インテルのx86では、4KB/2MB/1GBで利用できるエントリー数が違う)あたりだろうか。あと同時に8つのPage Walkを同時に発行できたり、1次キャッシュと2次キャッシュを別々にPage Walkできたりするあたりは珍しい。このあたりも、Page Walkで余分なレイテンシーが増えることを極力避けるためと思われる。
2次キャッシュはコアごとにプライベートである。消費電力増加を避けるためか、Load-to-Useは11サイクルと大きめだが、これは2次キャッシュの速度としては妥当だろう。
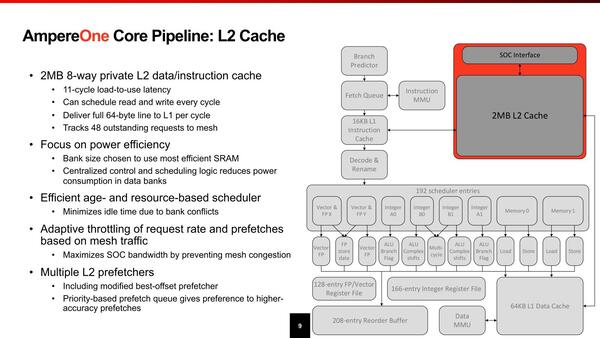
2次キャッシュは、構成も省電力最優先とあるので、おそらく高密度/省電力の構成になっているものと思われる。そのわりにレイテンシーが常識的なのは驚きである
1次キャッシュとの帯域は64Bytes/サイクルで、このあたりは最近のプロセッサーらしい速度。3次キャッシュとの関係は不明だが、後述するように3次キャッシュは全部で64MBしかなく、しかもスヌープフィルターも兼ねていることを考えるとインクルーシブ・キャッシュ構成というのは考えられず、エクスクルーシブ・キャッシュ構成と思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























