



Stable Diffusion入門 from Thailand 第19回
画像生成AI「Stable Diffusion」の代替に? 話題の「FLUX.1」を試した
2024年08月07日 17時00分更新

ComfyUIでFLUX.1 [dev]が動くのか?
それでは、ワークフローを詳しく見ていこう。
左上の3つのノードはモデルなどをメモリーにロードするローダー類だ。上から「モデル」「CLIP」「VAE」のローダーが並んでいる。
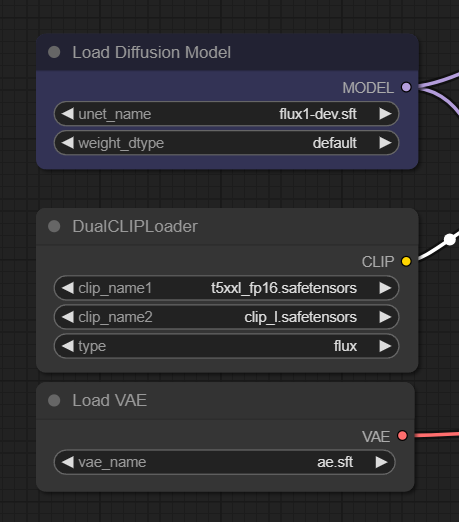
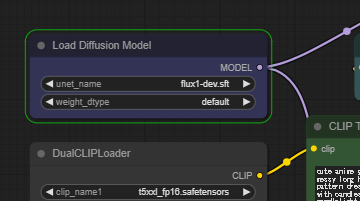
「Load Diffusion Model」ノードでは利用するモデルを指定する。ここでは「flux1-dev.sft」モデルが選択されている。
Load Diffusion Model
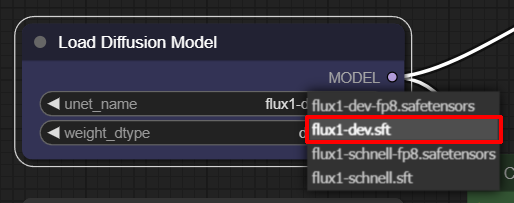
ダウンロードしたモデル類が正しいフォルダーに入っているか確認する意味でも、一度モデル名をクリックして明示的に「flux1-dev.sft」を選択しよう。
「DualCLIPLoader」ノードには利用するCLIPファイルを指定する。FLUX.1の特徴として複数のCLIPを利用するため、「t5xx_p16.satetensors」「clip_l.safetensors」の2つを明示的に指定しよう。
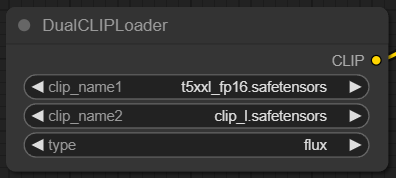
DualCLIPLoader
その右側には「BasicGuider」「FluxGuidance」「CLIP Text Encode (Positive Prompt)」の3つが並んでおり、いわゆる呪文(ポジティブプロンプト)が入力されている。
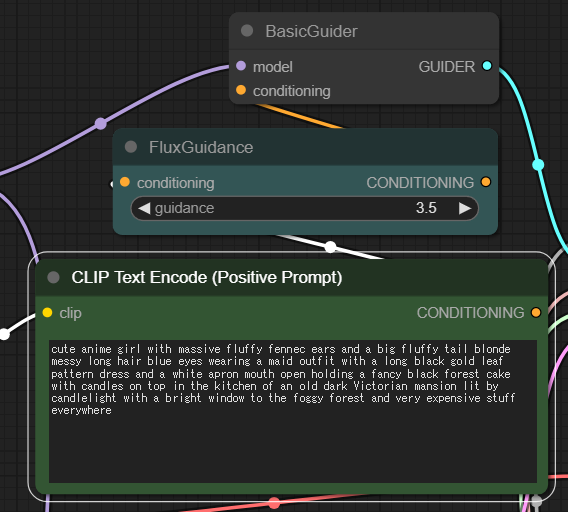
さらにその下には「EmptySD3Latentlmage」「RandomNoise」「KSamplerSelect」「BasicScheduler」の4つのノードが並んでいる。
「EmptySD3Latentlmage」では「width(幅)」「height(高さ)」「batch_size(生成枚数)」を指定できる。ここでは「3:2」の横長画像になるよう「1024 x 768」に変更している。
「RandomNoise」では「noise_seed(シード値)」と「control after generate(生成後の挙動)」を指定できる。特に指定がない場合は前者はそのまま、後者は「randomize」を選択しておこう。逆に設定やプロンプトの微調整などをしたい場合は同じシード値を入力し、「fixed」を選択すればよい。
「KSamplerSelect」ではサンプラーをセレクト、ここでは「euler」を選択。
「BasicScheduler」では、画像を生成する際に行う反復処理の回数「steps(ステップ数)」が大切だ。ステップ数が多いほど通常は画質が向上するが、同時に生成時間も増加する。とりあえずデフォルトの「20」にしておこう。
これで準備は完了、コントロールパネルにある「Queue Prompt」をクリックで生成開始だ。
ComfyUIは、現在処理中のノードに緑枠が付くことで現在どの処理をしているかがわかる。「Queue Prompt」を押してからしばらくはこのままだ。これは23.8GBもあるモデルをメモリーにロードしているためと思われる。
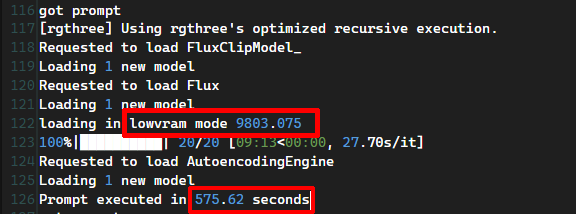
だがそもそも、筆者の「RTX4070/12GB」で120億パラメーターの巨大なFluxが動くかどうかはかなり微妙なところだ。とはいえ、ログを見るとエラーは吐いていない。
詳しく見ていくと、「loading in lowvram mode 9803.075」という記述がある。どうやらこれは「低VRAM」モードであり「9803.075」という数字は「約9.8GB」を表している。つまり、本来は16GB程度は必要なVRAMを9.8GBで済ますことができるようなのだ。
ということで、なんとか動いたものの生成速度はとても遅く、20ステップでおよそ575秒(9分35秒)かかってしまった。
生成されたのはこちら。デモの画像と細部が多少異なるが、これはアスペクト比を変えたせいだろう。クオリティはまずまずだ。

FLUX.1 [dev]
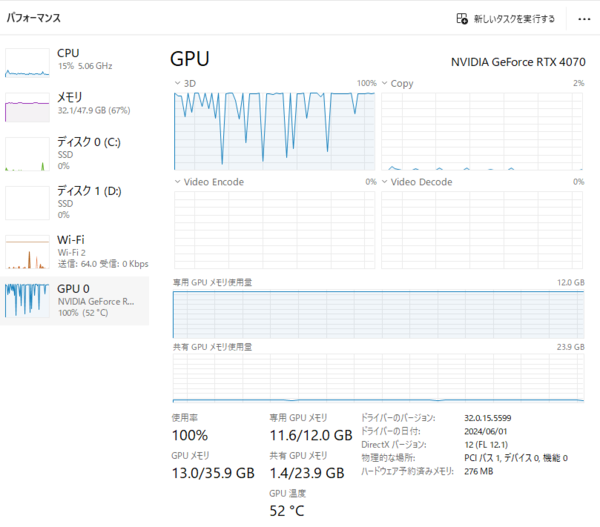
とはいえ、タスクマネージャーでパフォーマンスを見るとGPUはフル稼働、GPUメモリー11.6GBに加え、共有GPUメモリーで不足分を補っているようだ。CUDAのメモリー管理すげえ。
パフォーマンス
次に、こちらでもProと同様に、本連載の過去記事「人気の画像生成AI、違いは? Stable Diffusion XL、Midjourney、DALL-E、Playgroundの画風を比較する」で使用した下記プロンプトを使って生成してみよう。
プロンプト:A photorealistic portrait of a young woman with dyed pastel pink hair and subtle makeup, wearing trendy streetwear, standing in a bustling urban crossing with neon signs in the background
[pro]と比べると多少落ちるが、それでもかなり満足のいく画像が生成された。
だがやはり生成には時間がかかる。プロンプトや設定にもよるだろうが、こちらはとうとう実時間10分を越えてしまった。実際は動くだけでもすごいのだが、もう少し早く生成できないものだろうか。

FLUX.1 [dev]
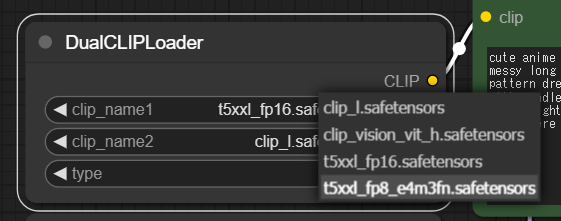
そこで、CLIPを「t5xxxl_fp16.safetensors」から「t5xxl_fp8_e4m3fn.safetensors」に変更してみよう。
DualCLIPLoader
353.57秒(5分53秒)と、多少短縮された。
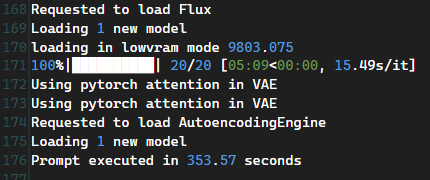
生成物のクオリティーもそこまで落ちていないようなので、こちらの設定でいこうと思う。

FLUX.1 [dev](CLIPのみfp8)
さて、ここまで来て残念な事実が発覚。画像生成速度が遅いのはアスペクト比を変更したためだった。デフォルトの「1024 x 1024」に戻すと……。
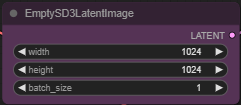
EmptySD3Latentlmage
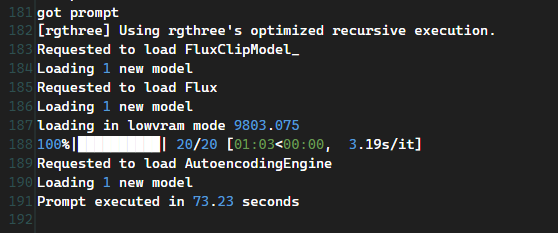
20ステップにも関わらず、なんと驚きの73.23秒(1分13秒)。これならぜんぜん許容範囲である。
生成画像も特に劣化した様子はない。うう……これまでの苦労はなんだったのだ。

この連載の記事
-
第40回
AI
Suno級がローカルで? 音楽生成AI「ACE-Step 1.5」を本気で検証 -
第39回
AI
欲しい映像素材が簡単に作れる! グーグル動画生成AI「Veo 3.1」の使い方 -
第38回
AI
最新の画像生成AIは“編集”がすごい! Nano Banana、Adobe、Canva、ローカルAIの違いを比べた -
第37回
AI
画像生成AIで比較!ChatGPT、Gemini、Grokどれを選ぶ?得意分野と使い分け【作例大量・2025年最新版】 -
第36回
AI
【無料で軽くて高品質】画像生成AI「Z-Image Turbo」が話題。SDXLとの違いは? -
第35回
AI
ここがヤバい!「Nano Banana Pro」画像編集AIのステージを引き上げた6つの進化点 -
第34回
AI
無料で始める画像生成AI 人気モデルとツールまとめ【2025年11月最新版】 -
第33回
AI
初心者でも簡単!「Sora 2」で“プロ級動画”を作るコツ -
第32回
AI
【無料】動画生成AI「Wan2.2」の使い方 ComfyUI設定、簡単インストール方法まとめ -
第31回
AI
“残念じゃない美少女イラスト”ができた! お絵描きAIツール4選【アニメ絵にも対応】 -
第30回
AI
画像生成AI「Midjourney」動画生成のやり方は超簡単! - この連載の一覧へ




とは")


















の1台が今ならオトク!")
























")

