



AWSによる自治体・教育・医療分野の生成AI活用ユースケース
大阪市、Amazon Kendraを用いて生成AIのハルシネーション対策を検証
2023年11月07日 10時00分更新

アマゾン ウェブ サービス ジャパンは、2023年11月2日、公共領域における生成AIの活用に関するメディア勉強会を開催。
アマゾン ウェブ サービス ジャパンの執行役員 パブリックセクター技術統括本部長である瀧澤与一氏は、公共領域における生成AIの典型的なユースケースとして、「国民/市民のユーザー体験の強化」「職員の生産性と創造性の向上」「業務プロセスの最適化」の3つを挙げる。

アマゾン ウェブ サービス ジャパン 執行役員 パブリックセクター技術統括本部長 瀧澤与一氏
勉強会では、同社に寄せられている生成AI活用の相談の中から、「職員の生産性と創造性の向上」を中心とした、自治体・教育・医療分野におけるユースケースが紹介された。
大阪市はハルシネーション対策となるRAGをKendraで実現
まずは、自治体における職員の生産性向上の事例として、2023年の9月に連携協定を締結した、大阪市の取り組みが紹介された。大阪市はAWSと共同で、業務効率化や作業の負荷軽減、業務品質の向上に向けて、生成AI活用の検証を進めている。
検証の主な内容は、大規模語モデル(LLM)が、不正確な回答を吐き出すいわゆるハルシネーションであったり、「わからない」という回答を発生させずに、いかに効率性を向上できるかというものだ。「たとえばチャットボットを構築したとして、間違いが発生すると、もう一度調べる手間が発生する。これでは効率性が上がらないため、できるだけ正確なデータを返す必要がある」と瀧澤氏は説明する。
そこで、大阪市と取り組んでいるのは、LLMが持つ知識を補うために、学習データ以外の外部の知識ベースにアクセス・検索できるようにして、回答の質を向上させる、RAG(Retrieval-Augmented Generation:検索拡張生成)という手法を用いた解決方法だ。

大阪市との共同検証の概要とRAGのアーキテクチャー
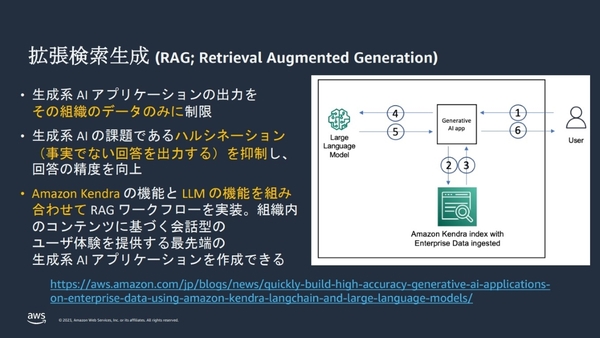
AWSのサービスを用いたRAGワークフローの実装
RAGのアーキテクチャーとしては、対話型のアプリケーションが構築し、大阪市の庁舎の端末から質問を投げると、サーバーレスでコードを実行する「AWS Lambda」が質問を受け取る。Lambdaは、言語に応じて「Amazon Translate」で翻訳しつつ、生成AIにリクエストを流すのだが、その前に該当する文章の検索と抜粋文の取得を、「Amazon Kendra」に問い合わせる。
Amazon Kendraは、機械学習を利用した文書検索のためのエンタープライズ検索サービスであり、組織内の情報をあらかじめ処理した上で、情報を検索することができる。大阪市との取り組みにおいては、Kendraが定期的に大阪市のウェブサイトや行政文章などをインデックス化しており、Lambdaからのリクエストを受け、質問に対応する文章を検索。Kendraが抽出した文章を、生成AIのエンドポイントであるAmazon SagemakerやAmazon Bedrockが要約して、回答として端末に返すという仕組みとなっている。

械学習を利用した高精度な文書検索を提供するAmazon Kendra
Kendraを通して、行政文書そのものから情報を取得し、それを要約する形となるためハルシネーションは起こりにくく、対象の文章がなければ「ない」という回答が要約されるため、大阪市が保有する情報に基づいた精度の高い回答を得ることができる。
「この大阪市の取り組みは典型的な例で、同様の需要は多い。たとえば、組織内でノウハウやマニュアルを探すというユースケースにおいて、ハルシネーションを防ぎたい場合も、RAGの仕組みで対応できる。LLMを独自にファインチューニングしたり、自社の情報だけを学習させるという解決策もあるが、コストも時間も費やしてしまう」と瀧澤氏は言う。
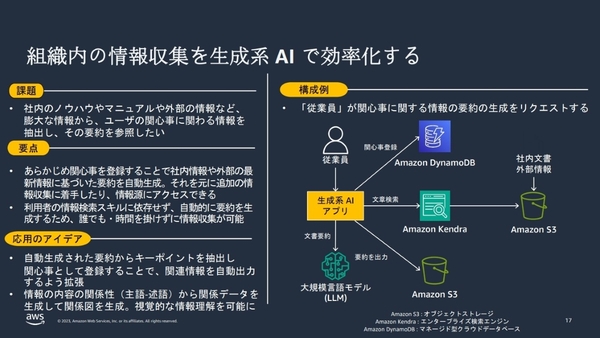
組織内の情報収集を生成AIで効率化する
また、自治体における別のユースケースとして、業務の引き継ぎサポートが挙げられた。チャットアプリが、庁内に保存されている既存のドキュメントを基に、引継ぎしきれなかった業務に関する質問に回答するといった活用方法だ。こちらも、Kendraを組み合わせることで、情報漏洩やハルシネーション対策をとりつつ、内部資料をベースとした業務効率化を、比較的容易に実装できるという。
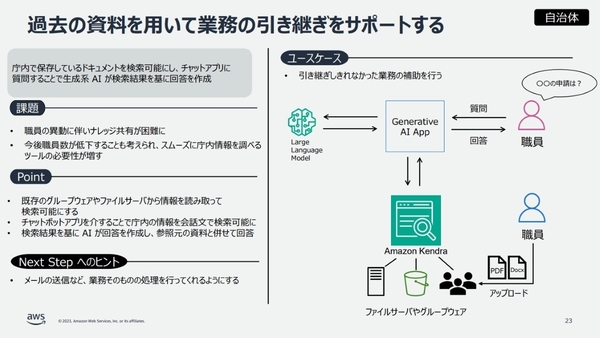
過去の資料を用いた生成AIによる業務引き継ぎのサポート
本記事はアフィリエイトプログラムによる収益を得ている場合があります



