




今回取り上げるのはTeslaのDojoである。そもそもTeslaの車と言えば電動車であることと、他社に先駆けて自動運転の仕組みを取り入れていることが特徴なのはご存じのとおり。ついでに言えばその自動運転のシステムを自社で構築していることも特徴的である。
下の画像は2019年に開催されたPytorch DevCon 2019でTeslaのAndrej Karpathy博士(Sr Director of AI:現在はTeslaから離職した模様)が示した、Teslaの自動運転に関わるスタックの様子であるが、ハードウェアとしてTeslaの車に搭載されるのは、上から2つ目の“Inference @ FSD Computer”である。

Karpathy博士の講演そのものはYoutubeで見られる
FSDは“Full Self Drive”の略で、このチップ自身もなかなか壮絶な代物で、当然Teslaの内製である。このFSDの詳細は別の機会に紹介するとして、右下に謎の“Dojo Cluster”というコンポーネントがあるのがわるだろうか?
Teslaの自動運転車の場合、走行時にその走行の様子を記録したデータ(含ビデオデータ)を、常にTesla社に送信している。Teslaはそのデータを基に、より良い自動運転のアルゴリズムを常に改良し続けている。この改良を担うのがDojoだ。
要するにFSDは自動運転のアルゴリズムを使って推論を行ない、それを基に運転操作をする。一方でその際に得られた運転データを利用して学習し、より良い自動運転アルゴリズムを開発する。この学習を行なうためのシステムがDojoである。
このDojoの詳細が公開されたのは昨年8月に開催されたHotChips 34である。実はこの時点でもまだDojoはフル稼働していない。ではDojoが完成するまでの間はどうしていたか? というと、NVIDIAのA100ベースのスーパーコンピューターを構築し、ここで学習していた。
下の画像はこのスーパーコンピューターのプレスリリースでの写真だが、A100を5760枚集積したクラスターでこの学習処理をしていた。

これもまたKarpathy博士とのZoom会議で示されたスライド。出典はCVPR'21の“Workshop on Autonomous Driving”だが、スライドの下には“(next up:Dojo)”とあるものの、Dojoの話はここでは出てこない
ただこのクラスターを利用しても、一部のアルゴリズムでは学習に1か月近くを要するものがあったらしい。Dojoの目的は、これを1日に短縮することである。つまり現在のA100ベースのクラスターよりも30倍高速なシステムを構築するというのがDojoのターゲットとなる。
さてそのDojoであるが、基本となるタイル(Compute Die+I/O Die)の構成はCelebrasのWSEを連想させる、巨大なウェハーサイズの構造である。

個々のCompute Dieの内部構造は後述。WSEと異なり、Dojoでは良品のダイのみを選別してタイルを構成する
これだけでも大概であるのだが、このウェハーサイズのタイルは、それぞれ個別にパワーデリバリーと冷却をワンパッケージにした形で構成される。

個々のタイルあたり15KWだから壮絶である。構造的には、昔のIBMのZシリーズのプロセッサーモジュールを思い出す
こんな構造になるから、当然液冷になるのだろう。ちなみにTeslaによれば、1個のタイルあたりで9PFlops(BF16/CFP8)の演算性能を実現、オンタイルメモリーは11GBのECC付きSRAMで、帯域はオンタイルメモリーのみで10TB/秒、オフタイル(つまりタイル間でのメモリー転送)を含めると平均36TB/秒とされている。
ただこのコンピュートタイルは純粋に計算をするだけの処理なので、外部とのI/Fがない。これを担うのが、Dojo Interface Processorである。
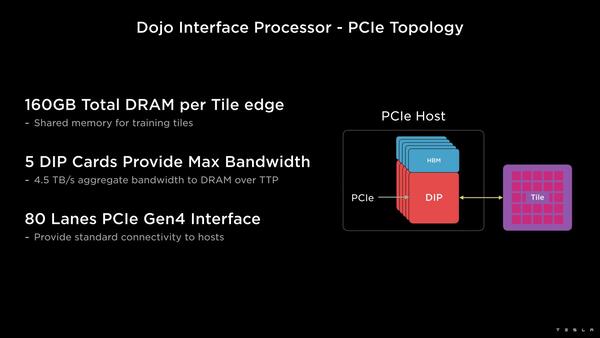
DIPはDojo Interface Processorの略。1つのコンピュートタイルにDIPカードが5枚接続される
こちらは外部の共有メモリーと、ネットワーク/ホストとのI/Fを担う格好である。1つのDIPカードにはDIPが2つ搭載され、それぞれのDIPにはHBM2が2つづつ接続されている。
このDIPの中身は明確にはなっていないが、下の写真を見る限りはArmベースのSoCでイーサネットを内蔵したチップのようだ。

HBM2は8GB積層がDIPあたり2つで16GB、トータル32GBという計算になる
外部I/FはPCIe Gen4 x16で、これがボード上のPCIe Switch経由につながり、最終的にホストに接続される構成らしい。ちなみにコンピュートタイル自身も相互接続可能になっており、それぞれ9TB/秒で接続される。
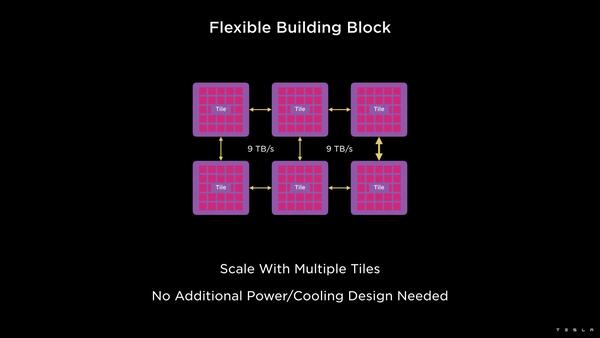
要するに各タイルには9TB/秒のリンクが4対用意され、タイル同士を接続することも、DIPカードを接続することも可能というわけだ
ここで少しおもしろいのが、コンピュートタイル同士の接続とDIP経由の接続の使い分けである。コンピュートタイル同士はけっこうな数の接続が可能であるが、規模が大きいと当然その際の通信の遅延が大きくなる。
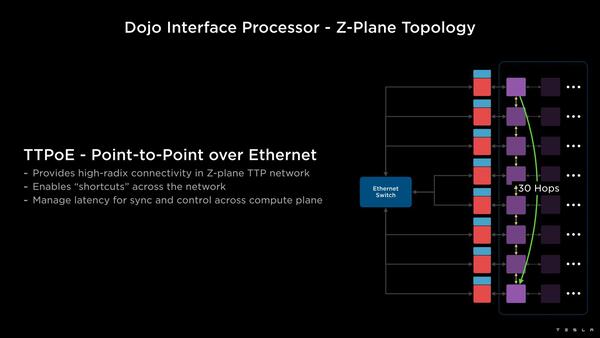
縦に30もつなぐ形になるとも思えないのだが。あとHyperCube的に、一番上と一番下のタイルをつないでしまえばHop数の最大値は半分に減る気もするのだが、そういう構成はできないらしい
その場合、DIP経由で直接Point-to-Pointで通信を行なうことで、Hop数を大幅に減らせることになる。TeslaはこれをZ-Plane Topologyと呼んでいるが、要するに相手との距離次第でコンピュートタイル同士の接続とDIP経由の接続を使いわけすることで、遅延を大幅に減らせるというわけだ。
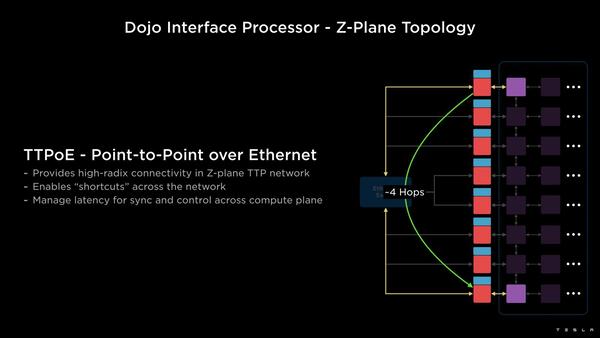
ただし帯域そのものはコンピュートリンク同士の接続より当然減るので、そのあたりの使い分け方は難しそうだ
実際のDojoのシステム全体は下の画像のとおりである。複数のコンピュートタイル同士を相互接続し、その外側にDIPが並ぶ構造だ。これを組み合わせて、1EFlopsの演算性能とオンタイルで1.3TBのSRAM、それに13TBのHBMメモリーが用意される格好になる。
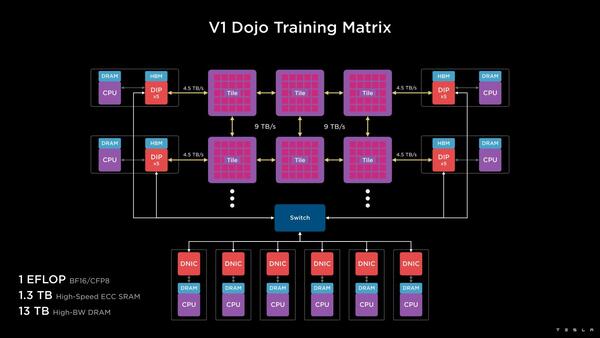
Dojoのシステム。CPU+DRAMというのはホストのCPUのことである
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































