




PEをデータフローで動作させて高効率を実現
ちなみにそのPEがどうして効率的か? と言う説明はあった。下の画像は3×3の畳み込み演算の場合だが、まず隣接する4方向との間で演算の半分を行ない、次のサイクルで残り半分の演算ができる格好になる。
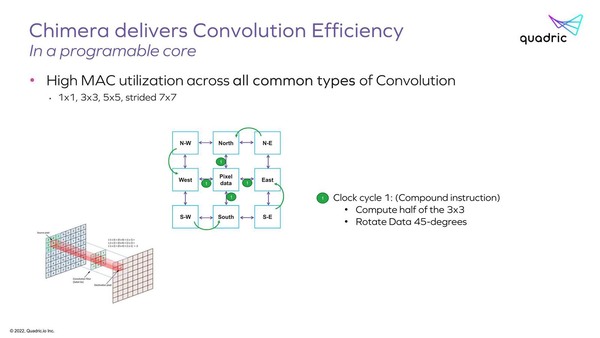
中央のPEと、その上下左右にあるPEの間で演算を行なう。一方斜め方向の4つのPEは、自分の保持するデータを隣りのPEに移動する
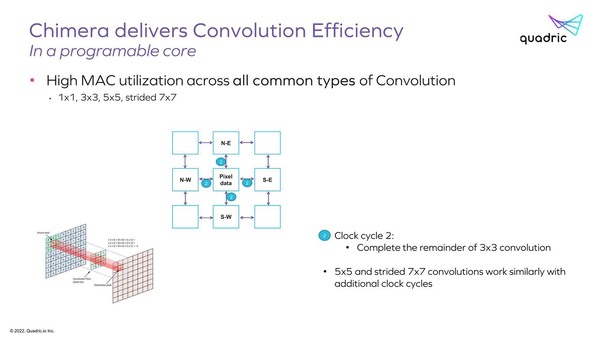
上の画像で行なった、元は斜め方向にあったデータの演算がこのサイクルで行なえる
結果、3x3の畳み込みが2サイクルで実施できるわけだ。同じ仕組みで、より大きなサイズの畳み込み演算も高効率で実現可能というのが同社の説明である。
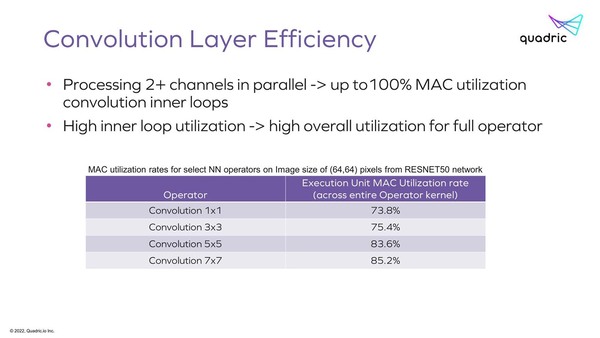
PEをデータフローで動作させるので、結果的に高効率が実現できるわけで、確かにこれを見る限りデータフローっぽい動作になっている
なお、メモリー回りで言えば、2次キャッシュを経由すると最大70倍の電力消費となるそうで、やはりDMAエンジンを経由してアクセスするのはそれなりにコスト増になるのは間違いない。
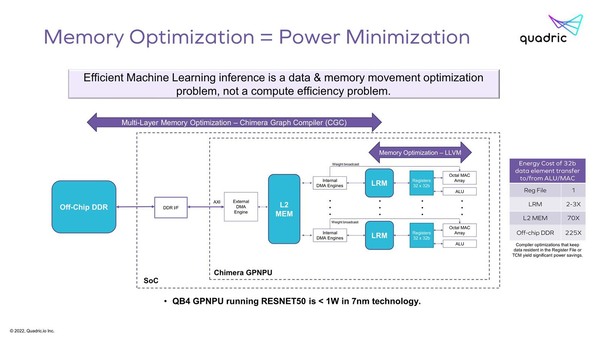
2次キャッシュを経由すると最大70倍の電力消費となる。右の数字はあくまでもデータアクセスの際の消費電力の比であって、速度の比ではないことに注意
でありながらもあえてこんな構成にしたのは、例えばすべてのLRMをファブリックでつなぐような構成にすると、そのほうが複雑さが増し、回路規模が増え消費電力が増えるという判断だったのかもしれない。
後述するQB4の構成では、RESNET-50動作時の消費電力を1W未満に抑えたというあたり、性能と消費電力、複雑さに関してのバーターとしてこの構成になった、と考えるのが妥当なのかもしれない。

QB1が64PE、QB4が256PE、QB16が1024PEという構成になっているようだ。逆に言うとScalar Elementの方は構成が同じ模様
Chimera GPNPUはこのPEの数でQB1~QB16まで3つのラインナップが用意されている。すでにQB4構成に関しての試作チップは存在しており、ラスベガスで開催されるCES 2023に合わせて来年1月5日と1月6日にブースでデモを行なうとしている。

2つ上の画像では7nmで1W未満という説明だったが、この試作チップはTSMCの16FFCの製造とされており、7nmの方は推定値なのかもしれない
また同社は製品だけでなくIPライセンスの形での提供も考えているそうだ。この試作チップはM.2の2280サイズに収まっており、いわゆるエッジ向けAI推論プロセッサーと同じ感じになっている。
この製品版の方は2023年第1四半期中に準備が整うようで、仮にここから量産を始めると第2四半期あたりに最初の量産チップが出てくる格好だろうか。すでにSDKの提供はスタートしており、またLLVM C++コンパイラおよび命令セットシミュレーターも限定的にだが提供を開始しているようだ。

この量産チップのプロセスは未公表。7nmあたりに思えるが、このあたりは価格とのご相談の面もある
根本的なところで、ChimeraをChimeraたらしめている、Scalar ElementとMatrix Elementの謎のパイプライン構造の意味はわからないし、QA4構成で1GHz駆動では4TOPSというのは、性能として低くはないが高くもないという微妙なところである。
とはいえかなりおもしろいプロセッサーではあり、果たしてどこまでマーケットが取れるのか見守りたいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























