




畳み込みの結果を精査する
「非線形関数」
さて、Feature Mapを生成してもそれで終わりではない。Feature Map生成はあくまで元画像から「特徴を抽出」するだけである。その結果として、抽出したFeature Mapが「次のニューロンに伝達するほど明確に特徴が出ているか」を判断させるのが、次の非線形関数である。
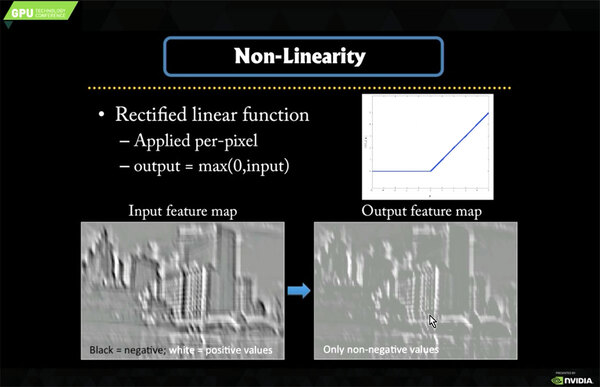
非線形関数。入力が0なら0、0以上ならそのまま入力値を返せばいいので、ハードウェア的にも非常に容易で、GPUへの実装も楽だった
先も書いたように「発火」をつかさどる部分である。もともとは、シグモイド関数と呼ばれるものを使っていた。シグモイド関数は下図に示すようなもので、ちょうど入力値xが0のあたりが一番大きく変化する性質を持っている。これが一番、もともとのニューロンの発火の仕組みに近い、ということで採用されたものである。
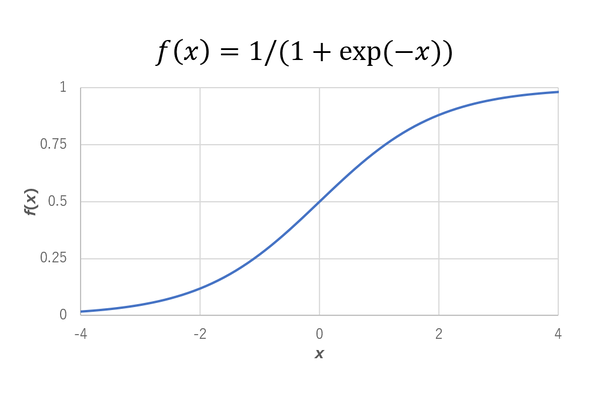
シグモイド関数
ただ計算する側にとっては厄介である。なによりexp(-x)という関数の計算には結構時間がかかるからだ。まじめに計算しようとするとテイラー展開(これは確か高校で勉強した記憶がある、と書いたら編集氏より大学じゃないんですか?と突っ込みが入った。そうかもしれない)を使うことになる。
下図がそのテイラー展開であるが、除算が入るうえにどこまで計算するか(定義上は無限に続くが、そんなにやってられないので、適当なところで切り上げる)で処理量が大きく変わる。
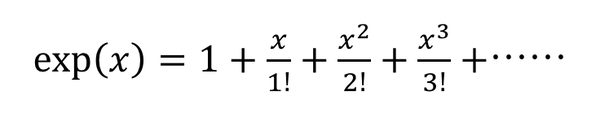
無理数の近似値を手計算で求められるテイラー展開
除算が問題なのは、そもそも除算のコストが非常に大きいためだ。連載185回で、Pentiumのバグに絡んで除算の方法を説明したが、加減算や乗算に比べて、除算はやるべきことが非常に多い。
例えば“Intel 64 and IA-32 Architectures Optimization Reference Manual”で命令のスループットとレイテンシーを確認すると、汎用命令つまりMMXでもSSEでもAVXでもないx86命令の場合、以下のようになっている(CPUアーキテクチャーによってスループットやレイテンシーは変化する)。
| 汎用命令 | ||||||
|---|---|---|---|---|---|---|
| ADD/SUB(加減算) | スループットは0.25~0.33サイクル/命令、レイテンシーは1サイクル | |||||
| MUL/IMUL(乗算) | スループットは1サイクル/命令、レイテンシーは3~5サイクル | |||||
| DIV/IDIV(除算) | スループット未掲載、レイテンシーは19~26サイクル | |||||
ADD/SUBでスループットが0.25~0.33サイクル/命令というのは、1サイクルで3回ないし4回の演算が可能という話で、乗算は1サイクルあたり1回。
そして除算はスループットなし、というのはパイプライン化されていないという話であって、1回除算を始めたら、それが終わるまで次の除算を開始できない。
そしてレイテンシーは19~26サイクルなので、ざっくり言えば除算は加減算の100倍遅いことになる。したがって、テイラー展開の2!や3!の除算はできる限り避けたい。しかも、シグモイド関数そのものが除算を必要とするから、輪をかけて遅くなるわけだ。
入力値が整数8bitであればテーブル参照という手もなくはないのだろうが、精度を上げるために内部を浮動小数点演算にしていると、テーブル参照にしても大ごとになる。
ところが2012年のAlexNetでは、ここにシグモイド関数を使わなくても、前述した非線形関数のようにMax Pooling(入力値と0を比較し、大きい方を返す)を使っても十分良い結果が得られるとわかったため、これでだいぶ計算負荷が減った形になる。
それもあって、このあとはシグモイド関数を使う頻度がかなり減ったようだが、最近のAI向けアクセラレーターの中にはハードウェアでシグモイド関数を実装しているものがいくつかあるあたり、まだ精度を重視する用途で使われている模様だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























