




実行ユニット数は7つ
SandyBridge程度の性能を省電力で実現
さて次はBack End。まずはInteger Unit側である。先ほども書いた通りユニット数は7つで、ALU×3、AGU×2、分岐×1、Store Data×1という構成だ。相変わらずAGU(つまりLoad Data)とStore Dataを別々のユニットとするのは、もはやインテルの伝統かもしれない。

従来のCore系は、Branch UnitをALUとポート共有の形にしており、これを分離しているのが興味深い
Issue Portは6つで、2つのAGUは1つのRSで共用となるのは理屈にかなっているとは思う。この7つの実行ユニットという構成は、世代的に言えばSandyBridgeとHaswellの中間くらいに位置する。
IvyBridgeがALU×3+AGPU×2+Store Data×1、HaswellがALU×4+AGPU×3+Store Data×1になっており、性能的にはSandyBridgeあたりに近い程度である。
ただSandyBridgeに比べて分岐ユニットが別になっているほか、SandyBridge/HaswellともにALUとFPUが同一のポートを利用していたのに対し、TremontではFPUは別のIssue Portを使う形になっており、よりすっきりした効率の良さそうな構成になっている。
逆に言うと、この構成のままではx86換算で平均3命令/サイクル以上は望めそうにない。もちろんうまく組み合わせればピーク性能はもう少し上がるが、平均して4命令/サイクルを狙ったHaswell以降や、5命令/サイクルを視野に入れたSunnyCoveには遠くおよばない。要するに平均してSandyBridge程度のIPCを、省電力で実現するというのが目標と思われる。
Tremontはまた、ベクトル演算にも割り切りが見られる。まずAVXに関しては実装していない。これは別にTremontだけでなくGoldmont PlusまでのAtomコアに共通の機能であるが、実際最新版のIntel 64 and IA-32 Architectures Software Developer Manualsを確認しても、SSEはサポートされているがAVX/AVX2/AVX512をサポートするプロセッサーとしてTremontが挙がっていない(Volume 1のChapter 5)。
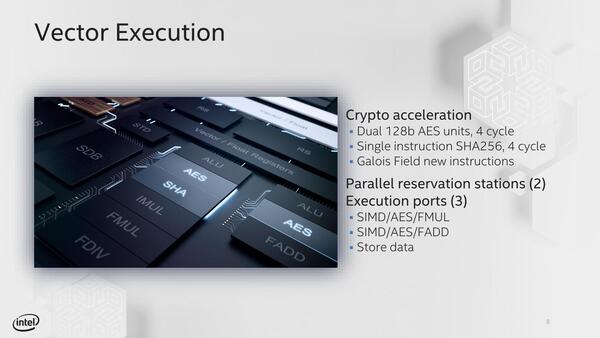
SSEはサポートするがAVXは実装しないなど、ベクトル演算にも割り切りが見られる
AVXが未実装なのは、「AVX命令を使うプログラムはSunnyCoveを利用すれば良い」という割り切りと考えられる。
その代わり、特にネットワーク用途やNASのコントローラーの場合には暗号化/復号化処理が多くなることを考えてか、AES128/256対応の暗号化アクセラレーターに加え、GFNI(ガロア体演算)という新しい命令セットを追加した。今のところこれはTremontのみに実装されており、SunnyCoveですら未サポートとなっている。
ガロア体演算はリードソロモンや楕円体暗号などで利用される演算手法で、これを高速化するのが目的と考えられる。SSEの場合は128bit幅ということもあり、Load/Storeユニットというかデータパスにそれほど負担をかけないため、省電力性が確保できる、というあたりもAVXをサポートしない理由の1つだろう。
なお、上の画像には記されていないが、MOVDIRI(Direct Store)という命令が新たに追加されている。これはWrite-combiningをバイパス、データをData Cache/L2 Cacheに書き込むことなく直接メモリーに書き出すというもので、特に外部のアクセラレーターなどと煩雑にやり取りをする際に書き込み完了までの時間を短縮する効果がある。Tremontがネットワーク向け機器の用途などを想定していることをうかがわせる新命令である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































