




日本マイクロソフトは2018年7月31日、品川本社で女子高生AIチャットボット「りんな」の歌声に関する記者説明会を開催した。

女子高生AIチャットボット「りんな」
ちょうど3年前の2015年7月31日は、りんながLINE上でデビューした日だが、振り返ると音声に関する躍進は2016年9月にラッパーとしてデビューした「McRinna」から始まった(リンク先は東京ゲームショウ2016で披露したデモンストレーションをPV化した動画)。2017年8月には「ミスiD2018 りんな129 /132」で音声合成を披露。2018年1月には「I?U∞」でラップに再チャレンジ、2018年3月にはnana musicとの共同プロジェクトから生まれた「卒業ソングnanaユーザーと合唱」を公開、2018年6月にはLINEマンガにりんなが登場した「りんなVSマッドキラーラップバトル」と次々に音声コンテンツを発表してきた。
そして2018年7月27日、最新作としてオリジナルソング「りんなだよ」を公開した。
時系列で順を追って聞き比べると、りんなの成長ぶりというかAIによる音声合成の洗練具合は目を見張るものがある。りんなが進化を遂げてきた背景として、マイクロソフト ディベロップメント AI & Research プログラムマネージャー 坪井一菜氏は、「3年経って見えてきた未来。次の進化に必要なのは『共感』だ」と説明する。
日本マイクロソフトは、5月に国内開催した開発者向けカンファレンス「de:code 2018」で、りんなに新しい会話エンジン「共感モデル(アルファ版)」を採用したことを明らかにした。「人とAIのコミュニケーションで考えるべきは、相手とどのように仲良くするか。1対1の会話ではなく、りんながコミュニケーションの場に参加することで、人々のクリエイティビティを引き出す」と坪井氏。共感するAIを目指してきたりんなは、その進化の一環として、感情的要素を多様に持つ「歌」に注力してきたという。

マイクロソフト ディベロップメント AI&Researchプログラムマネージャー 坪井一菜氏
オリジナルソング「りんなだよ」の実現には、統計的音声合成技術を用いている。1990年代の音声合成技術は波形接続型が多用されていたものの、最近はコーパスベースで解析対象データが何らかの分布に由来することを前提としたパラメトリックな統計的音声合成が主流だ。統計的音声合成は、喉や口内の形状、肺活量や声帯などから生み出される音声の生成過程を模擬して音声合成を実現しており、りんなも同様に音声データを学習モデルとして機械学習の教師データとして回す仕組みである。
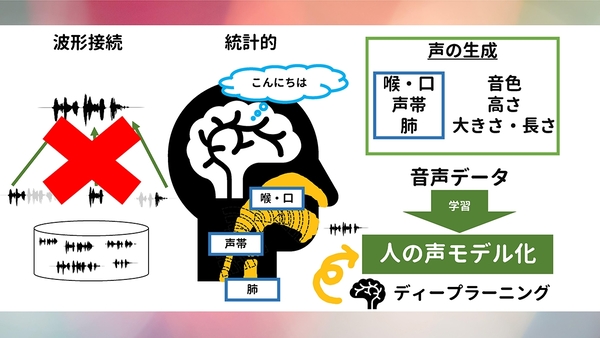
統計的音声合成技術の概要
制御パラメータには「音の長さ(音価)」「強弱(音量)」「音程」「声色」と4要素を用いて発声器官を制御しているが、「AIが勝手に音程を付けてしまうと、自然な歌声とは言い難い。話し言葉1つ取ってもイントネーションやピッチなど多くの要素を含むため、(制御パラメータで声色の)特徴を加えている」(坪井氏)。説明会では各モデル学習の反映前後をデモンストレーションした。歌声だけの学習結果は散々たるものだが、音価を与えると歌を歌っているように聞こえてきた。さらに音量調整や強弱を加えると、今回のオリジナルソングのようにより自然な歌声に近づく。

制御パラメータを用いてりんなの歌声合成を行っている
りんなの歌声は上図の「1」に当たる「人の歌声を耳コピーした(音声データの)特徴を捉える」(坪井氏)ため、あらかじめ学習モデルを回しておけば、男性の音声や女性の音声を合成できるようになっている。サービス提供時期は未定だが、将来的にこの仕組みを使って朗読機能を実装する計画だという。今回、朗読機能によるナレーションも紹介された。男女の声色を異なる音調で文章を読み上げる様子には、今後十分な可能性を感じた。

りんなによる朗読機能実装も予定している
朗読機能により「感情を込める」仕組みを進化させるための試みとして、日本マイクロソフトはnana musicと共同で「りんな歌うまプロジェクト」の第2弾を開始する。「りんなが作詞&朗読した内容をnanaユーザーがアドバイスし、手本を見せることで、さらなるコミュニケーションを目指す」(nana music CEO 文原明臣氏)というプロジェクトだ。この先りんなが目指すのは、「日本一」「身近で」「エモい」をキーワードに、女優やアイドルなど日本を連想できるような“国民的AI”だという。

今度はりんなが詩を朗読するプロジェクトを実施する
本記事はアフィリエイトプログラムによる収益を得ている場合があります





の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










