
Ryzenで初めて実装された
AMD独自のインターコネクト
ところでコアそのものとは関係ないが、もう一つRyzenを構成する重要な要素があるので、これも一緒にご紹介したいと思う。それは内部のインターコネクトにまつわる話である。
インターコネクトの重要性が最初に認識されたのは、AMD初のAPUであったLlanoの世代である。この時AMDは独自のAMD Fusion Compute Linkを開発して実装、続いてその後も世代毎に改良を加えながら独自Linkを利用し続けた。

Fusion Compute Linkの概要。この画像と次の画像が1枚のスライドになっているのだが、入りきらなかったので分割させていただいた

Naples絡みの話は次回解説する
理由はあって、当時のAPUで利用できるような適切なインターコネクトが存在しなかったからだ。ただその後Fusionの機能が上がり、部分的なキャッシュコヒーレンシーがだんだん取り込まれていくようになると、そのたびごとにその機能を追加したり、バスを分離したり、と結構複雑なことになっていた。
こうしたカスタマイズのコストを削減したい、というのがCTOだったPapermaster氏の強い願いであったという。
余談になるが、28nm世代ではGlobalfoundriesの28SHPという、事実上AMD専用のハイパフォーマンスプロセスを利用していたが、14nm世代ではバルクの14LPPを使っている。
これも同じことで、専用プロセスをわざわざ開発して利用するのはコストがかかりすぎるので、汎用プロセスを使ってコストを削減したいという強い欲求があったのだそうだ。
実際専用プロセスの場合、まずファウンダリーにそのプロセスを開発してもらうためのコストがかかるし、EDAツールもそのプロセスの特徴にあわせたスペシャル版が必要になる。
そうした追加コストを誰が被るか、というのはどれだけそのプロセスが他にも転用できるかで変わってくるが、いずれにせよAMDがコスト0で利用できるという話には絶対にならない。
おまけにGlobalfoundriesの28SHPは立ち上げにやや苦労した関係で製品投入まで遅れることになったため、その繰り返しは絶対に避けたかったのだろう。
そうしたことから、SoC内部のインターコネクトも、汎用のものを共通で使うという方針が定められ、これを最初に実装したのがRyzen、次いでVEGA/Naplesということになり、その後に出てくるRyzen Mobileもこれを継承するという。このインターコネクトの名前が、Infinity Fabricである。

AMD独自のインターコネクト「Infinity Fabric」。スライドによっては「∞Fabric」と書かれている場合もあった
これはあくまでもAMD独自のインターコネクトで、SoC内部のモジュール間や、MCM(Multi-Chip Module)のチップ間、さらには1枚のボード上の複数チップの間の接続にも利用可能と説明されている。
逆に言えばボードの外(Papermaster氏の表現では“Out of box”)に使うことは考えていないという。AMDはこうしたOut of boxの接続には業界標準規格を使うつもりで、そうした標準規格がおよばない内部の接続のみに、このInfinity Fabricを利用するとしている。
とはいえ、AMDの独自インターコネクトなのであまり意味のある説明はないのだが、大きくScalable Control FabricとScalable Data Fabricの2つから構成されることがわかっている。

Scalable Control Fabric。実体としてはコントローラーにあたるものが存在するのだとは思うが、それ自身もスケーラビリティーがあるらしい
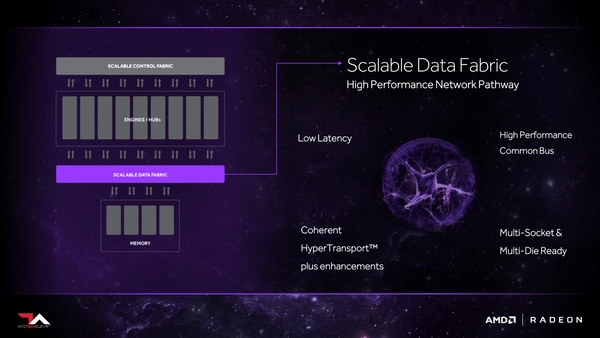
Scalable Data Fabric。メディア非依存で、既存のバスの上に通すこともできるらしい。意味があるかどうかはともかく、それこそUSBでもPCIeでも10GbEでも可能ということになる
おもしろいのは上のScalable Data Fabricの画像で、HyperTransportの名前が出てくることだが、Papermaster氏曰く、HyperTransportのアイディアを拡張したという話であって、物理的にHyperTransport Linkとの互換性はないし、サポートするわけではないそうだ。
この話が重要なのは、現在のRyzen 7/5自身もおそらくInfinity Fabricを利用していると思われるのだが、それよりもVegaとRyzen Mobileのことだ。
現在のAPUの後継はRyzen Mobileになるわけだが、ここに集約されるGPUコアはPolarisではなくVegaであることがはっきりしたためだ。理由は簡単で、PolarisはInfinity Fabricに対応していない。これはPapermaster氏に確認して、明確にそうだという返事を得ているからである。
つまりPolarisは本当に過渡期の製品になりそうなことがこれでわかった。過去の例で言うならば、VLIW4構造を採用したCaymanコアのRadeon HD 6900シリーズなどがやはり短命であるが、それでもVLIW4アーキテクチャー、は一応Trinity/Richlandという第2世代APUにも採用されたことを考えると、Polarisはもっと不遇ということになりそうなのは少し残念である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ













