



「The Machine」実証実験に成功、数年後にはその新技術がさまざまなHPE製品に搭載される
HP Labsフェローに聞く“メモリ主導型アーキテクチャ”はなぜ必要?
2016年12月27日 07時00分更新

11月28日、米ヒューレット・パッカード・エンタープライズ(HPE)が、“メモリ主導型コンピューティング(Memory-Driven Computing)”の実証実験に成功したことを発表した。HPEが2014年に発表した「The Machine」研究開発プロジェクトにとって、大きなマイルストーンとなる出来事だ。
The Machineは、コンピューティングに関する幾つかの新しいテクノロジー要素を組み合わせ、「メモリ主導型アーキテクチャ」のコンピューターを実用化することで、従来型のコンピューターでは不可能なパフォーマンスと効率性、拡張性を実現しようとしている。今回は、そのプロトタイプを使った実証実験が行われた。

HPEが開発した「The Machine」プロトタイプのブレード。左半分がコンピュートノード、右半分が共有メモリノードとなっており、それぞれ独立して機能する
本稿では、今年10月にHewlett Packard Labs(HP Labs)フェローのカーク・ブレスニカー氏にインタビューした内容を軸として、メモリ主導型アーキテクチャとは何か、なぜ必要なのか、将来のコンピューターにどのような影響を与えるのか、といったことを見ていきたい。(インタビュー実施日/2016年10月6日)

Hewlett Packard Labs フェローのカーク・ブレスニカー氏

プロトタイプの実装作業(The Machineプロジェクトサイトより)
巨大メモリプールにプロセッサがぶら下がる「メモリ主導型アーキテクチャ」
まず、The Machineが目指す「メモリ主導型アーキテクチャ」のコンピューターとは、これまでのものとどう違っているのか。
ブレスニカー氏は、これまでのコンピューターは基本的に「プロセッサ主導型アーキテクチャ」であり、その構造は1940年代にフォン・ノイマンが提唱したコンピューターの原型から大きく変わっていないと説明する。

過去60年以上にわたってさまざまな形のコンピューターが開発されてきたが、「プロセッサ主導型アーキテクチャ」に変化はなかった
具体的には、演算装置であるプロセッサが中心にあり、そのプロセッサがI/Oを通じて入力されたデータを処理して、結果を出力する。このときメモリは、プロセッサの処理を補助する一次記憶装置として、プロセッサに直接“ぶら下がる”形になっている。メモリに保存されたデータは高速に読み出せるが、記憶できる容量が小さく、電源を切ると内容が失われるため、そこに収まらないデータや長期保存したいデータは別途、プロセッサとI/Oを経由して外部の記録装置(HDDやSSDなどのストレージ)に保存される。
大規模なワークロードを処理する場合に、複数台のコンピューターノードをネットワーク接続してクラスタを構成することもある。ただしこのときも、個々のノードは変わらずプロセッサ主導型アーキテクチャであり、ノード間でのデータ共有はプロセッサとネットワークI/Oを介して行われる。ブレスニカー氏は、このコンピューターノードを「個々に分割された島」のようだ、と表現する。
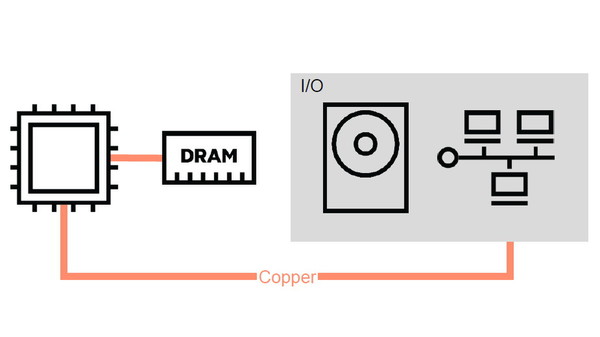
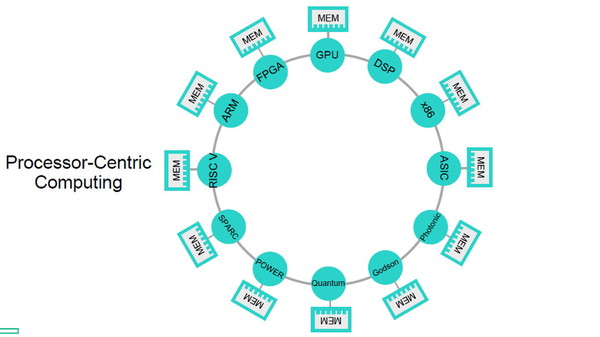
現在のコンピューターで一般的な「プロセッサ主導型アーキテクチャ」(左)。クラスタ構成では“個々に分割された島”のようになる(右)
HPEが考えるメモリ主導型アーキテクチャは、こうしたこれまでのプロセッサとメモリの関係を逆転させ、いわば「大きなメモリにプロセッサがぶら下がる」形になっている。
具体的には、大容量の「共有メモリプール」を中心に配置し、すべてのデータはここに保存される。そして多数のプロセッサが、高速なメモリファブリックを介してメモリ上のデータにアクセスし、処理するという構造だ。
大規模なワークロードを処理する場合でも、複数のコンピューティングノードが共有メモリ上の同じデータを直接参照できるため、低速なネットワーク経由でデータをやり取りする必要がない。また、共有メモリプールを構成するのは、電源を落としてもデータが消えない不揮発性メモリ(NVM)であり、HDDやSSDで構成される従来の低速なストレージを置き換える。こうした点から、特に大容量のデータを扱うワークロードでの処理が大幅に高速化することが期待できる。
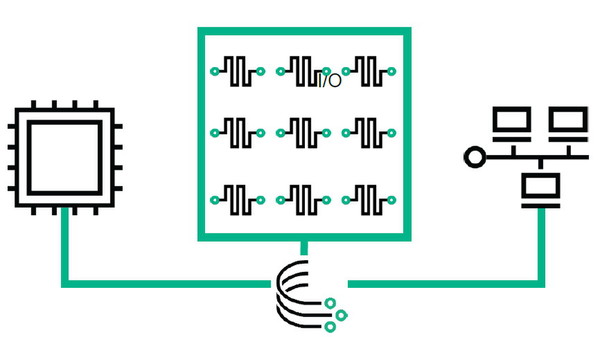
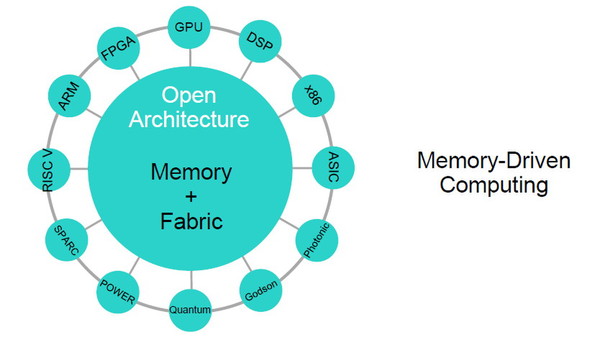
メモリを中心に据える「メモリ主導型アーキテクチャ」のノード構成(左)。クラスタ構成の場合、共有メモリプールを中心にプロセッサ(コンピュートノード)が“ぶら下がる”形になる(右)
「ポスト・ムーア時代」を控え、新たなパラダイムが必要とされている
このように、メモリ主導型アーキテクチャは、半世紀以上大きな変化のないコンピューターアーキテクチャを刷新することを狙うものだ。しかしなぜ、こうした発想の転換が必要なのか。ブレスニカー氏は、その理由として「『ムーアの法則』の終焉」と「生成されるデータ量の指数関数的な増加」を挙げる。
コンピューターが搭載するマイクロプロセッサは、これまで「半導体の集積密度は(=プロセッサが搭載するトランジスター数は)16~24カ月ごとに約2倍になる」というムーアの法則に沿ったスピードで、指数関数的に性能向上を続けてきた。しかし近年では、集積密度向上の物理的な限界(半導体製造プロセスの微細化の限界)が近づいており、将来的にはこれまでのような成長は見込めなくなっている。
その一方で、世界で生成されるデジタルデータの量は、これから爆発的に増大していくことが確実だ。たとえばIDCによる試算(2014年発表)では、1年間のデータ生成量は、2013年の4.4ゼタバイトから2020年には44ゼタバイトと10倍にも拡大すると指摘されている。
加えて、ブレスニカー氏は「課題はデータの『量』だけではない」と指摘する。これからの社会では、膨大なデータの処理にかかる「時間」の短縮もまた求められるからだ。
社会のスマート化が進むなかで、たとえば交通/輸送システム、電力システム、ヘルスケア、社会セキュリティといった、重要なコンピューターシステムが構築されていく。時として、こうしたシステムでは膨大なセンサーから収集されたテラバイト、ペタバイト級のデータを、これまでの分単位や秒単位ではなく「ミリ秒単位」で処理することが求められる。これも、従来型のコンピューターでは実現が困難な課題である。
したがって、これからのコンピューターには、プロセッサの技術進化に依存することなく、膨大なデータを効率良く高速に処理できる能力が求められることになる。その答えとして、HPEでは「メモリ主導型アーキテクチャ」という大きなパラダイムの転換に至ったわけだ。
「3年前、HP Labsに加わったときから、わたしは研究所のメンバーに対してある問いを投げかけてきた。『プロセッサの技術進化が止まったとき、われわれはどう対応するのか?』という問いだ」(ブレスニカー氏)
ブレスニカー氏は、プロセッサの進化に限界が来ている一方で、メモリは容量、製造コストとも、まだ大きな進化の余地が残されていると語る。
「ノイマンの時代には、メモリは高価で貴重なものだった。だが、現在では豊富に使えるようになっている」「半導体製造プロセスの微細化には物理的な限界が近づいているが、メモリにはまだ指数関数的に容量を増やしていく余地が残されている。メモリアレイを垂直方向に積み重ねていくことができるからだ」(ブレスニカー氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



