




各研究所が競いあうようにマシンを増強
ローレンス・リバモア国立研究所で多数のLinuxクラスターが稼動し、しかもきちんと利用できる環境になっていることを見てか、まず2003年にロスアラモス国立研究所はLinuxNetworX(2008年にSGIに買収)と契約、Dual Opteron×1280ノードをMyricomのMyrinetで接続した構成のLightningというシステムを稼動させる。
こちらはピークで11TFLOPSという性能で、2003年11月のTOP500では実効性能8.051TFLOPSで6位につけている。
サンディア国立研究所も1990年代からASCI C-Plantと呼ばれるLinuxクラスターを構築していた。初期のC-Plantは500MHz駆動のAlpha EV56を286台、Myrinetで接続した構成だったらしいが、その後さまざまなノードが後追いで追加され、複雑なことになっている。

初期のC-Plant。どうみても、そこらのAlpha搭載のミドルタワーをむりやりラックに収めただけ、という構造に見える
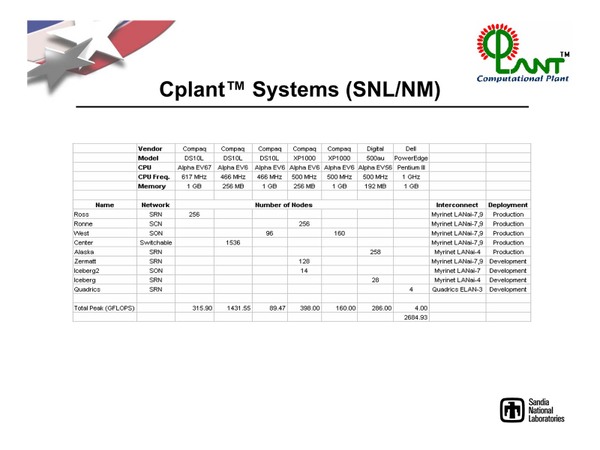
さまざまなノードが後追いで追加された。これがすべて同時期に使われていたというわけではなさそうではある
左画像の出典は、“Delivering Insight - The History of ASCI”。右画像の出典は、“Computational Plant (Cplant)”
ちなみに右上の画像ではDellのPowerEdgeを搭載したものは4ノードしかないことになっているが、その後サンディア国立研究所はDual Xeon64を4096ノード集約し、CiscoのInfinibandスイッチで結合したThunderbirdという名のシステムを導入、2005年11月のTOP500で5位につけている。
これに負けじと、ローレンス・リバモア国立研究所も2006年にPelotonと呼ばれるLinuxクラスターを導入する。これはAppro(現CRAY)が納入したシステムだが、16128コアのDual-Core Opteronを20Gbps 4x DDRのInfinibandでつないだ構成になっている。

PelotonはAtlas/Minos/Rhea/Zeus/Yana/Hopiという6つのシステムからなり、これは最大の1152ノードを持つAtlasの写真。最小構成はHopiの76ノードである
画像の出典は、“Linux Clusters Overview”
このように各研究所が勝手にLinuxクラスターをどんどん導入して無秩序に増強していくのはどうか、という話がどこかであったらしい。2007年6月、3つの研究所は共同でTLCC(Tri-laboratory Linux Capacity Cluster)のRFPをリリースする。
このRFPの構成は、ローレンス・リバモア国立研究所のPelotonにかなり近いもので、ロスアラモス/サンディア/ローレンス・リバモアのすべての研究所に設置された。

TLCC。これは1152ノード/18432コア構成のJunoと、288ノード/4608コア構成のEosの写真。他にもう1つ、864ノード/13824コア構成のHeraがある
画像の出典は、“Linux Clusters Overview”
続いて2011年6月には、この後継としてTLCC-2(Tri-lab Linux Capacity Cluster 2)の導入が決まった。こちらはプロセッサーをXeon E5-2670に、ネットワークをQDR Infinibandに置き換えたもので、やはりApproが納入している。

TLCC-2。これは2916ノード/46656コアのZinの写真。他に1296ノード/20736コアのCab、162ノード/2592コアのRzmerlとPinotが存在する
画像の出典は、“Linux Clusters Overview”
これに続くものとして2015年6月からTLCC-3に相当するものの要求仕様の策定作業が開始されており、順調に行けば2016年中旬に明らかにされる見通しとなっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























