




前回のアップデートが昨年9月だったこともあって、あまり情報はないのだが、今後の動向についてまとめておきたい。
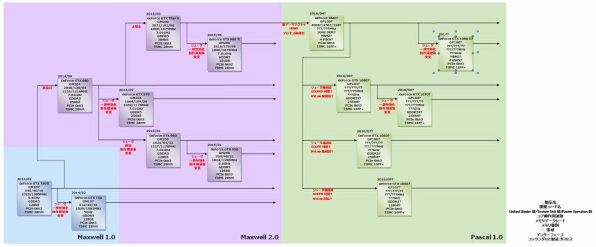
2014年~2017年のNVIDIA GPUロードマップ
まず既存の製品に関しては図のとおりで変更はない。厳密に言えば、Maxwell 1.0世代にGM108コアが存在するが、こちらはモバイル向けのローエンド製品で、GeForce 930M/940Mにのみ採用された製品、SMMの数は3つで、シェーダー数で言えば384となる。
さすがにここまでくると性能が低すぎてデスクトップには向かないと判断されたのか、OEM向けのGeForce GT 740はいまだにGK107ベースで、その上はGM107ベースのGeForce GTX 745になっており、GM208をデスクトップ向けに入れる予定は全然ないまま終わる見込みだ。

GeForce GT 740を搭載したビデオカード「ZOTAC GeForce GT 740 2GB DDR5」
アーキテクチャーをPascalに刷新
GP100を4月のGTCで発表か?
さて、ここからは未来の話だ。今年はNVIDIAもPascalアーキテクチャーをあらゆる製品で展開する予定である。まず前回からの相違点で言えば、コード名が当初GPxxxと記していたのだが、PKxxxになるらしいと書いたのが、最新の情報ではやはりGPxxxになるようだ。ということでコード名は再びGPxxxに戻している。
Pascalが最初のお披露目になるのは、このシリーズのハイエンド製品であるGP100となる見込みだ。実はGP100を搭載したモジュールは、昨年9月に開催された2015 Taiwan GTCのディープラーニングにおける講演のスライドで公開されている。

2015 Taiwan GTCのディープラーニングにおける講演のスライドで、GP100を搭載したモジュールが公開された
NVIDIA TaiwanのYouTubeビデオの2分47秒あたりから、これが講演スライドの一部として表示されているのがわかる。ただし、あまり詳細に観察してほしくはなさそうでもある。
NVIDIAは、本来Maxwell 2.0となるべきであったTSMCの20nmプロセスを利用したGM104をキャンセルして28nmに戻す作業と並行して、Pascal 1.0の16FF+への実装を急いだのは間違いないし、GP100コアはかなり早いタイミングで最初のシリコンが出てきていると考えられる。
実のところ、早く出てこないとまずいという事情がNVIDIAサイドにはある。いきなり話がスーパーコンピューターに飛んでしまって恐縮なのだが、連載317回で、NVIDIAがTeslaの将来製品にNVLinkを搭載、これがIBMのCAPIと互換になっておりPower8と接続できると解説した。
このPower8+NVIDIA GPUという構成がオークリッジ国立研究所のSummitとローレンス・リバモア国立研究所のSierraに納入されることがすでに決まっている。
もう少し背景を説明すると、現在オークリッジ国立研究所にはTitanというマシンが稼働中で、これは連載302回の最後に触れた、CRAYのXE6ブレードとTesla K20を組み合わせたシステムである。
一方ローレンス・リバモア国立研究所にはSequoiaが稼働中で、これは連載306回で解説したBlue Gene/QをベースとしたASCの一部である。ただどちらも2017年には稼動後5年を経過するということで、そろそろ機材の更新時期になる。
そこでこの2つを置き換えるためのCORAL(Collaboration of Oak Ridge、Argonne、and Livermore)プロジェクトが米エネルギー省で2014年に実施された。要するにすべての研究所でそれぞれ仕様を決めて導入するのではなく、共同で仕様を策定して導入しようというものである。
日本でも筑波大と東大および京大がT2Kと呼ばれる共通仕様のスパコン導入を行なったりしたが、それのもっと大規模版というところだ。
このCORALプロジェクトに選ばれたのがIBM+NVIDIAという組み合わせで、オークリッジ国立研究所にはTitanの更新でSummitが、ローレンス・リバモア国立研究所にはSequoiaの更新でSierraが導入される。
基本構成は同じだが、Summitは300PFLOPS以上、Sierraは100PFLOPS以上の性能を出すことになっている。SummitはSierraの3倍以上のノードを集積する「予定」なわけだ。
契約によればSummitでもSierraも2017年中に設置され、2018年に稼動することになっている。それはいいのだが、問題はこのSummit/Sierraの構成はIBMの次世代プロセッサーであるPower9と、NVIDIAの次々世代GPUであるVoltaの組み合わせとなっていることだ。

2018年に登場予定となっているNVIDIAの次々世代GPU「Volta」。画像はGTC 2015におけるジェンスン・ファン氏の基調講演より
もちろん実際にはいきなりPower9とVoltaを用意できるわけもないのだが、用意できるまで待ってるのも無駄だ。OSや通信関係など、開発すべきソフトウェアはインフラ側にも山とあり、アプリケーション側も当然移植作業が必要になるので、事前に開発用機材を用意する必要がある。
この開発機材として、まずはPower 8+KeplerベースのTesla(K40あたりか?)という構成のマシンがすでに少数導入されているのだが、これに加えてPower 8+Pascalという構成の機材が次に導入されることになっている。時期的にはすでに導入されているはずである。
というのはPower 8+Keplerの場合はNVLinkが利用できないため、ホストとの通信はPCI Express経由になっており、最終的な環境とかけ離れすぎている。これがPascalになると80GB/秒ではあるが(Volta世代では200GB/秒に達する)より高速な接続になるので、ライブラリー周りの開発やアプリケーションの予備評価には十分役に立つことになる。
したがって、PascalベースのGP100コアはすでに特定顧客向けに評価用の出荷がとっくに終わっている時期である。出荷していないといろいろ間に合わないことになってかなりマズいだろう。ということで、4月のGTCにはGP100は間違いなく登場すると思われる。
ただし問題は、これがデスクトップ向けとして出す余地があるかどうかである。ここでようやくロードマップに戻る。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























