




使える超並列マシンとして評価を得た
影の立役者「CRAY T3E」
CRAY T3Eは2年後の1995年にリリースされた。違いはいくつかあり、まずプロセッサーはより高速なAlpha EV56に切り替えられた。連載291回の最後でも少し触れているが、4命令同時発行のスーパースカラー構成で、プロセスは0.35μmのCMOS6を利用している。
動作周波数はいくつかあり、最初にリリースされたT3E-600が300MHz、次いで450MHzのT3E-900、600MHz駆動のT3E-1200とその改良型のT3E-1200E、675MHzのT3E-1350までが最終的に用意された。

これは2001年にCRAY Inc.が出したCRAY T3E 1350のカタログ
いかにプロセスを微細化したとはいえ、ここまで動作周波数をあげるともちろん空冷では追いつかないため、液冷オプションも用意された。トーラス構造も変更され、例えば1024PEの構成ではX/Y/Xはそれぞれ8/16/8ノード構成という、3Dトーラスらしい構成が取れるようになった。
また、T3Dでは2つのプロセッサーで1つのノードを構成していたが、T3Eでは1プロセッサーが1ノード構成になっている。
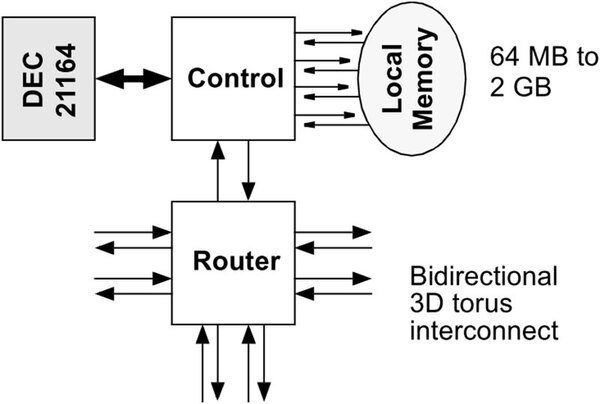
これはCRIのSteven L. Scott氏とGregory M. Thorson氏が1996年のHot Interconnects IVで発表した“The CRAY T3E Network:Adaptive Routing in a High Performance 3D Torus”という論文からの抜粋。やはり効率を上げるには1プロセッサーを1ノードとしたほうがよかったようだ
ハードウェア的に肝となるのはプロセッサーよりもむしろ上の画像に出てくるRouterの部分で、論文によれば375MHzで動作、1本のリンクはおおむね500MB/秒の帯域を持つとしている。
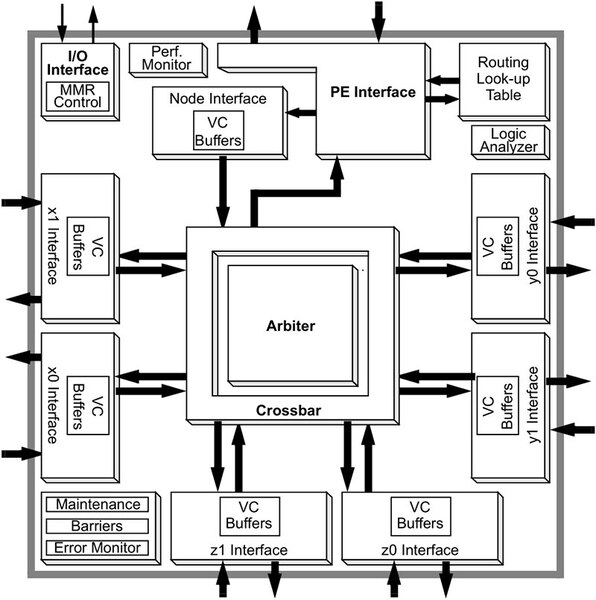
1本のリンクはおおむね500MB/秒の帯域を持つ。回路規模はおよそ500KゲートのASICだそうだ
隣接ルーター間の通信はおよそ3クロック(40ナノ秒)、エンドポイント同士、つまり2つの隣あうプロセッサー間は10クロック(133ナノ秒)で通信できるとしており、これはかなり高速な部類に入る。
このT3Eに関しては、ソフトウェア側の開発もだいぶ進んだことで、T3Dの頃に比べて若干性能も改善した。
TOP500の結果をいくつかピックアップしてみると、NASA/ゴダード宇宙飛行センターの1356ノードのシステムは理論性能813.60GFLOPSに対して実効性能525.00GFLOPSで64.5%、米陸軍HPC研究センターの1084ノードのシステムでは1300.80GFLOPSに対して892.00GFLOPSで68.6%と、このあたりはあまり改善されたように見えない。
ところが、もう少し小規模なところでユーリッヒ研究センターの540ノードのシステムは324.00GFLOPS/234.00GFLOPSで効率72.2%、マックス・プランク研究所の812コアのシステムでは487.20GFLOPS/355.00GFLOPSで効率72.9%と、ノード数が増えている割には効率も高まっており、絶対性能そのものの引き上げと相まって、科学技術計算には使えるシステムになったという評価になっている。
例えば1998年にBerkelay Labが出したリリースによれば、もともとインテルのParagon向けに書いたシミュレーションコードをT3Eに移植することで、1024原子の鉄の金属磁性のシミュレーションを最大1.02TFLOPSで実行できた(ノード数は1480)としており、「使える超並列マシン」としての評価がついた。
もっとも絶対的な販売数はそれほど多くなかったため、T3Dの分まで加味して考えると開発費は回収できたにしても、大ヒットしたという状況からは遠かったのは事実だ。
ただここで得た知見、特にT3EのRouter ASICは、RedStormのSeaStar SoCの元になったチップであるし、T3Eで実装されたUNICOS/mk(T3D向けのUNICOS/MAXの発展型)はその後Linuxに移植され、CRAY XTシリーズでも利用されることになった。
その意味では、RedStormの成功やその後のCRAY XT/XCシリーズの基礎がこのT3D/T3Eとも言えるわけで、現在までCRAY Inc.が生き残れることになった影の立役者でもある。その意味では、保険的な発想で開発を始めた当時の経営陣に先見の明があった、ということかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ













ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












