




今回はASCI Blue Pacificの後継となる、ASCI Whiteの話である。元々のASCI計画は段階的に性能をあげていくものだった、という話は連載286回でお伝えした通りだ。

ASCI White
Option Redが1TFLOPS、Option Blueが3TFLOPSで、これに続き10TFLOPSと30TFLOPS、そして100TFLOPSに向けて性能を改善していくシナリオである。その3番目の10TFLOPSを狙うマシンについては、1997年中に設計を開始、1998年から製作に入り2000年には運用を行なう予定であった。
実際にこのASCI Whiteの契約が行なわれたのは1996年7月4日のことである。契約金額は9300万ドルで、当時の為替レートで換算すると101億円ほどになる。
内容的には前回も少し触れたがASCI Blue Pacificのアップグレード的な構成であるが、実際にはプロセッサーボード以下すべてが総入れ替えのため、新規インストールとして差し支えないだろう。
ちなみにこの契約時点ではまだ“ASCI White”という名称は用いられていない。2000年に設置完了のリリース(関連リンク)が出た時にはすでに“Known as ASCI White”という呼び方がされているので、この3年間のどこかで決まったのだろうが、そのあたりはいろいろ資料をひっくり返したものの判明しなかった。
余談だが、この2000年6月という時期は、ロスアラモス国立研究所でセキュリティー事故が起きており(関連リンク)、これに関連してローレンス・リバモア国立研究所も調査を受けていた(関連リンク)模様で、それもあってかASCI Whiteに関するリリースが一切出ていないのは残念である。
開発が遅れたPOWER3
ASCI Whiteの基本構成はASCI Blue Pacific同様にIBMのRS/6000 SPをベースとしたものである。ただし、1996年といえばすでにP2SCも完成しており、さらにPOWER3の設計がだいぶ進んでいた時期である。
そもそもASCI Blue PacificはPowerPC 604evベースであるが、このCPUはFPUが32bit幅であり、かつFPUそのものも1つしかなかった。
これと同時期に登場していたPOWER2は64bit幅のFPUを2つ搭載しているため、動作周波数が同じであればPowerPC 604eをPOWER2に変えるだけで、倍精度の浮動小数点演算性能は8倍以上になる計算である。
なぜ4倍ではないかというと、POWER2のFPUはFMA(Fused Multiply-add:要するにMAC演算)を1サイクルで行なえるから、実際には2演算/サイクルとなるためだ。
もちろん実際は製造プロセスが違うため同じ動作周波数では動かないうえ、POWER2はマルチプロセッサーに未対応だったため、これは実現しないのだが、逆に言えばPOWER2をPowerPC 604evと同等のプロセスで製造し、かつマルチプロセッサー対応にすれば実現することになる。
これを実現したのがPOWER3である。POWER3そのものの発表は1997年10月のMicroProcessor Forumで行われた(余談だが、この発表を行なったのは現在AMDのCTOであるMark Papermaster氏である)。
このPOWER3もやや複雑な経緯を経ている。POWER3の発表に先駆け、1997年にPowerPC 620というプロセッサーがリリースされている。世代的にはPowerPC 603/604と同じ第2世代にあたるのだが、大きな違いは64bit拡張されていたことだ。
内部構造はPowerPC 604に非常に似ており、5段のパイプライン構成で、3×ALU、1×FPU、1×LD/STというあたりはまったく同じである。
またこれとは別に、動的予測機能を持つ分岐予測ユニットと、条件レジスターユニットを持つあたりも同じで、命令/データの1次キャッシュをそれぞれ32KB持つところも一緒である。
ただ本来は1996年中に発表予定だったのが、開発が遅れて1997年にずれこみ、さらにMotorolaがこれを0.5μmプロセスで製造した関係で、速度は最高でも150MHz程度であった。後に0.35μmプロセスに微細化して200MHzに達するが、時すでに遅しであった。
POWER3は、このPowerPC 620を下敷きにしている。実際当初はPowerPC 630と呼ばれていた。ただ途中で命令セットをPowerPC ISAではなくPOWER ISAに改めたり、FPUをデュアル構成にしたりとさまざまな改良を行なった結果、もはやPowerPCには属さないと判断されたためか、POWER3の名前でリリースされている。
内部構造は下の画像の通りで、POWER2同様にそれぞれのFPUはFMAをサポートしており、MAC演算を多用する科学技術系演算では有利とされた。
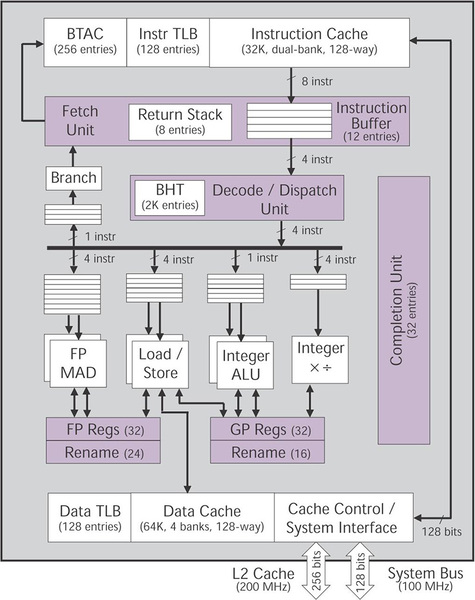
POWER3の内部構造。MicroDesignのMicroprocessor Report 1997/11/17号より抜粋。これは、97年のMicroProcessor Forumの際に配布されたものである
パイプライン長は整数演算で7段、ロードストアで8段、浮動小数点演算で10段と、昨今では短い部類に入るが、この当時ではわりと長大な規模だった。他にもデータキャッシュを64KBに増量したほか、オフチップの形で2次キャッシュを外付けで接続できるようになっている点もPowerPC 620とは大きく異なる部分だ。
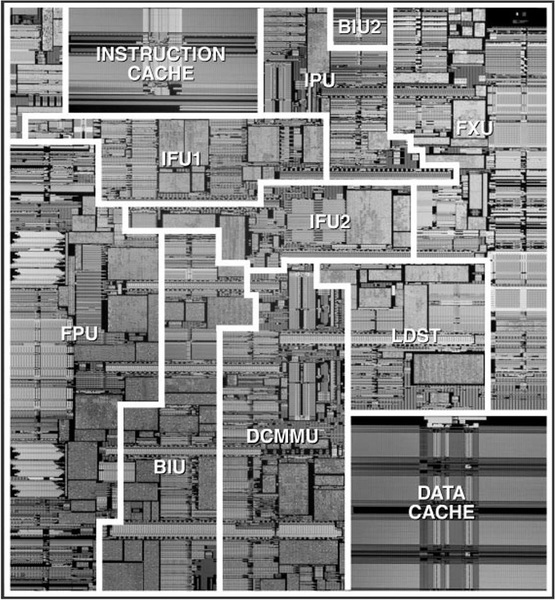
POWER3のダイ写真。キャッシュが占める面積は、案外大きくない。出典は先の画像と同じ
1997年に発表された時には、同社のCMOS-6S2というハイブリッドタイプの0.25μmプロセス(トランジスタは0.25μm、配線は0.35μm)を利用し、1500万トランジスタを270mm2のダイに収め、200MHzで駆動させた。1999年末には、これを0.22μmプロセス+銅配線のCMOS-7Sに切り替え、動作周波数を最大450MHzまで引き上げることに成功している。
(→次ページヘ続く 「スイッチを挟むことで大規模SMPを実現」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















