




今回からは久しぶりに、ロードマップ情報の更新をしたい。まずは2011年5月以来となるNVIDIA GPUのロードマップの最新情報をお届けしよう。
GTX 670と660 Tiはほぼ同じコア
GK104の歩留まりは良好?
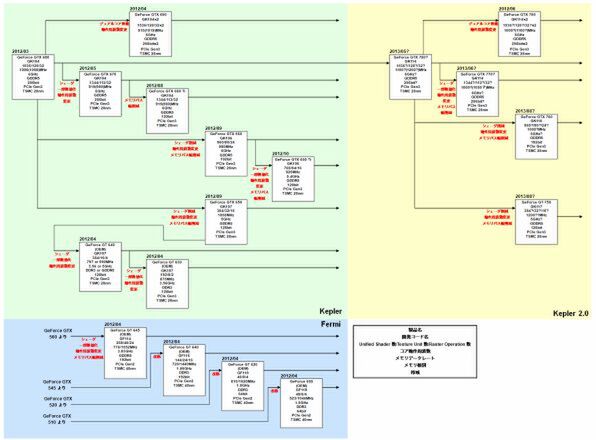
2012~2013年のNVIDIA GPUのロードマップ
連載151回で掲載したNVIDIA GPUのロードマップは、「GeForce GTX 680」と「GeForce GTX 690」が発表されたあたりまでなので、まずはこの続きから始めよう。

GeForce GTX 670のリファレンスカード
2012年5月に、まず「GeForce GTX 670」がリリースされた。構成的にはKeplerの「GK104」コアをベースとした製品ながら、SMXをひとつ減らした低価格版である。Kepler世代の場合、192個の「CUDA Core(シェーダー)+1次キャッシュ+テクスチャユニット」などの周辺回路を組み合わせた塊を、「SMX」(Streaming Multiprocessor eXtreme)と呼ぶ。このSMXを2基まとめたものを「GPC」(Graphics Processing Cluster)と称しており、GK104コアはGPCを4つ搭載する。トータルのCUDA Core数は、192×2×4=1536個となる計算だ。
ではGeForce GTX 670はというと、GPCの数が4基なのは同じなのだが、うち3基のGPCはSMXを2基搭載するのに、残り1基だけはSMXの片方が無効化され、1基となっている。そのためトータルのSMXの数は7基になり、CUDA Core数は192×2×3.5=1344個になるわけだ。
また動作周波数も定格で1005MHzから915MHzに、ブースト時でも1058MHzから980MHzとやや引き下げられた。GTX 680との違いはその程度で、メモリーバスは256bit幅、転送速度6GHz(正確には6008MHz)がそのまま維持された。結果として、GeForce GTX 670はメインストリーム向けとして、手ごろな性能を手ごろな価格で提供できるようになった。消費電力がGeForce GTX 680よりやや低いという程度に止まったのは、致し方ないところか。

GeForce GTX 660 Ti
続いて2012年8月に発表されたのが、「GeForce GTX 660 Ti」である。コアそのものはGeForce GTX 670とまったく変わらず、1344個のCUDA Coreを915MHzで駆動という構図に変化はない。その一方で、メモリーバス幅が256bitから192bitに削減された。
670と660 Tiで同じコアを使うということは、予想以上にGK104の歩留まりがいいと考えてよさそうだ。元々GK104のダイサイズは294mm2、トランジスター数は35.4億とされており、「GeForce GTX 580」の「GF110」に比べると、それほど大きいとは言えないが、小さくもない。そのため量産すると、ある程度の確率で欠陥のあるダイが発生する。その欠陥部分を含むSMXを無効化することで、ダイを救って製品として使えるようにするのが、GeForce GTX 670の主目的であることは言うまでもない。
だが歩留まりがもう少し悪いと、複数のSMX部分にまたがって欠陥があったり、欠陥はあるけど動作周波数が上がらない(消費電力が急増する)といったダイが、ぼちぼち出てくることがある。こうしたダイを救うために、SMXを2基無効にするとともに動作周波数をもう少し下げることで、こうしたダイでも利用できるような配慮をするのが一般的な考え方だ。
ところがGeForce GTX 660 Tiは、GeForce GTX 670と同一の構成・動作周波数である。つまり、より低い歩留まりに対処する配慮が必要ないということになるからだ。とはいえ、製品差別化のための性能とコストダウンの配慮は必要で、この結果がメモリーバスの削減につながったと考えられる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































