




5ポートの実行ユニットを装備
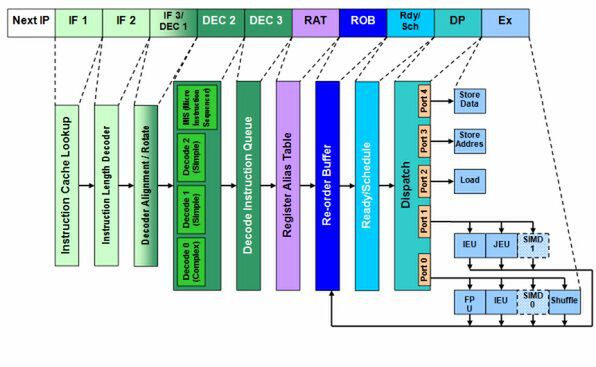
図1 Pentium Proの内部構造図
RATに続く処理が「Re-order Buffer」(ROB)である。これは名前のとおり、命令の並び替えと同時に、終了処理(Retirement)も行なう。ROBはようするに、「今どんな命令の処理を実行中か」の一覧を管理するステージである。ROBそのものはインオーダーであるが、これに続くReady/ScheduleからExecuteまではアウトオブオーダーで実行される。つまり「どの命令がいつ開始され、いつ終了するか」は、ROBにはわからない。
そこで「とにかく実行待機か実行中か、処理完了待ちかはわからないけど、投入はしたよ」という「実行中の命令一覧テーブル」(これをスコアボードと呼ぶ)を管理しているのがROB、ということになる。必然的にROBは、実行ユニットから「この命令の実行を終了したよ」という合図を受けて、その命令をスコアボードから落とす作業も担っている。
ROBから先がアウトオブオーダーでの処理ステージだ。ROBは「現在何μOpが投入されているか」(In-Flightと呼ぶ)を管理し、ゆとりがあるようならばμOpをどんどん追加していく。そうして追加されたμOpは、命令の依存関係などの理由によりすぐに実行できないケースもある。そうした場合に備えて、一時的に命令をプールしておくのが続くReady/Scheduleというステージで、これは一種のキューである。Ready/Scheduledでは最大20個のμOpを格納できる。
このキューから、順次命令を取り出して実行ユニットに振り分けるのが、続く「Dispatch」の処理である。P6の場合、Dispatchには「Port 0」から「Port 4」までの5ポートが用意されて、それらから複数の実行ユニットがぶら下がっている。一番多くの実行ユニットがぶら下がっているのが、Port 0と「Port 1」だ。この2つで整数演算処理やFPU、(Pentium II/III以降で追加された)SIMD演算や特殊命令などを、全部処理している。
1サイクルにひとつのポートから発行されるμOpは、ひとつだけだ。そのため「Load/Store」などのデータ移動「以外」の命令に関しては、Port 0と1の2ポートを使って、1サイクルあたり2命令というのがピーク性能ということになる。
一方Port 2~4は「ロードストアユニット」などと呼ばれることもあり、Port 2はメモリーから(キャッシュ経由で)データをロードして、それを内部レジスタに格納する。一方「Port 3」の「Store Address」は、データをメモリーに格納する際の、メモリーアドレスを計算するユニットである。この計算結果は、「Memory Order Buffer」(MOB、図1では省略)と呼ばれるユニットに渡される。最後のPort 4は「Store Data」で、実際にレジスタのデータをメモリーに格納する処理を行なう。こちらもいったんMOBにデータを格納してから、キャッシュ経由でメモリーに書き戻されることになる。
本来はこれ以外にも、分岐予測がどうなっているのかとか、MOBやRetirementがどうなってるのかなど、細かい話はまだまだある。だが、P6の基本的なアーキテクチャーはこんな構成になっている。x86からμOpsへの変換がある分だけ、デコード段がやや重厚であるが、それを除けばわりと「基本的なスーパースカラー・アウトオブオーダーなプロセッサー」という構成なのが、P6アーキテクチャーだったわけだ。
このP6アーキテクチャーが、続く「Pentium M」や「Core 2」ではどう変化していったのか、というあたりを次回で解説しよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















