




たった50MBに「ケタ違いの語彙データ」を徹底的に詰め込んだ
―― ところで、流行語なども含めると、データ量が相当大きくなるはずなのに、プログラムも含めてダウンロードサイズが50MBに収まっているのも驚きでした。
及川 そこはかなり拘っています。圧縮技術は手前味噌ですが、スゴいです(笑)。
小松 収録語彙数をお教えできないのが残念ですが、相当詰め込んであります。
工藤 データは「TRIE」と呼ばれる構造になっており、ツリー状に、例えば「あ」に連なる言葉として「い」という枝が伸びて「愛」という言葉になるように、一文字ずつ辞書に収めています。これをプログラムに実装する手法として「LOUDS」と呼ばれるアルゴリズムを採用しています。LOUDSのメリットはデータの圧縮率が高いという点ですね。
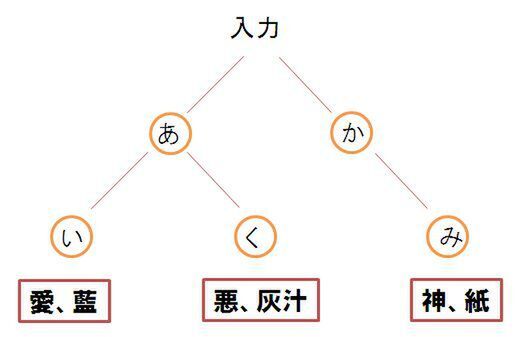
TRIE構造。入力結果で1文字ずつ語彙をツリー状に配置した辞書構造になっている
小松 圧縮率は高いのですが、速度はそれほどでもありません。速さだけを追求するならば他の選択肢もありましたが、データサイズにこだわりました。
―― しかし、その割には他のIMEと比べ軽快に動作していると感じましたが?
工藤 実行ファイルに辞書が含まれてメモリ上に約50MBのデータが展開されます。従ってマシンスペックにかなり影響を受けます。メモリの搭載量が多ければ問題はありませんが、そうでないと仮想メモリにデータが展開されてしまい逆に動作は遅くなってしまいますね。この部分はOSが管理する領域ですので、なかなか解決するのが難しい課題です。
―― ATOKのオンメモリー辞書はオプションとして選択する仕様になっていますが、ある意味、それをデフォルトとして設計できるのはゼロベースで開発する利点でもあるように思えます。
及川 ゼロベースという意味ではまさにそうですね。どういった機能を選択するか、あるいはしないのかという面でもメリットがあると思います。従来のIMEは校正機能など様々な機能を付加することで成長してきた部分があると思います。我々は、広くユーザーが求めていることは何かという点にポイントを絞って開発に取り組んできました。
工藤 私たちの「もしかして」機能でも、ある程度の誤用の修正、たとえば「シミュレーション」を誤って「シュミレーション」と入力した場合には、正しい候補を提示するということはやっていますので、ある程度IMEへの転用は可能ではないかと考えています。
IMEが安定して動作するには、IME本体の設計も重要です。これまでのIMEでは、アプリケーションと変換のDLLが連携して動作します。そのためアプリケーションがクラッシュすると、辞書に対する書き込みが不正となり、辞書も壊れてしまうことがありました。我々が実行ファイル(EXEファイル)に辞書を含めてあるのはそれを防ぐためでもあるのです。

外部のDLLではなくEXEファイルに辞書ファイルを入れているのは、ブラウザーなど入力環境に依存してデータが壊れるのを防ぐためだという。それでもデータ容量50MBというのに驚かされる
本記事はアフィリエイトプログラムによる収益を得ている場合があります








































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")























