





架空のAITuberプロジェクト ChatGPT Images 2.0で生成(以下同)
画像生成AIは、もはや“きれいな絵を出す道具”ではなくなりつつある。OpenAIは4月22日、画像生成モデル「ChatGPT Images 2.0」を発表し、ChatGPT、Codex、APIで提供を始めた。ThinkingやPro系モデルと組み合わせた高度な出力は、有料プランPlus、Pro、Businessユーザー向け。
画質そのものよりも「どれだけ指示どおりに作れるか」に軸足を移したのが最大の特徴。OpenAIによれば、Images 2.0は細かな指示への追従、オブジェクト同士の位置関係、そして画像内のテキスト描写を大きく改善した。従来の画像生成でありがちだった「だいたい雰囲気は合っているが、細部が崩れる」という弱点をつぶしている。
特に強みを持つのは、文字を含むビジュアルだ。UIモック、ポスター、説明図、マンガ、広告素材のように、画像の中に読める文字が必要な場面では、これまでAI画像は最後の詰めを人がやり直すことが多かった。Images 2.0は日本語、韓国語、中国語、ヒンディー語、ベンガル語など、非ラテン文字圏でのテキスト表現も強化したとしている。

架空のアニメ番組 告知画像

架空の4コマ漫画 ネタ、台詞、構図などはAIが考案

架空のスマホゲームの広告 タイトルや設定はAIが考案
OpenAIでは作例として、日本語の少年マンガ風ページや縦長レイアウトの物理ページ風表現を示している。従来の画像生成AIが苦手だった「長文の自然な流れ」や「文字がデザインの一部として成立すること」を狙っていることがわかる。ただ画像を作るだけでなく、読める、伝わる、使えるという、実用性が高いモデルに更新された。

架空のバトル漫画「スマイリーショゴス」表紙

架空のバトル漫画「スマイリーショゴス」SNS用画像のスクリーンショット
もうひとつの変化は、Thinking系モデルと組み合わせたときの振る舞いだ。OpenAIによれば、Images 2.0は同社初の“thinking capabilities”を持つ画像モデルで、必要に応じてWeb上の最新情報を参照し、複数案をまとめて出し、自身の出力を見直せる。ただ指示にしたがうだけでなく、独自の調査と構成を踏まえて画像を作れるようになった。
面白いのは、画像生成がLLMの延長になり始めたことだ。OpenAIでは、説明図の構成、ストーリー作成、レイアウト整理までまとめて担う“visual thought partner”という位置づけをしている。ユーザーは完成図を細かく指定するより、「何を伝えたいか」を渡して、そこから画像を一緒に詰めていく方向に移っていける。単なる画像生成から、編集者やデザイナーに近い能力を持ちはじめた。
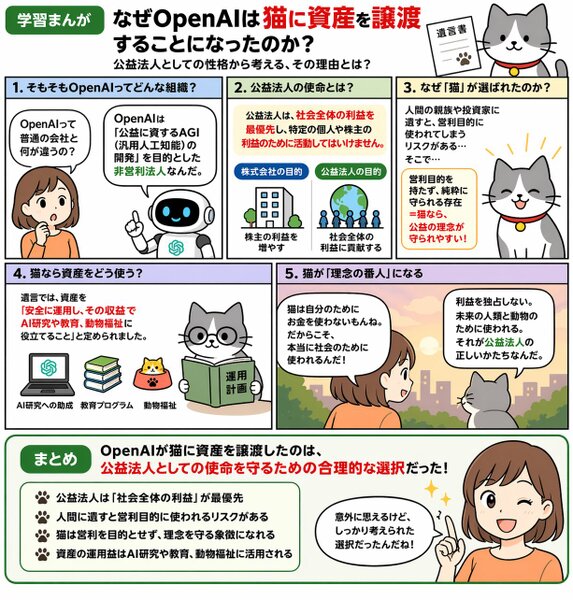
「OpenAI、全資産を猫に譲渡」という架空のニュースの解説漫画。OpenAIの企業としての性格を考慮した内容になっている
出力の柔軟性も広がっている。アスペクト比は横長3:1から縦長1:3まで対応し、バナー、スライド、ポスター、スマホ向け縦画像まで一通りカバーする。Thinking利用時には、最大8枚の一貫した画像をまとめて生成でき、連作マンガや複数サイズのSNS広告などに応用できる。

架空の中年男性

架空の中年男性、コーディネートによる印象の違いを伝える比較画像

架空の中年男性を使った、SNS向けの転職広告サンプル

同じく富裕層向けファンドの広告サンプル

同じく消費者ローンの広告サンプル
API向けには「gpt-image-2」として展開し、2K解像度までの高品質生成や編集に対応する。CanvaやFigma、Adobe、OpenArtといった企業名も並んでいる。
ただし、折り紙のような複雑な空間把握、ルービックキューブ系のパズル、隠れた面や斜め面の正確な描写、極端に密な反復ディテール、厳密なラベル付き図版にはまだ課題があると説明している。物理世界の整合性や図解の完全な正確さでは、まだ人のチェックが前提だ。
それでも今回の新機能が示す方向は明快だ。画像生成AIは“1枚の絵を出す機能”から、“何かを伝えるためのグラフィックを設計する機能”へ進み始めた。Images 2.0は、その境目をかなりはっきり見せたアップデートといえる。

魚眼レンズ風に動きをつけたイラスト

上の画像に人物を追加したイラスト

上の画像をもとにデザインした架空の新アニメの告知画像サンプル

上の告知画像を「スマイリーフェイスのショゴス」モチーフに変更
※記事内の画像はすべてAI生成によるフィクションです。実在の人物・団体などには一切関わりがありません
本記事はアフィリエイトプログラムによる収益を得ている場合があります




















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")






















