



ロードマップでわかる!当世プロセッサー事情 第867回
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする
2026年03月16日 12時00分更新

2.2GHz動作で300TOPS超へ?
演算器構成から逆算するSpyreの動作クロック
Spyreを搭載したカードの構造が下の画像だ。前掲のカード画像と見比べるとかなり似ているのがわかる。ただ、若干部品配置が異なるものもあるので、厳密に一緒というわけではない。

とはいえほとんどの部品配置は前掲のカード画像と同じ。カードサイズもざっと見た限りは同じに見える
このカード1枚で300TOPS以上の性能であり、先に書いたように消費電力は75W以下である。スペック的にはQualcommのCloud AI 100カードに近い。ダイサイズはSamsungの5nmプロセスを利用してダイサイズは330mm2、260億トランジスタとされる。

こうしてみると前掲のダイ写真はやはりCGなのだなというのがわかる。ダイ左右のLPDDR5のPHYの配置が異なるし、ダイ右上のPHY(おそらくPCIe Gen5 x16だろう)の構造も違っている
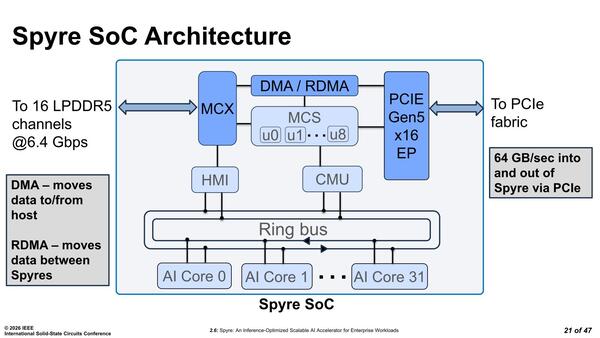
内部構造の概略図が下の画像だ。記事冒頭の画像にもあるように32コアの構成だが、これが双方向リングバスにぶら下がり、同じリングバスにメモリーコントローラーとシステムマネジメント系もつながるという、ある意味わかりやすい構図である。
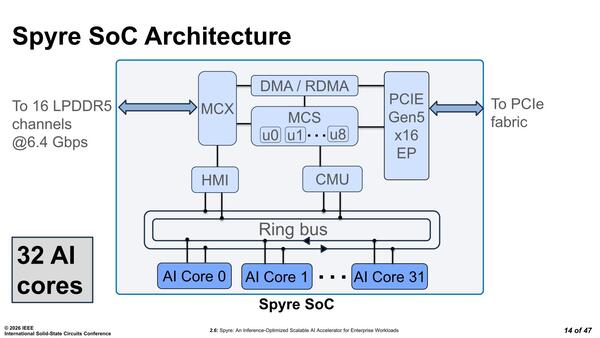
内部構造の概略図。インテルもそうだが、IBMもリングバスが好きな会社だと感じる
コアは32なのだが、物理的には34コア構成である。これは冗長コアが2つあるからという話だった。

ただこの配置ではリングバスよりも縦横のクロスバーにした方がむしろ合理的な気もするのだが、IBMは頑なにリングバスを捨てないあたりがさすがではある
その個々のコアの中身が下の画像だ。8×8の64個のMPEが中核であり、それに8組のFP16/FP32用のSFU(Special Function Unit)と8KBのスクラッチパッドで1つのコレットを構成。このコレットが2つと2MBのL1スクラッチパッド、リングI/Fで1つのコアを構成する形だ。
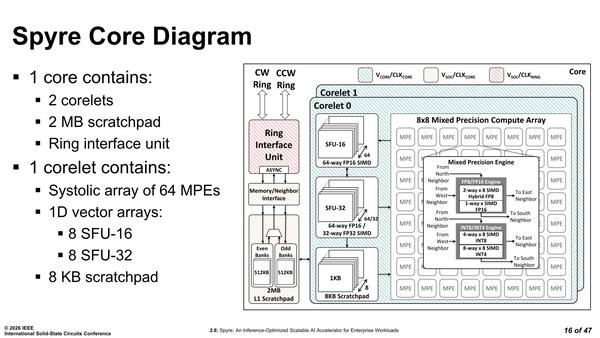
FP8/FP16とINT8/INT4でSIMDエンジンを物理的に分離しているのが特徴的。とはいえ同時に動くわけではなさそう
FP8はe4m3とe5m2の両方のフォーマットに対応している。仮にINT4で計算すると1つのMPEで64 OPS/サイクル。1つのコレットにMPEが64個なので合計4K OPS/サイクル。このコレット×2で1コアだから8K OPS/サイクル。Spyreはこれが32個なので128K OPS/サイクルでの処理できる。
これが仮に1GHzで動作すればピーク性能は128 TOPS/サイクルという計算になる。このページの最初の画像にある300+ TOPSを実現するには動作周波数が2.2GHz以上あればいい計算だ。Samsungの5nmプロセス(SF5)ならこれは容易だろう。
FP16は1-way×8 SIMDの誤記だと思うのだが、論文の方にこれに関する言及がないので誤記と断言しにくい。要するに128bit幅のSIMDエンジンだろう
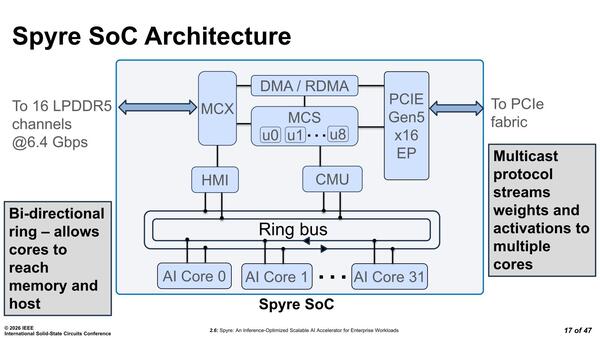
コア同士は双方向のリングバスで接続される形になっている。このリングバスにMCX経由でLPDDR5、それとPCIe Gen5のI/Fが接続されている。
この説明を読む限り、コア同士が相互に通信することはあまり考えていないように思われる
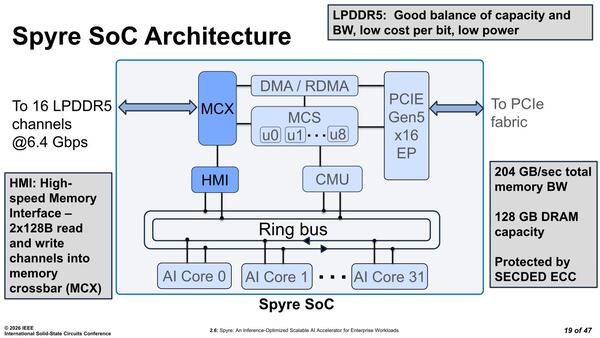
論文によれば16ch LPDDR5@6.4Gbpsで208GB/秒とのことなので、バス幅は256bitという計算になる。4つ上の画像にある、左右に配されるPHYはいずれもLPDDR5 16chのものというわけだ。基板上にLPDDR5チップは8つしかないが、Samsungはすでに16GB(128Gbit)のLPDDR5を出荷しており、これが8つで容量128GBとなるので辻褄は合う。
LPDDR5の場合、x32を2chのx16に分割できるので、これを利用して8チップで16ch分の接続となっている
おもしろいのはMCXとPCIe Gen5 I/Fの間にRDMAが実装されていることだ。RDMAとはRemote DMAの略で元はインフィニバンド、現在はイーサネットなどで多用されているが、Spyreの場合はPCI Expressが対象である。つまり2枚のSpyreカードの間でメモリーの内容を自動で転送するためにRDMAコントローラーが搭載されている格好だ。
こうした制御を行なうために通常ではアプリケーションプロセッサーがいくつか搭載されそうなものだが、SpyreではMCUが8つ実装されたMCSが搭載されているそうだ。
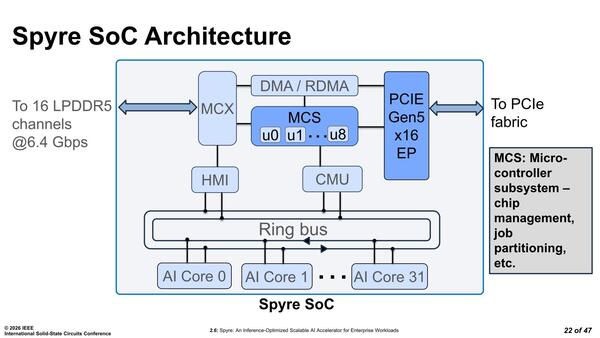
もっともマイクロコントローラーといってもこうした製品の場合、通常ならアプリケーションプロセッサーとして使われるようなものをMCU的に使ってることもしばしばある
絶対的な処理性能ではアプリケーションプロセッサーの方が高速だが、何かイベントが発生してから処理に移るまでの時間という意味ではMCUの方がずっと短くなるので、制御用に使われることそのものは不思議ではない。ただこのMCSはMCXやPCIe、DMA/RDMAの制御などに向けたものであり、コアそのもの制御はCMU(Core Management Unit)と呼ばれる独自ユニットが担っている。
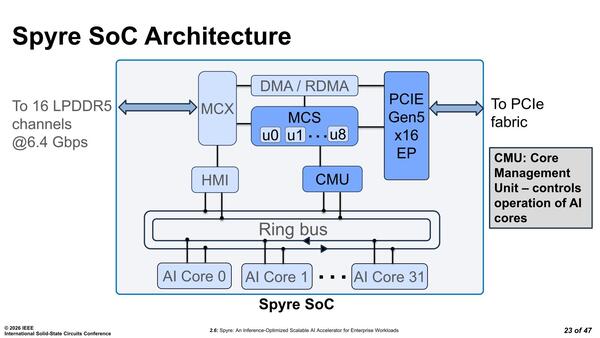
コアの制御はCMUが担う。各コアにどんな処理をさせるかなど、それぞれのスクラッチパッドにメモリー内のどのデータをコピーする、あるいはスクラッチパッドに置かれた演算結果をメモリーに書き戻すかは全部CMUの仕事だろう
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ
























の1台が今ならオトク!")
























")













