



ロードマップでわかる!当世プロセッサー事情 第860回
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新
2026年01月26日 12時00分更新

メモリーバス幅はGraceから倍増
次にメモリーについて。Graceの内部構造が下の画像になるが、Graceの世代ではメモリーコントローラーが全部で16個搭載されていた。
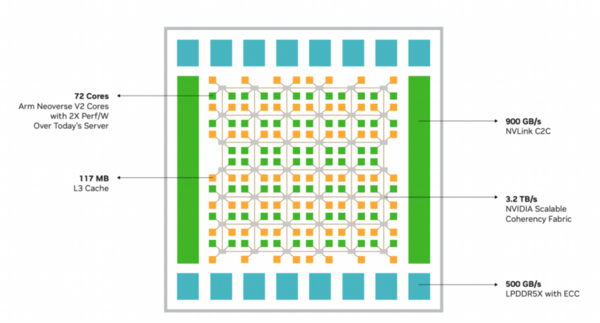
Graceの実装模式図
それぞれが32bit幅になっており、LPDDR5Xは最大8533Mbpsの製品があるものの、実際は8000Mbpsでの利用となっており、以下の計算のとおり512MB/秒という帯域になっていた。
8000(Mbps)×32bit×16=512MB/秒
一方のVeraであるが、下の画像にあるようにSOCAMM2を利用している。SOCAMM2は128bit幅のモジュールであるが、Vera Rubin SuperChipの写真を見るとこのSOCAMMを8本装着できるようだ。つまりメモリーバス幅はGrace世代の512bitから1024bitに倍増している格好だ。

Veraの概要。基調講演と似ているが、チップの上下が逆になっているのと、SOCAMMを利用していることが明示されている

Vera Rubin SuperChipの写真。写真が不鮮明だが、Veraの両側にSOCAMM2のスロットが4つずつ並んでいることは確認できる
信号速度は、2025年10月にMicronが発表したSOCAMM2のサンプルは9.6Gbpsとなっている。これをそのまま使うとすると以下の計算になる。
9600(Mbps)×1024bit=1228.8MB/秒
これが下の画像に出てくる1.2TB/sになるわけだ。ちなみにMicronのサンプルは192GBになっており、これが8本で1536GBなので、容量1.5TBという数字もクリアする。

前ページにも掲載したVeraの主要な特徴
ところで上の画像のダイ部分を拡大して、それぞれの構造を区分けしてみた推定図が下図である。おもしろいのが横7列、縦13列というあまり見ない構造になっていることで、物理的なコア数は7×13=91コアである。おそらく冗長コアが3コアで有効88コアということだろう。モノリシックなダイなので、歩留まり向上を目的とした構成と考えられる。
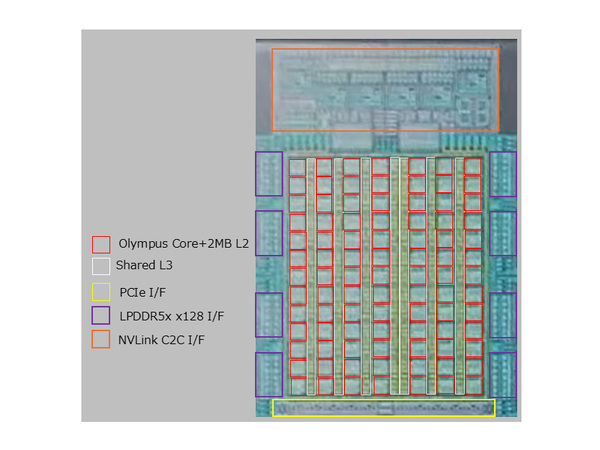
Veraの構造推定図
わからないのがL3ある。162MBという構成はあまり類を見ない。実は上図も結構悩んだのだが、白で囲った部分(図ではL3としている)が、実はL2ではないか? という疑いも捨てきれないでいる。
下の画像は無理やり拡大したものだが、L3とした部分とダイの部分で切れ目が微妙に違っているようにも見えるので、図ではここをL3としたのだが、だとするとL3部分は縦方向に1本あたり24MB、これが7本あるので168MBになるのだが、使っていない6MB分ある、というあたりだろうか?

CPUコアの切れ目とL3(と思しき部分)の入れ目が一致しているところと一致していないところがあるあたり、L3の部分はCPUコアとは独立しているものと思われる
先のGraceの実装模式図(本ページ冒頭の図)でも、L3は縦7列、横12列構造でそのままだと7×12で84個のL3ブロックがあるのだが、実際には12個分の空白があり、合計72個。それぞれが1.625MBの容量を持ち、合計で117MBという不思議な構成なので、VeraもRubinと同じ構造になっている可能性がある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























