



データ・エコシステム構築の未来まで語られたprimeNumberイベント・セッションレポート
サイバー攻撃を乗り越えたのはニコニコだけじゃない KADOKAWA、データ基盤移行の舞台裏
2026年01月14日 08時00分更新

“データ基盤を超えた”データマネジメント環境の構築を目指す
最後に語られたのが、データ基盤における次なる挑戦だ。現在進めているのが、「データ・ファブリックによる論理的なデータ統合」だという。
データ・ファブリックとは、物理的にではなく論理的にデータ統合を図るアーキテクチャだ。ひとつのデータレイクにすべてのデータを集約するという中央集権型アプローチを脱却して、コントロールプレーン(メタデータの集約)とデータプレーン(データ連携)による分散型アプローチへと移行を図る。「グループ内の企業や事業のデータを、ひとつのデータレイクに統合するのはもはや厳しい」(塚本氏)
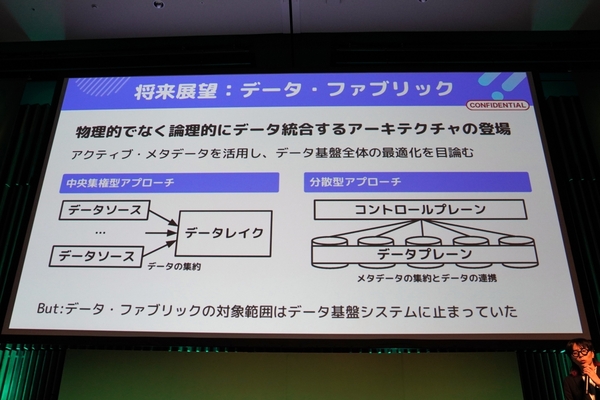
中央集権型アプローチから分散型アプローチへの移行
そして中長期的には、生成AI活用を見据え、データ・ファブリックの適用範囲をデータ基盤外にも広げる「データ・エコシステム」の構築を目指していくという。
生成AIでは、データ基盤外の非構造化データも対象とする必要があり、それらを従来型のデータレイクにコピーするのは現実的ではない。そこで、データプレーンのひとつのコンポーネントとしてデータ基盤外のオフィスデータやメディアデータを扱う。こうして、データ基盤を超え、グループ全体のデータマネジメントが可能なインフラを実現する計画だ。

データ基盤を超えたデータマネジメント環境の構築
このようなデータ・ファブリックの構築で期待しているのが、今回データ基盤にも採用したTROCCOだ。塚本氏は、「分散型アプローチでは、システム間のデータ連携がますます重要になる。iPaaSのようなコンポーネントが必要となる中で、幅広く柔軟なETL/リバースETLに対応するTROCCOに、今後も期待していきたい」とコメントした。



