



データ・エコシステム構築の未来まで語られたprimeNumberイベント・セッションレポート
サイバー攻撃を乗り越えたのはニコニコだけじゃない KADOKAWA、データ基盤移行の舞台裏
2026年01月14日 08時00分更新

移行成功に導いた“構成ギャップの最小化”
具体的な復旧と移行の詳細は、同チームの中野貴文氏が振り返った。

KADOKAWA デジタルマーケティング局 データマネジメント部 データモデリング課 中野貴文氏
まず、Snowflakeのプライベートクラウドで稼働していたのは、データ収集用のFluentdクラスタ(ストリーミング型)やEmbulkクラスタ(バルク型)、データ加工(ETL/ELT)用のAirflowクラスタ、そしてBI基盤であるTableau Serverだ。
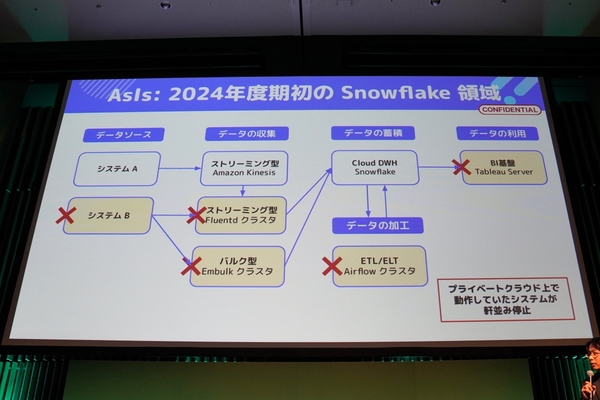
インシデント前のSnowflake基盤のアーキテクチャ
一方、Snowflakeに統合するTreasure Dataでは、データ収集向けにJavaScript SDKによる接続(ストリーミング型)や純正データコネクターである「Integrations Hub」(バルク型)を、ETL/ELT向けにTreasure Workflowを採用するなど、大部分をTreasure Dataの機能で構成する形を取っていた。
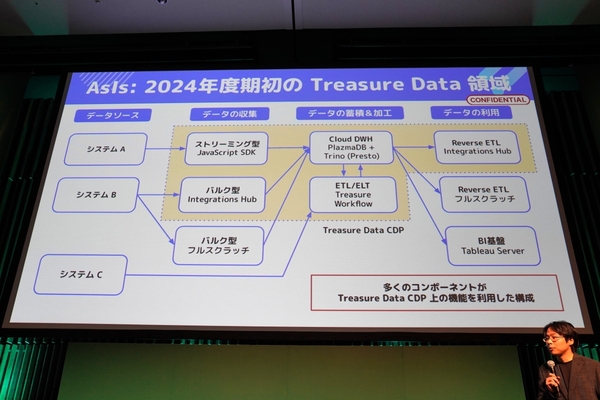
移行前のTreasure Data基盤のアーキテクチャ
このように、Snowflakeの復旧とTreasure Dataの移行を同タイミングで進める中で、どのような周辺サービスを採用したのか。時間的な制限が厳しいため、「構成ギャップの最小化」を意識して、同領域から低コストで移行可能な“折衷案”を模索したという。
この方針を基に、基本的なSnowflakeのアーキテクチャを見直した。データ収集のストリーミング型では「Amazon Kinesis+Fluentdクラウド on AWS」、バルク型ではprimeNumberのデータ連携サービス「TROCCO」を採用。ETL/ELTには「Amazon MWAA(Managed Workflow for Apache Airflow)+ AWS Step Functions」を、BI基盤はTableau Serverから「Tableau Cloud」へ移行している。代替となるサービスとして、AWSのマネージドサービスやTROCCOなどに移行した形だ。
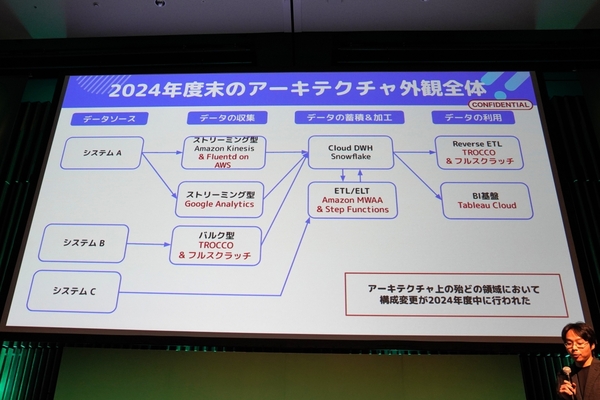
新しいSnowflakeのアーキテクチャ
ポイントとなったのは、データの収集(バルク型)における「TROCCO」と、ETL/ELTにおける「Amazon MWAA+AWS Step Functions」だ。
TROCCOに関しては、サイバー攻撃前から、Treasure Dataのデータコネクターからの有力な移行先として検証していたという。従来通りにWeb UIで設定できて利用感のギャップがなく、内部エンジンもEmbulkで変わらず、技術的なギャップも小さい。そして、Amazon S3やMarketo、SFTP、BigQueryといった想定するワークロードに対応するコネクタも標準で用意されていた。
「当初は、Amazon Appflowも候補に挙がっていたが、LTSV形式に対応していないなど、利用用途に合わない部分があって、選択肢から外れた」(中野氏)

データ収集(バルク型)でのTROCCOの採用
一方のETL/ELTは、移行元のワークロードから決定した。旧基盤のTreasure WorkflowとAirflowクラスタをみてみると、ワークフローエンジン内で処理していた「リッチなワークフロー」(Pythonによるフルスクラッチ処理)と、ワークフローエンジン外で処理していた「シンプルなワークフロー」(SQLクエリやAWS Glueジョブ)に分類できたという。
そこで、移行先も2つの要件で検討し、柔軟な処理が得意(リッチ)なAmazon MWAAと、定型処理が得意(シンプル)なAWS Step Functionsの組み合わせを選択した。
Amazon MWAAは、Treasure Workflowからの移行ギャップはあったもの、マネージドでインフラ管理の手間が少ない点や、Airflowクラスタからの技術ギャップの小ささから決定した。AWS Step Functionsは、「MWAA以上に管理の手間が少ないのが大きなメリット」と中野氏。宣言的に記述が可能な点も決め手になったという。

ETL/ELTにおけるAmazon MWAA+AWS Step Functionsの採用
こうした様々な意思決定を経て、Snowflakeの復旧とデータ基盤の統合は無事完了。ギャップの少ないサービスを選択して、アーキテクチャをスムーズに構築できたことが、移行成功に寄与したという。
一方で、データの移行作業はチェックなどが必要なため、泥臭く人力で行われている。サイバー攻撃からの復旧データとTreasure Dataからの移行データは、あわせて600点を超えたが、計画立てて地道に進められた。



