



ロードマップでわかる!当世プロセッサー事情 第856回
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析
2025年12月29日 12時00分更新

NVLink6の帯域が260TB/秒なのに対して
NVLink7の帯域が1.5PB/秒まで増えている謎
問題は次のRubin Ultra世代だ。これはどういう構成になるのだろう? 下の画像を見ると、4段に分かれておのおの縦方向に18枚づつブレードが刺さっているのがわかる。GTCにおいて、この縦挿しのものがCompute Bladeであることが明らかになっている。つまりCompute Bladeは18×4で72枚である。

前ページより再掲。4段に分かれておのおの縦方向に18枚づつブレードが刺さっている
NVL576は名前の通り576個のRubinのダイが搭載されているので、ブレードあたり8ダイという計算になる。Rubin Ultraは1チップで4ダイ。すなわちRubin Ultraが2チップで、これにVeraが追加されて1枚のブレードという可能性が高い。COMPUTEX TAIPEIの取材で中山智氏が撮影した写真を拡大して注釈をつけたのが下図である。

つまりSuperchipの形ではもはや収まらず、Blade全体でRubin Ultraが2チップ構成になったのだろう。といっても、最終的にCompute Blade1枚あたりRubinのダイが8つということそのものは変化がない。
NVL72/144では18枚のCompute Bladeで構成されていたのに、NVL576では72枚のCompute Bladeまで増えているため、ダイ数は4倍になっているわけで、性能がNVL144の4倍になっていることそのものは別に不思議ではない。不思議なのはNVLinkの合計帯域である。
記事冒頭の画像ではNVLink6の帯域が全部で260TB/秒であるとされているが、下の画像ではNVLink7の帯域が1.5PB/秒まで増えていると記載されているのが謎なのである。

NVLink7の帯域が1.5PB/秒まで増えている。12XというのはNVL72との比較の数字である
先程と同じ計算をしてみよう。Rubin UltraはRubin×2の4ダイ構成になっているので、1つのパッケージからは最大72本のNVLinkが出せる計算だ。つまりCompute Bladeあたり144本。ブレードは72枚なので、144×72=10368本であり、NVLink 1本あたりが100GB/秒なのでトータルで1.0368PB/秒にはなる計算で、1.5PB/秒には少し遠い。
上図ではオレンジ色で154pinコネクター×4と書いた。中山智氏撮影の写真では左端に見切れているのだが、Kyberでは新しいMidplaneという基板を用意しており、ここに154pinコネクターを18列×4段に並べ、そこに直接Compute Backplaneを差し込む方式になっている。
それ以外にも冷却液や電源も、全部バックプレーン側に差し込むとそのまま使えるようになっており、NVLinkは154pinコネクター×4を通してMidplaneにつなぐ形で利用される。
仮にRubin Ultraは全部で72 LinkのNVLinkを出せると仮定する。1本のNVLinkは2ペアのDifferential信号なので72×2×2=288本。Compute BladeにはRubin Ultraが2つ搭載されるから、288×2=576本の信号ピンが必要である。
154pinコネクター×4では616pinが使えるから、72 LinkのNVLinkを出すには十分である。逆に言うと、これ以上のNVLinkを出すのは難しいことになる。
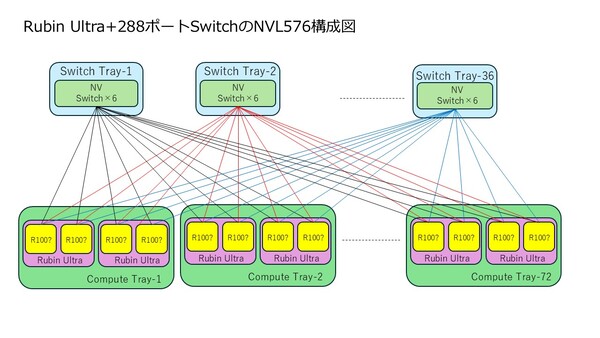
下図はNVLink Switch Bladeの方だが、こちらも構造はよく似ているが、後端のコネクターが×6になっており、NVLink Switchが3つないし6つ搭載されているのか? と考えてしまう。
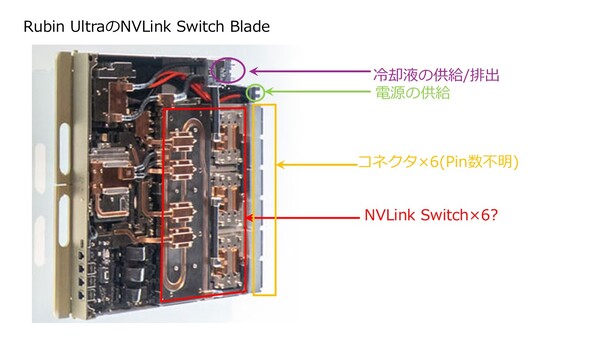
そもそもRubin世代までのNVLink Switchは72ポートだった。GPUの数が72個なので、これと辻褄があっている。ところがRubin Ultra世代ではGPUの数が144個になる。内部的には2GPU構成なのでGPUの数としては288個相当になる。これはポート数が絶対的に足りないわけで、すべてのGPU同士を1 Hop(GPU-NVLink Switch-GPU)でつなぐのがこの時点で無理という計算になる。したがって、NVLink Switchを複数介してPeer-to-Peerではなく2 Hopで接続する形態が考えられる。
2 Hopの場合、スイッチそのものは見かけ上288ポート必要になる。もっとも、実際にどうなっているかはまだ確定できない。考え方としては、288ポートのスイッチを作る場合と、144ポート×2を作る場合が考えられる。
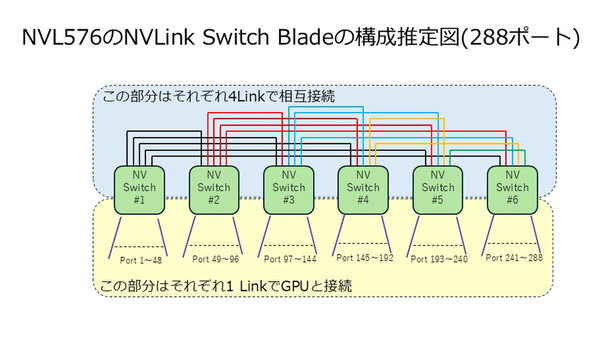
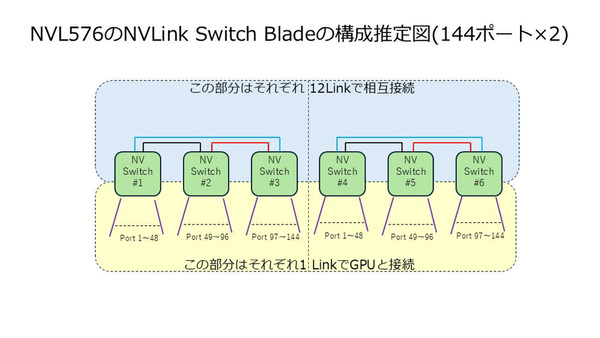
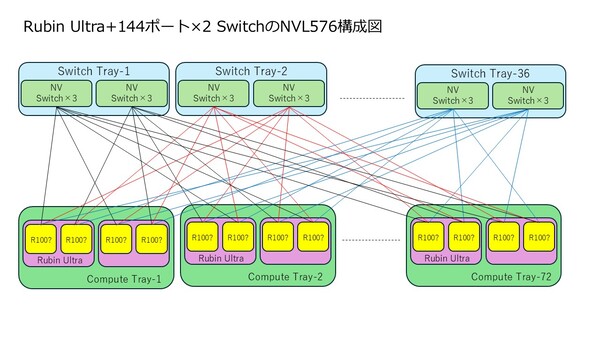
どちらも72ポートの72ポートのNVLink Switchのうち48ポートはRubin Ultraと接続、残り24ポートをほかのスイッチとの相互接続に利用する形となる。288ポートの場合、NVLink Switch Blade1枚あたりの帯域は68×6×100GB/秒=40.8TB/秒。144ポートの場合は72×3×2×100GB/秒=43.2TB/秒となる。前者なら36枚搭載すると1468.8TB/秒、後者なら1555.2TB/秒になり、どちらも丸めると1.5PB/秒という計算になる。
144ポート×2の場合と288ポートの場合の接続方法をそれぞれ示す。このどちらの構成図が正確なのか、というのは現時点で断言できる情報がないので、今後への持ち越しになるだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































