



ロードマップでわかる!当世プロセッサー事情 第855回
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術
2025年12月22日 12時00分更新

電線の本数が限界に近い
RubinベースのNVL144では1万368本になる見込み
前回のNVL72のNVLink接続図でも説明したが、たかだか72台のGPU同士の接続に必要なNVLinkの本数は1296本。前回は説明しなかったが、NVLinkは当然双方向であり、かつ電気信号ベースということで1リンクの配線本数は、DifferentialかつBi-Directionalなので4本であり、電線本数は4倍の5184本に達する。
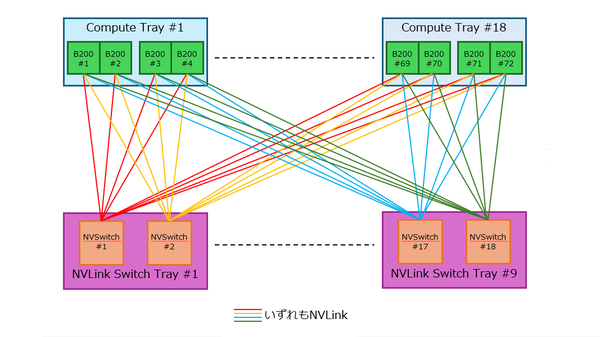
72台のGPU同士の接続に必要なNVLinkの本数は1296本
実際には複数リンク分の配線をまとめているはずなので、外から見える電線の本数はもっと少ないだろう。だから、表からみると整然とシャーシが並んでいるのに、裏は配線お化けになっているわけである。
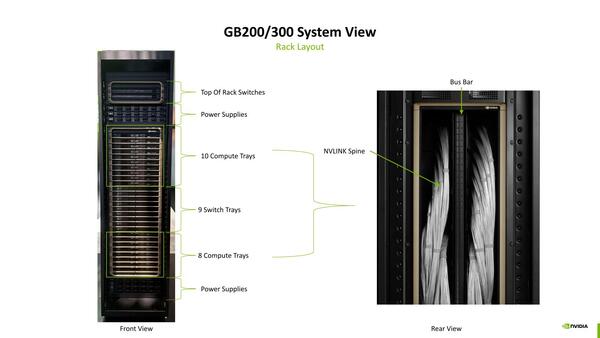
裏は配線だらけ
72台のGPU同士でこれなわけだが、昨今のクラウド推論の動向では、さらに大規模な構成が要求されつつある。やや前の話になるが、2023年5月にNVIDIAがDGX GH200 AI SuperComputerを発表した。構成は下の画像のように、GH200を16枚装着したラックを16本並べた構成である。

DGX GH200 AI SuperComputerは、GH200を16枚装着したラックが16本並ぶ
このケースでは、1つのラックの中のGH200同士をNVLinkで相互接続し、さらに16本のラックの間はInfiniBandないしイーサネットで接続する形態となる。これをもう少し一般化したのが下の画像だ。
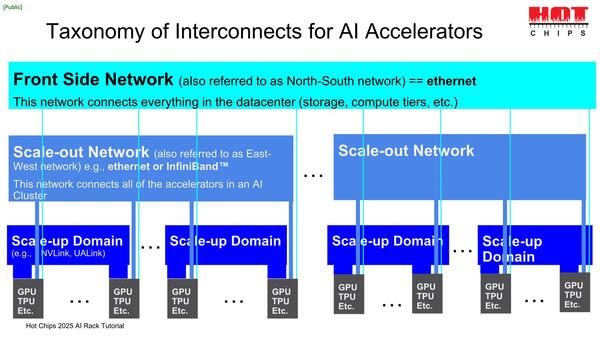
Scale-upは密結合のネットワークで、NVIDIAならNVLinkを、AMDその他は現在UALinkの採用を進めている最中である。これは通常ラック内ないし隣接ラック程度に留められる。より広範囲な相互接続はScale-outになる。Front Sideは管理などのために使われる
別の例で示せば、GoogleのIronwoodの場合、64個のIronwood同士は4×4×4の密結合のキューブで相互接続され、これがScale-upに相当する。
キューブ同士もやはり3次元のトーラス形状での相互接続になるのだが、論理的にはトーラスと言いつつ物理的にはPalomar OCSを使って接続されるという話は連載729回で説明した。しいて言えばこのPalomar OCSを使う分がScale-outに相当することになる。
最近は大規模モデルを稼働させる場合にもいろいろと工夫が凝らされている。特にDeepSeekで話題になったのがMoE(Mixture of Experts)という技法で、計算量を減らし効率的に処理する方法として注目されつつあるが、MoEを使う場合には以下の使い方になることが多く、ネットワークもこれに対応する必要がある。
- MoEでは1つのScale-up領域で全部のリソースを使うことはないので、複数のモデルなり推論なりを1つのScale-up領域で走らせられる。
- その一方で、複数のScale-outにまたがる形で処理する
MoEですべて解決するわけではなく、依然としてScale-upの領域をフルに使いつくすようなモデルも少なくないので、より大規模なScale-upの能力も引き続き求められていく。
例えば下の画像はNVL72の模式図であるのだが、NVIDIAは次世代でRubinベースのNVL144の提供を予定しており、配線もおそろしい(1万368本のNVLinkによる相互接続になる)うえ、スイッチだけで12本ものシャーシを占有することになり、Scale-upの限界が近いとしている。

NVL72の模式図。これはAMDのDarrin Vallis氏(Datacenter Solution Architect)の"Scaling fabric technologies"という講演のスライドなので、当然NVIDIAとNVL72といった名前は出てこない
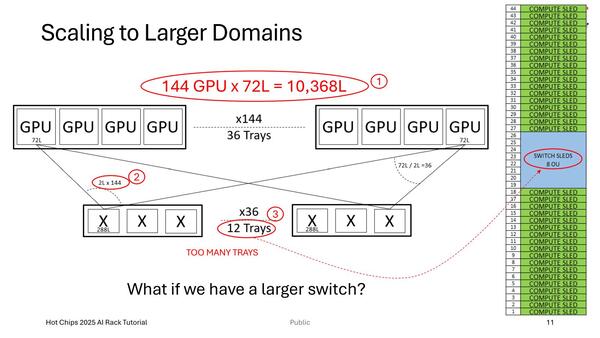
あくまでもVallis氏が想定するNVL144の構成である。といってもある程度公開情報に基づくものなので、そう間違ってはいないだろう
ちなみに解決案の例として提示されたのがL1.5という、スイッチ同士の相互接続をともなうアイディアである。ではNVIDIAは次世代のRubin Ultraでどうするつもりなのかを次回説明したい。
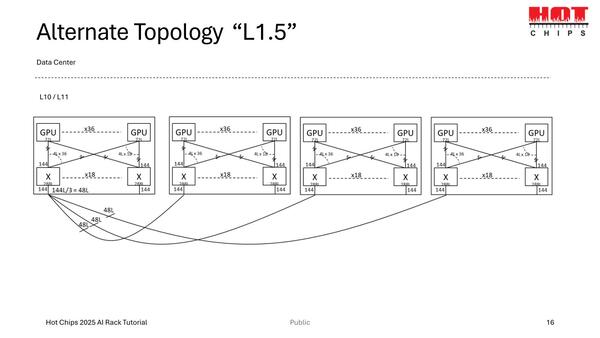
GPU同士を全部1 Hopで接続するアイディアを捨て、36 GPUを一つの小さなドメインとして、ドメイン同士をスイッチで相互接続する。これなら1 Hopの場合と2 Hopの場合が混ざるので、GPU同士は平均1.75Hopほどで接続できる
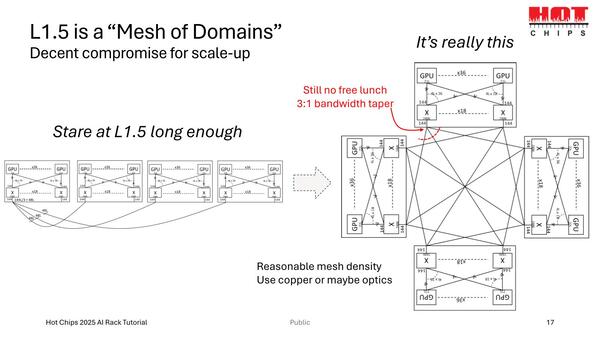
トポロジーとしては上の画像と一緒だが、物理的な配線長をより短くできる(≒消費電力を減らせる)メリットはある。しかし、ラックを十字型に配して最短経路で配線しようとする作業が困難極まる。最悪配線が終わった後、配線している作業員が閉じ込められて即身仏化するのが問題な気がする。メンテナンスも大変そうだ
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ























の1台が今ならオトク!")
























")













