



ロードマップでわかる!当世プロセッサー事情 第853回
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術
2025年12月08日 12時00分更新

3種類の新たなプロセッサーが連携して処理を実行する
Glasses Processor内部の処理の流れが下の画像である。結構激しく共有メモリーを介してデータをやり取りしており、逆に言えば共有メモリー内部でこうした動きを抑えられているからこそ低消費電力で抑えられているということなのかもしれない。
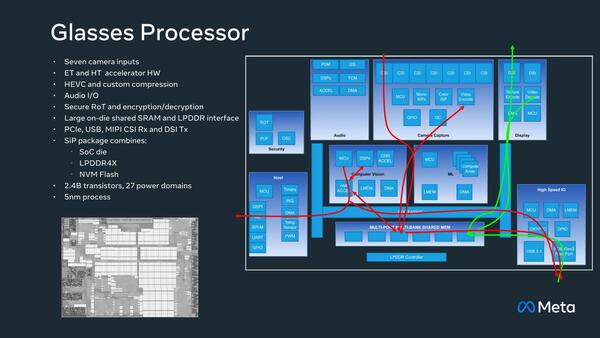
その代償はおそらくARイメージの解像度の低さである。実際デモ画像を見ても、あまり解像度が高いようには見えなかった。多分解像度を上げると共有メモリーでは足りずにLPDDR4xを使うことになり、消費電力増加はフレームレート低下が発生するのであろう
次がDisplay Processorである。こちらは最終的な映像イメージをARグラス内部の液晶に投影する作業がメインであり、それほど複雑な処理は必要ない……はずであるが、それでもこちらも結構大規模なSRAMを搭載しているのは、Reprojection(左右別にイメージの再生成:カメラ画像にARイメージを重ね合わせ)に相応の処理が必要になるためと思われる。
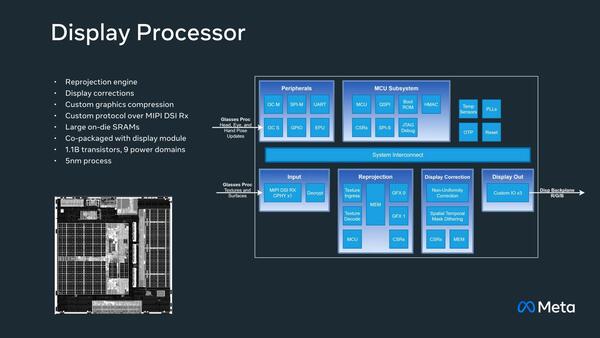
音声入出力もこのDisplay Processorが担っていることがわかる。配置を考えればこれは当然だろう
とはいえトランジスタ数は11億個とGlasses Processorの半分未満のサイズに収まっている。Boot ROMがMCU Subsystemに置かれているのは、このBoot ROMが起動して外部I/F経由で(おそらくGlasses Processorに積層されたNVM Flashから)プログラムを読み込む形になっているのだろう。
これによりDisplay Processorは無駄にパッケージサイズを大きくすることなく実装できる(ダイサイズは10mm2未満だろう)ものと思われる。
もう1つがCompute Coprocessorである。ここが処理のメインとなる部分で、前ページ最初の画像で言えばCompute DepthとCompose and Projectionの大半、Audio Spatial Renderingの大半がここで行われることになると思われる。
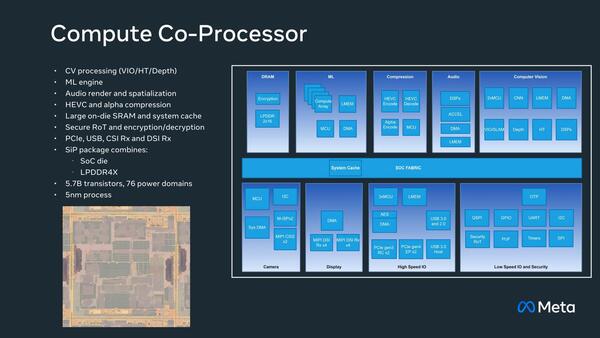
トランジスタ数は57億個なのでダイサイズも相応に大きくなっている(51mm2程度?)と思われるが、それよりもPower Domainが76もあることに驚きである。そこまでPower Gatingをしなければいけないほどに省電力化へのニーズが高いということである
少し気になるのは、Glasses ProcessorとCompute Coprocessorの両方にComputer VisionとMLユニットが搭載されていることだ。消費電力を考えると、Glasses Processorの方ではそれほど多くの処理はせず、メインはCompute Coprocessorで処理することになると思うのだが、であればなぜGlasses Processorの方にもComputer VisionやMLが含まれているのかという話である。
おそらくは、Compute Coprocessorに送って処理して戻すのではレイテンシーが大きすぎるような処理があって、それをGlasses Processorで処理することで見かけ上のレイテンシーを低く抑えるというあたりが目的だろうとは思うのだが、具体的にどんな処理がこれに該当するのかが想像できない。残念ながら講演の中でもそうした細かい話は説明されなかった。
下の画像が処理フローであるが、これを見る限りホストとなるApplication Processorとは普通にPCI Expressと接続されているようだ。またARのイメージそのものはApplication Processorで生成され、その映像がMIPI DSI経由で取り込まれる格好になっているとみられる。
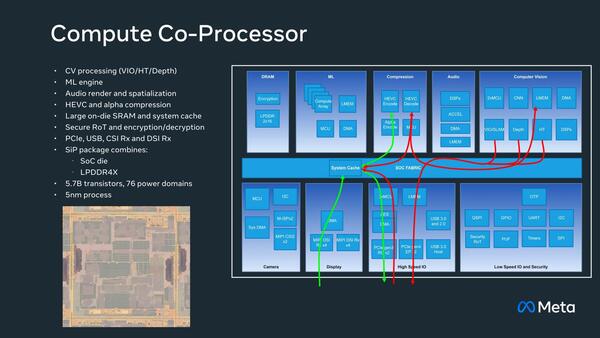
High Speed I/OのブロックにLMEM(Local Memory)が入っているというのは、Local Memoryの主な用途はI/Oのキャッシュということになる。ただブロック図を見ると、そこまで大きなSRAMブロックはないように見える
これらを駆使することで、AR体験を実現可能になったわけだが、確かにこれはこのまま商品化するのは難しいかもしれない。少なくともAR Imageの解像度でフルHDはほしい(現状はSD解像度+α程度?)し、バッテリー寿命がどの程度かも一切公開されていない。

この画像からも、AR Imageの解像度がそれほど高くないことが見て取れる
また示された動画も、頭をそれほど激しく動かしておらず、すでに販売されているVR Glassほどの動作追従性があるかどうかは怪しい。とはいえ、製品化前の試作品のためにわざわざ5nmでカスタムチップを3種類も製造するという莫大なコストをかけているあたりにMetaの本気度も伝わってくるわけで、将来の製品版ではさらに内部構造が洗練されてくるのかもしれない。
いずれにせよ、AR Glassを実現するためにはこの程度のシステムが最低でも必要になる、という実装例が示されたことは興味深いと言えるだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































