



さくらインターネット、学習・推論の両輪でクラウドサービスを早期拡充
スパコン「さくらONE」がNVIDIA B200追加 H200との混在で生成AI+HPCをカバー
2025年10月22日 08時00分更新

さくらインターネットは、2025年10月20日、マネージドスーパーコンピューターサービス「さくらONE」において、NVIDIAのBlackwellアーキテクチャによる最新GPU「NVIDIA B200 GPU」を提供開始した。

さくらONEは、ひとつのシステムでNVIDIA B200 GPU(最大384基)とNVIDIA H200 GPU(最大440基)を使い分けられるヘテロジニアス(異種混在)構成に対応し、AI開発から先端研究まで、幅広いユースケース向けに高性能な計算リソースを提供する。
さくらインターネットのAI事業推進室 兼 さくらインターネット研究所の上級研究員である小西史一氏は、さくらONEについて、「単なるマネージドHPCクラスタのサービスというだけではなく、われわれのミッションである『計算力を提供するインフラを民間から整備して、誰もが付加価値を創れる社会』を実現するためのサービス」と説明した。
さくらインターネットが生成AI向けクラウドサービスを拡充する理由
日本社会と産業の発展に資するべく、AI計算資源の安定供給を目指すさくらインターネット。現在、AIインフラの整備とその計算資源を基にした生成AI向けクラウドサービスの拡充に注力している。
AIインフラの投資計画は、第一段階として2024年8月までに「NVIDIA H100 GPU」を2000基設置(その後840基を増強)。そして、現在進行中の第二段階では、2027年度までに総GPU数を「1万基」、総計算能力(第一段階ぶんも含む)を「18.9EFLOPS」まで到達させる計画だ。
第二段階の現時点までの進捗は、NVIDIA H200 GPUを1072基、さらにNVIDIA B200 GPUを約400基設置済みだ。石狩データセンター内のコンテナ型データセンターの稼働とあわせて、これらを生成AI向けクラウドサービスとして展開している。なお、NVIDIA B200 GPUは約1100基を増強予定であり、今後も需要に応じて次世代GPUを継続して採用していく方針である。
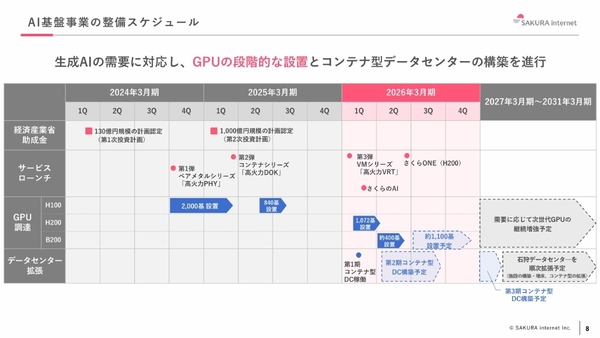
AI基盤事業の整備スケジュール
一方、生成AI向けクラウドサービスとしては、これまで高火力シリーズであるPHY・VRT・DOKを提供してきた。加えて直近では、「学習(AI開発)」と「推論(AI利用)」の2つの用途向けのサービスを拡充した。ひとつは、推論用途向けに展開するビジネス基盤「さくらのAI」だ。2025年9月には、第1弾サービスとして、推論API基盤「さくらのAI Engine」を一般提供している。
そして、同じく2025年9月に、学習用途向けとして提供開始したのが、NVIDIA H200 GPUを搭載したマネージドスーパーコンピューター「さくらONE」である。今回このさくらONEに、最新GPUであるNVIDIA B200 GPUによる構成が新設されている。
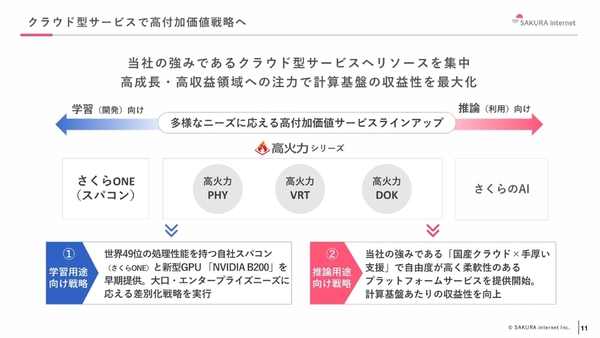
生成AI向けクラウドサービスの位置付け
このように同社がクラウドサービスを拡充する背景には、予想を超える勢いで推論ニーズが拡大していることがある。同社のAI事業推進室 AI基盤事業統括である須藤武文氏は、「当初は、開発における学習ニーズが先にきて、その下流である推論に振り替わっていく流れを想定していた」と語る。
それが、生成AIの活用フェーズが急速に本格化することで、学習と推論のニーズが同時に高まり、さらには事業者による競争も激化。「少数の事業者による、大規模投資を分け合うような市場を予想していたが、今は事業者が入り乱れている状態にある」と須藤氏。
そして、玉石混交なサービスが提供される中で、国産プラットフォームに対しては、特に要件が厳しい日本の組織から、信頼性や質、価格といった多角的な要求が高まっているという。
こうした背景を受け、同社は、先行準備していた多様な生成AI向けクラウドサービスを早期に市場投入している状況だ。なお、同社は体制的にも対応すべく、AI事業に関する機能をひとつの部門に集約。2025年8月に、戦略や企画、開発、営業が一気通貫で連携するための「AI事業推進室」を新設している。
“ヘテロジニアス(異種混在)構成”でAIと科学技術計算の両領域をカバー
この生成AI向けクラウドサービスのひとつである「さくらONE」は、さくらインターネットが運用するスーパーコンピューターの計算資源を国内から提供する。スーパーコンピューターは、石狩データセンター内のコンテナ型データセンターで構築されており、LLM学習や生成AIの研究開発に特化した設計となっている。
今回、従来提供していたNVIDIA H200 GPUを8基搭載したサーバーを最大55台、計440基の構成をとる「NVIDIA H200 GPUモデル」に加えて、NVIDIA B200 GPUを8基搭載したサーバーを最大48台、計384基の構成をとる「NVIDIA Blackwell GPUモデル」を追加している。
また、計算資源だけではなく、計算ジョブの管理機能(ジョブスケジューラ)やアカウント管理、障害時のノード交換対応など、計算環境の立ち上げから運用管理までをカバーするマネージドサービスとして提供される。HPC環境向けに開発されたSingularityコンテナも利用でき、保持していた計算を持ち込むことも可能だ。利用期間は最低30日から、1日単位で利用でき、計画的な利用だけでなく、試験導入や段階的なスケーリングにも対応する。
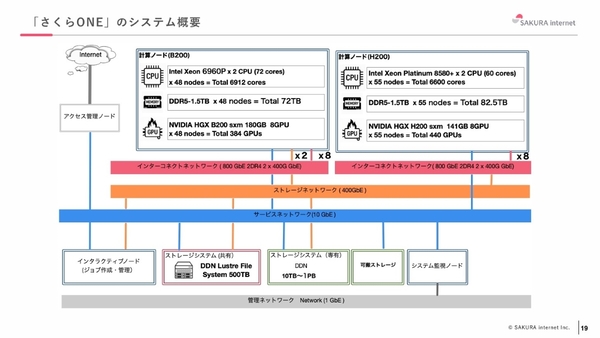
「さくらONE」のシステム概要
さくらONEが、他のGPUスーパーコンピューターと異なる点は、ひとつのシステム内でNVIDIA B200 GPUとNVIDIA H200 GPUの計算ノードを使い分けられる“ヘテロジニアス(異種混在)”構成に対応することだ。両計算ノードが共有するストレージシステム(Luster File System)も用意される。
さくらインターネットの小西氏は、NVIDIA B200 GPUはメモリサイズの違いからより生成AI・LLM学習に向いており、NVIDIA H200 GPUは科学技術計算で優秀に働くとして、「両者の良いところを取り入れられるバランスがとれた仕組み」と説明する。
また、同社のデータセンター運用のノウハウにより、GPUをフルパワー電力(NVIDIA B200 GPUは1基につき1000W、NVIDIA H200 GPUは1基につき700W)で利用可能な点も特徴として挙げられた。
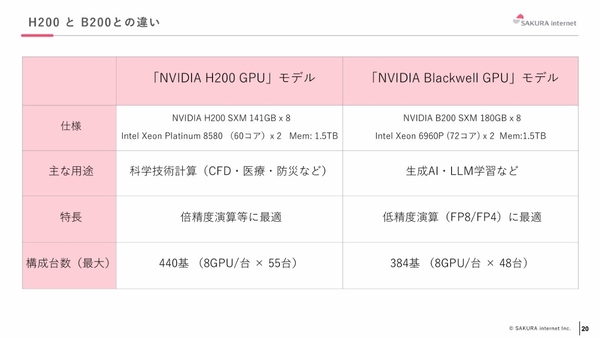
NVIDIA B200 GPUとNVIDIA H200 GPUとの違い
さくらONEのマネージドスーパーコンピューターは、「2024年内閣府戦略的イノベーションプログラム(SIP)」第3期における医療LLM開発のために自社構築したものを、技術を再構成して商用化したもの。「われわれが、実際にLLMを開発するのに不可欠なシステムとして、高火力PHYをベースとしたマネージドHPCクラスタを組み立てていた」(小西氏)
また、スーパーコンピューターの国際的な処理性能ランキングである「TOP500」においても、世界49位にランクイン(2025年6月)している。次回のTOP500にもエントリー予定だという。



