



ロードマップでわかる!当世プロセッサー事情 第845回
最大256MB共有キャッシュ対応で大規模処理も快適! Cuzcoが実現する高性能・拡張自在なRISC-Vプロセッサーの秘密
2025年10月13日 12時00分更新

複雑なスケジューリング機構を廃し
消費電力を下げる
Time-Basedマイクロアーキテクチャーを採用した理由は、スケジューリングの最適化を容易にすることで、複雑なスケジューリング機構を廃し、結果的に消費電力を下げることにある、としている。

「How to handle dynamic behavior of general-purpose compute?」(汎用計算で、どうやって動的な命令の振る舞いを(time-baseで)制御できるのか?」の答えがおもしろい。要するに「これまでもできてなかったじゃん」である。まぁ、その通りだ
先に書いた「発行できる命令を即座に発行可能キューに叩き込んで実行ユニットに送り出す」のところは実際にはいろいろ省いている。通常キューには、実行可能な命令が複数並んでおり、それをどういう順番で送り出すかというのは結構難しい。しかもそれによって性能が変わる場合もある。これを簡単化できる、というのがCondorの主張である。
この性能に関しては、Spartaというモデリング/シミュレーションツールの上でolympiaというRISC-V Out-of-Orderプロセッサー用のモデルを利用して検証を開始したとしており、この結果がいくつか示された。

olympiaでの検証結果。もっともOlympiaは開始地点であって、そこからCuzcoにあったモデルを構築していった
まず絶対的なパフォーマンスで言うと、従来型のスケジューラーに比べると5%ほどの低下を示すが、その一方で回路および消費電力を大幅に節約できたとする。またSliceの数と性能の比較が下の画像で、4スライスがちょうどバランスがいいことを示しているとする。
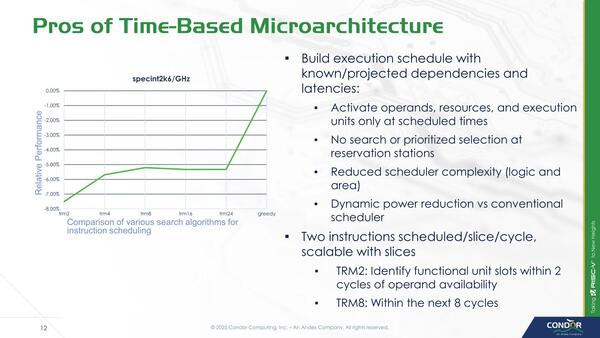
グラフの横軸は何サイクルまで記録するかを示し、8サイクルあたりがピークでそれ以上増やしてもあまり効果がない。ちなみにGreedyは従来型のスケジューラーのもの。SPECint 2006での結果とのこと
キャッシュ構成に関してはわりと自由に構成可能である。L1/L2がコアごとのPrivate CacheでL3がShared Cacheという構成だが、容量はかなり自由に選べるし、L3キャッシュに関しては速度を変更することもできる。
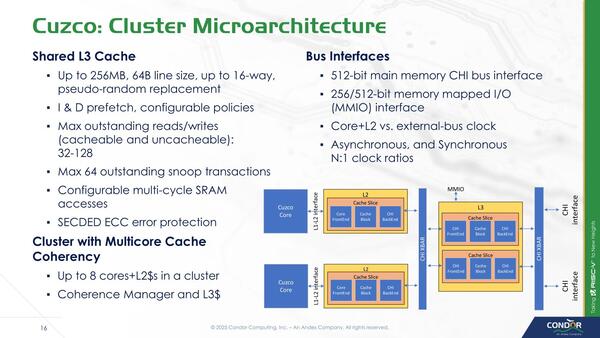
L1は64KB(I/Dともに)固定だが、L2は最大8MB、L3は最大256MBである。キャッシュ・コヒーレンシーはCHIを利用しているのがわかる
実際に親会社のAndes AX65との性能を比較した結果が下の画像だ。
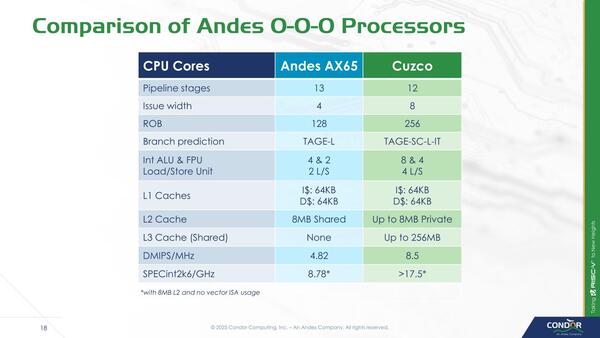
AX65もやはり最大8コアまでのクラスターが組める。このAX65が現在のAndesのハイエンドコアであり、その倍の性能を叩き出せるわけだ
AX65は4 wide decodeのOut-of-Order構成のプロセッサーなので、スペック的にはちょうどCuzcoの半分のサイズである。ただ、規模を倍にすれば性能が倍になることは普通はない(よくて5割増し程度)だから、SPECintの結果がきっちり倍になっているのはなかなか象徴的である。
すでにフロアプランも示されており、コアそのものはTSMCのN5プロセスで1.3mm2ほど、2MBのL2は1mm2なので、コア+L2がだいたい2.3mm2程度。仮にL2を最大の8MBにしても9.6mm2程度で、10mm2未満である。
動作周波数は速度優先で2.5GHz、密度優先で2GHzとやや控えめであるが、こちらは消費電力との兼ね合いもある。ゲート数で言えば700万個とそれほど大きくないサイズでこれだけのコアが実装できたのはなかなか優秀と言っていいだろう。
同じAndesのAX45(2命令同時実行のIn-Orderコア)がCortex-A72程度と言われており、AX65はCortex-7x相当(おそらくCortex-A78まではいかないはず。Cortex-A76あたりだろうか)程度の性能と目されるが、Cuzcoはこの倍になるので、Cortex-X2あたりと場合によっては互角の性能になるかもしれない。
AX65がデータセンター向けのコアという位置づけであり、実際軽負荷のサーバーであれば十分対応できる範疇だが、Cuzcoはクラウドサーバーにも使える程度の性能はありそうだ。といってもクラウド向けには単にコアだけあってもダメで、多数のコアを接続できるCoherent Networkが必要になる。ArmでいうところのCMN-700のようなものだ。今のところCondorではそうしたところまで手は回っていないようで、まずは性能が必要なアプリケーション・プロセッサー向けに活路を見出すつもりかもしれない。
Cuzcoは今年第4四半期からIPのライセンス提供を開始するとしている。さて、これを導入する顧客がどの程度集まるだろうか?
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ























の1台が今ならオトク!")
























")













