



ロードマップでわかる!当世プロセッサー事情 第845回
最大256MB共有キャッシュ対応で大規模処理も快適! Cuzcoが実現する高性能・拡張自在なRISC-Vプロセッサーの秘密
2025年10月13日 12時00分更新

スライスと呼ばれる構造単位で実行ユニットを構成
スライスの構造を示したのが下の画像となる。それぞれのスライスが完全にすべての命令を処理できるようになっている。
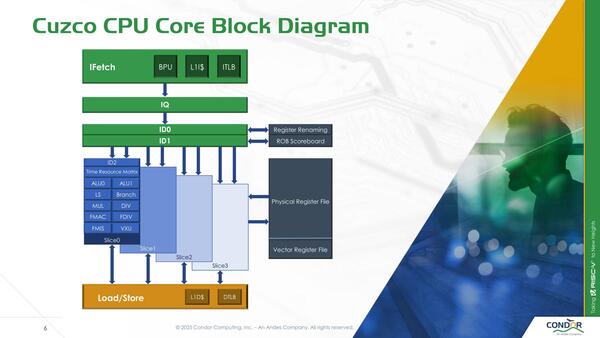
この構造、スライスを減らせば小規模なコアになるし、逆にDecode~ID1の幅を増やしてスライスを追加すればもっと大規模なコアにスケールさせるのも容易である。ただ実装効率としてこのスライス構造が得策なのかはよくわからない
なぜこんな構造になっているか? というと、この後説明するTime-Basedマイクロアーキテクチャーが関係してくる。このTime-Basedマイクロアーキテクチャーを実装するのに8-wideのALUなどの管理をするのは地獄であり、2-wideに絞ることで現実的に可能な仕組みを作ったのではないか、と筆者は考える。
ではそのTime-Basedマイクロアーキテクチャーとはなにか? という話だ。Out-of-Orderの命令発行の仕組みに戻るが、Out-of-Orderではまずデコーダーから流れて来た命令を分解したうえで、発行できる命令を即座に発行可能キューに叩き込んで実行ユニットに送り出す。
依存関係のある命令、例えばメモリーアクセス待ちや別の命令の実行後の値を利用するものなどに関しては待ち行列に並べておき、その依存関係が解消された、つまりメモリーアクセスが終わってレジスターに入った、あるいは前の命令の実行が終わり、結果がレジスターに戻されたなどの段階で、発行可能キューの方に付け替えるという形で処理を進めるわけだ。
ただこの際、どの命令がどのタイミングで発行されるのかはCPU任せになるし、結果として命令がいつ処理が終わるのかもはっきりしない。このあたりはOut-of-Order構造の宿命であり、命令の発行から実行完了までの正確なタイミングを確定させたければ、In-Orderのパイプラインにするしかない。これをもう少し厳密に管理したいというのがTime-Basedマイクロアーキテクチャーのようだ。
Cuzcoのパイプライン構造が下の画像だが、IF(Instruction Fetch)はともかくID(Instruction Decode)のステージに謎の"calculate exection times"という表記が入っているのがこれだ。
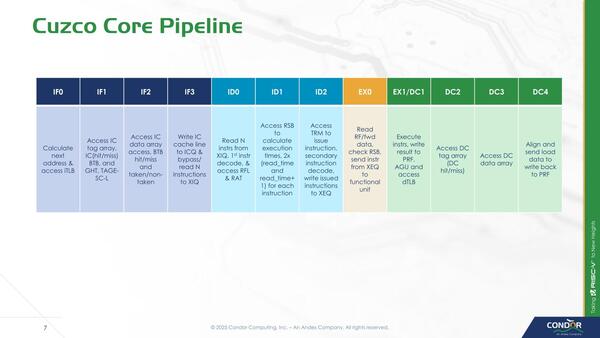
Cuzcoのパイプライン構造。ここではEx(Execute)は全部1サイクルで処理できるように記載されているが、実際には複数サイクルを要するものも当然含まれていると考えられる。DCはData Cacheで、要するに結果をデータキャッシュに書き戻すためのステージだ
これがどう動くか? というのが下の画像だ。Scoreboard、つまり上で「発行可能キュー」と説明したもので、ここで発行した命令の管理をしているのだが、単に「どのExecution Unitになにを発行したか」だけでなく「それをいつ発行したか」も同時に記載するようになっている。

Time-Basedマイクロアーキテクチャーの動作原理。関連特許をすでに10個取得済で、さらに4つを現在請求中とのこと
これにより、その命令がいつ実行し終わるかを予測可能になるため、命令発行時の依存関係解消にどの程度の時間がかかるかを事前に推察でき、これにより効率的な発行ができるという。
下の画像はこれの例で、命令"O"は83サイクル目にスケジュールされ、93サイクル目にイシュー(Read Port)、94サイクル目に実行(Write PortとALU)をそれぞれ行なうとわかるので、これによりリソース(ALUだったりRead/Writeポートだったり)を効率的に使えるとしている。
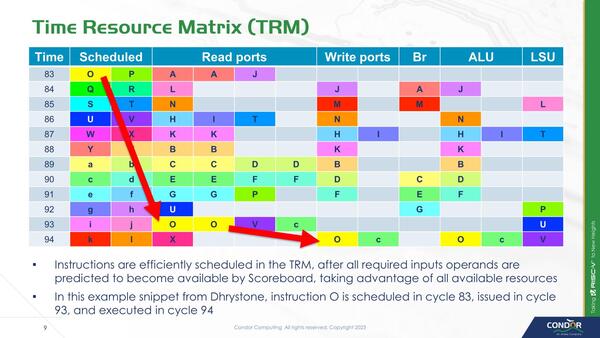
これはDhrystoneを実施した場合の例を示したものだそうだ
先にスライスの話をしたが、もしスライスを利用せずに例えば8個のALUをまとめて制御しようとすると、上の画像の横方向のカラムが4倍に増えることになる。これはスケジューリングには不利だし最適化も難しい。スライスを利用して、制御するリソースを現実的な数に抑えることで、このTime-Basedマイクロアーキテクチャーを実装可能になった、というあたりがスライスの最大の目的だろう。
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ























の1台が今ならオトク!")
























")













