




富士通は、2025年9月8日、LLMを軽量化・省電力化する「生成AI再構成技術」を開発し、同社のLLM「Takane」の強化に成功したと発表した。同技術は、AIの思考を効率化して消費電力を削減する「量子化技術」と軽量化と精度向上を両立した「特化型AI蒸留技術」の2つのコア技術からなる。
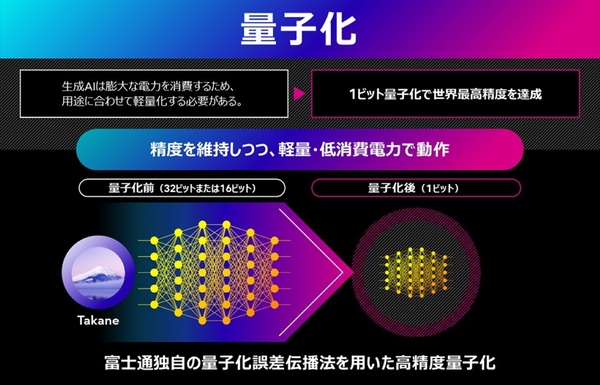
ひとつ目の量子化技術は、生成AIの思考の基となる膨大なパラメータ情報を圧縮し、生成AIモデルの軽量化・省電力化・高速化を実現する技術だ。従来手法では、LLMのような層が多いニューラルネットワークにおいて、量子化誤差が指数関数的に蓄積することが課題だったという。
そこで富士通は、誤差の増大を層をまたいで量子化誤差を伝播させることで防ぐ量子化アルゴリズム「QEP(Quantization Error Propagation)」を開発。さらに、同社が開発した大規模問題向けの最適化アルゴリズム「QQA(Quasi-Quantum Annealing)」を活用することで、メモリ消費量を最大94%削減するLLMの“1ビット量子化”を実現した。
量子化における主流手法(GPTQ)での精度維持率は20%以下であるが、本技術によって1ビット量子化したTakaneは、精度維持率89%と、3倍の推論高速化を達成。これにより、スマートフォンや工場の機械といったエッジデバイス上でのAIエージェントの実行が可能になるという。
量子化技術の概要
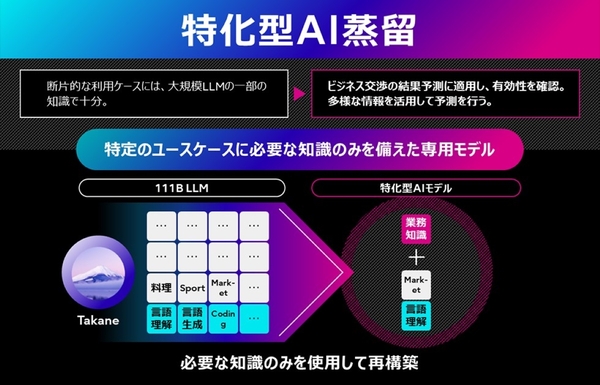
2つ目の特化型AI蒸留技術は、まるで脳が不要な記憶を整理するように、AIモデルの構造を最適化する技術だ。独自のアプローチにより、単なる圧縮に留まらず、特化したタスクにおいて基盤の生成AIモデルを上回る精度を実現する。
まず基盤となるAIモデルに対し、不要な知識を削ぎ落とす「Pruning(枝刈り)」や、新たな能力を付与する「Transformerブロックの追加」などを行い、多様な構造を持つモデル候補群を生成する。次に、これらの候補の中から、独自の「Proxy(代理評価)技術」を用いて、顧客の求めるGPUリソースや速度と精度のバランスが取れた最適なモデルを自動選定。最後に、選定された構造を持つモデルに、Takaneなどの教師モデルから知識を蒸留する。
富士通のCRMデータを基に商談の勝敗を予測する実証では、本技術で蒸留したモデルを用いることで、推論速度を11倍に高速化しつつ、精度を43%改善できたという。また、高精度化とモデル圧縮を同時に実現することで、教師モデルを超える精度を、より軽量な100分の1のパラメータサイズの生徒モデルで達成し、GPUメモリと運用コストをそれぞれ70%削減している。
特化型AI蒸留技術の概要
富士通は、量子化技術を適用したTakaneのトライアル環境を2025年度下期より順次提供を開始する。さらに、同技術でCohereの研究用オープンウェイト「Command A」を量子化したモデルを、Hugging Faceで9月8日に公開した。今後は、生成AI再構成技術を用いて、金融や製造、医療、小売など、より専門性の高い業務に特化したTakaneから生まれる「軽量AIエージェント群」を開発していく予定だ。



