




Passage M-1000はチップの真下から光信号を出せる
Passageの基本的な構造が下の歯像だ。Passageはインターポーザー的な位置付けにあり、パッケージとASICの間に挟まる形になる光インターコネクト層である。おもしろいのはASICの部分にEICが含まれることだが、ASICとEICをどう混在させるのか、あるいは積層するのかは後述する。
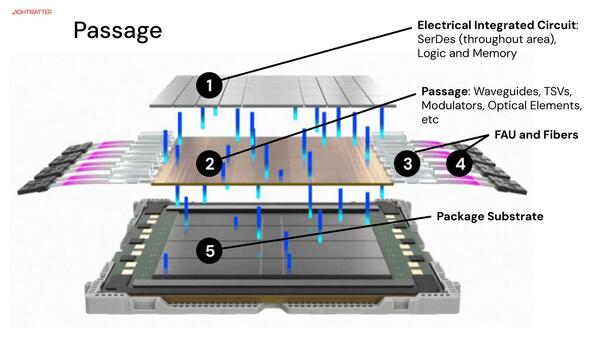
Passageの構造。3層構造の一番下がパッケージ、一番上が顧客の製造するASIC、中間がPassageである。水~青色は電気信号の流れを示す
そのインターポーザーの内部構造が下の画像である。インターポーザー内には4μm間隔で導光路が構築されており、そこに複数個所、MRM(Micro Ring Modulator)が配されている。おのおののMRMはその真上に位置するSerDesとつながる格好になっている。

インターポーザーの内部構造。実際には導光路だけでなくOCS(Optical Circuit Switch)もインターポーザー内に構築されている
これが上で書いた「CPO的な実装では帯域はやはりチップ周辺の長さに比例することに変わりはない」に対するLightmatterからの回答である。
従来のCPOではパッケージの外側にEICとPICを配して、そこから外部に光信号を送り出す形になっていたが、Passageではチップの真下から光信号を出せることになる。つまりパッケージの辺の長さに比例するのではなく、パッケージの面積に比例する形で光信号の送受信が可能になるというわけだ。
これにより、このインターポーザーに載った複数のASIC(の下敷きになっているEIC)同士の通信も極めて広帯域が実現できるし、チップ(というかパッケージ)外への接続も、パッケージ端にあるFiber Attach経由で光ファイバーを接続することで可能になるとする。
このPassageであるが、EICとの接続はBump Pitch 120μm、Bump sizeが80μmと示されている。最近のTSMCのSoIC-Xとかを見ているとかなり粗いPitchではあるが、普通に積層するには十分なサイズではある。
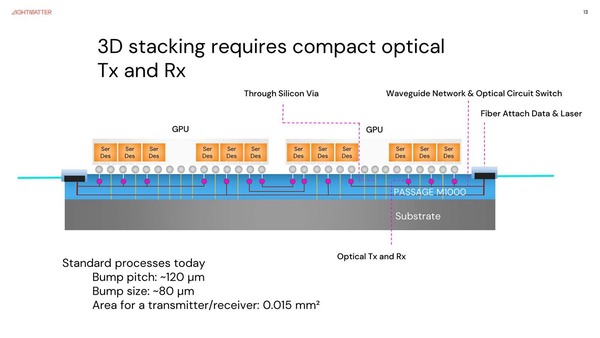
EICとの接続。EICとGPU(ASIC)との位置関係がわかる図である
ただこのサイズだと、このPassageを介してHBMなどをつなぐのはさすがに無理なので、そうした実装が必要な場合にはPassageの上のEICのさらに上に、シリコン・インターポーザーを置く必要がある。
実際の構成図として示されたのは下の画像で、GPUとSwitchのダイをPassageの上に載せる格好になる。
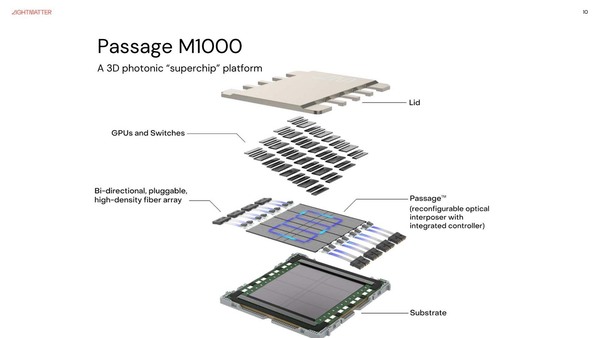
Passageの構成。妙にSwitchのダイが多いのが気になるところ
34個のチップレットで最大4000mm2分のダイを1つのPassageに搭載できる、としているが、これは現在のPassage M1000の最大搭載面積が4000mm2という話で、もっと小さくても実装は可能かと思われる。

どうみても32しかチップレットが見当たらないのは気のせいだろうか?
このM1000のプロトタイプはすでに実在している。一番上の層がパッケージの電気配線層、その下、TSVが並んでいるのがPassageで、その下にボールを介してつながっているのがEICを含むGPUやスイッチ、ということだろう。

Passage全体の大きさはかなりのもの(チップレットの合計が4000mm2なので、63mm角以上の大きさになるはずで、おそらくパッケージ全体は70~80mm角と想像される。当然放熱も液冷が前提である
下の画像にある右の拡大図を見ると、Passageとチップレットがボールを介さずに直接接続されているように見えるが、このページの最初の画像とその次の画像と比較するとどうも様子がおかしい。この拡大図、どうも上下が逆転しているようだ。

上に載るチップレットはChip-on-Waferとなっているが、これはPassageがウェハーの形で製造され、その上にチップレットが搭載されるからと思われる
このテストチップでのPower/Thermalのテスト結果が下の画像で、PassageのTSVは2.5A/mm2を安定して供給できることが証明できたとしている。

つまり369mm2のテストチップになら最大922.5Wの電力を供給可能という話である
また2つのPassageのシステム間を光ファイバーでつないで、800Gbps/Fiberの速度で1kmの距離の転送の動作デモも行なわれたことが示された。

左奥にとぐろを巻いているのが1km分の光ファイバー。ちなみにこれは同社のLabでパートナーに公開しているとのこと
1kmもの距離にもかかわらず、伝達損失はわずか3dBほどにすぎず、BER(ビット誤り率)もFECを利用せずに1E-10未満に抑えられ、フォトニクスで2.6pJ/bit、Electronicsで2pJ/bitの合計4.6pJ/bitという非常に低い消費電力を達成したとしている。
この4.6pJ/bitというのは(最初のページの最後の画像にあった)3pJ/bitをだいぶオーバーしているように思えるが、そもそも光ファイバーを1kmも挟んでいることが影響しているのであって、例えばこれを10m程度にすればフォトニクスの消費電力は100分の1とは言わないが数十分の1まで下がることは想像に難しくない。
そう考えれば、10m程度であれば1pJ/bit以下に抑えられるから、3pJ/bitは十分達成可能な数字であることがわかる。余談だが、光ファイバーを利用する場合、おおむね1mで5ns程度のレイテンシーがかかる。つまり1kmでは5000ns=5μsというかなりの遅延につながるわけで、その意味でも現実的とは言えないだろう。
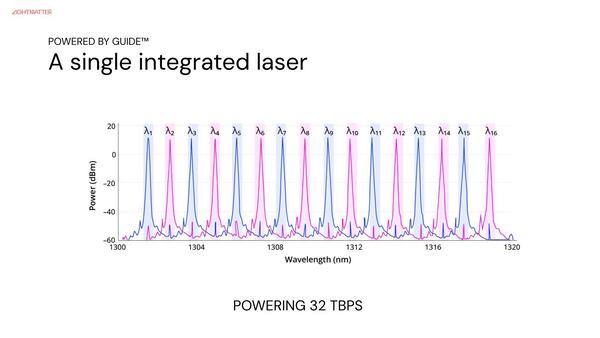
ところで上の画像で16λ(16波長)との記載があるが、PassageではWDM(Wavelength Division Multiplex:波長分割多重通信)を利用している。これは1本の光ファイバーに、微妙に異なる波長の光信号を同時に送り込むことで帯域を稼ぐための手法である。
もともとPassageは内部に光信号の光源を持たないので、外部から連続光を取り込み、これをPassage内のMRMを利用してOn/Offすることで光信号にする。その外部の光源であるガイドは、下の画像のように1301~1318nmの範囲をほぼ1nm刻みで16波長の光を生成するようになっており、これを利用して1本の光ファイバーで双方向400Gbpsづつ、合計で800Gbpsの帯域を持つ。
最初はCW-WDM MSAが制定しているCW-WDM MSA Technical Specificationsに準拠しているのかと思ったら、全然違っていて驚いた
実はこういう使い方はないわけではないのだが、普通だと送信(上の画像で言えば青のTx1→Rx2)と受信(同じく紫のTx2→Rx1)は別の光ファイバーを設けるものだ。
ただそれではPassage内部も、送信と受信で2対の導光路が必要になってしまう。これを1本で済ませるために、あえてこういう構造にしたものと思われる。
ちなみにガイドそのものは最大16本の光ファイバーを接続できるようになっており、これをフルに生かした場合には12.8Tbpsの帯域を確保できる計算になる。もっともPassage M1000の最大構成は、最大256本の光ファイバーを接続できることになっているので、最大構成ではガイドも16個ぶら下がることになる。なかなか壮観な構成になりそうだ。
実際NVIDIAのQuantum-Xフォトニクスの場合、レーザー光源モジュールを18個もフロントパネルに突き刺す構造になっており、こうした形で山のように光源モジュールをつなぐのが今後のトレンドになりそうだ。

これはNVIDIAの紹介ビデオからのもの。下に山のように光ファイバーがつながっており、その上に6×3=18個並んでいるのがレーザー光源モジュールである
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















