



ロードマップでわかる!当世プロセッサー事情 第838回
驚異のスループット! NVLink Fusionで最大900GB/秒を超えるデータ転送速度を実現する新世代AIインフラ
2025年08月25日 12時00分更新

NVLink Fusionは、NVIDIA以外のCPUやXPUもNVLinkで
GPUに直結できるようにした「オープン化版NVLink」
では具体的にNVLink Fusionはどんな形で提供されるのか? ということで、まずCPU向けが下の画像だ。特徴的なのはCHI I/Fを介していることだ。
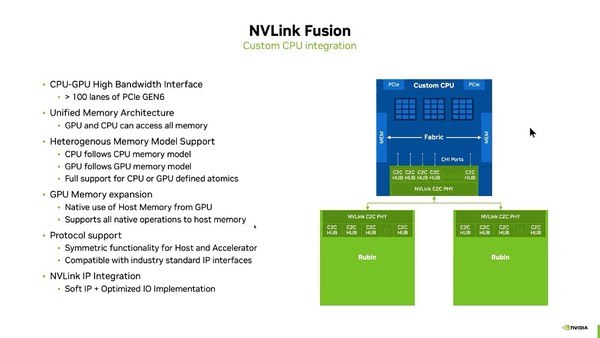
この感じでは、NVLink C2C PHYやC2C HubそのものはNVIDIAからIPが提供されて、それをそのまま使う格好だろうか? CPUからはCHIのI/Fが見えるだけという格好だ
CHIはCoherent Hub Interfaceの略で、ArmがAMBA(Advanced Microcontroller Bus Architecture)として無償公開している、SoC内のCPUと高速な周辺回路(メモリーやPCI Expressやアクセラレーターなど)を接続する際のプロトコルを規定したものの最新版であるAMBA 5の一部として提供されている。
名前の通りデバイス間のコヒーレンシーを確保するためのもので、例えばマルチプロセッサーシステムにおけるCPU同士のメモリー/キャッシュ・コヒーレンシーや、CPUとアクセラレーターのキャッシュ・コヒーレンシーを確保する際に利用されるプロトコルだ。このCHIを利用することで、AMDのAPUと同じCPUとGPUのユニファイド構成が実現できる。
- CPUは自身のメモリーとGPUのメモリーを、1つのユニファイド・メモリーとして自分のメモリー管理下でアクセスできる。
- GPUは自身のメモリーとCPUのメモリーを、1つのユニファイド・メモリーとして自分のメモリー管理下でアクセスできる。
- 両者の間で同期を取る必要がある場合に備えて、Atomic機構(ある領域を誰かがアクセスしている間は、他からはアクセスできない仕組み)が用意される。
ではXPUの側は? というと、NVLinkのプロトコルをCHI C2C(Core to Core)に載せ、それをUCIe上に通すという形で実装することが明らかにされた。
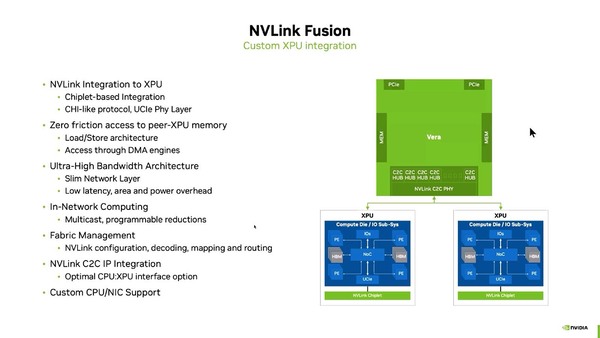
ここでもNVLinkチップレットのIPはおそらくNVIDIAから提供される。XPUからはUCIe経由でCHIのサブセットのプロトコルを実装して通信する格好だ
そのNVLink Chiplet IPの詳細が下の画像である。要するにCHI-LikeなプロトコルをNVLinkベースのプロトコルに変換して通信するのがわかる。
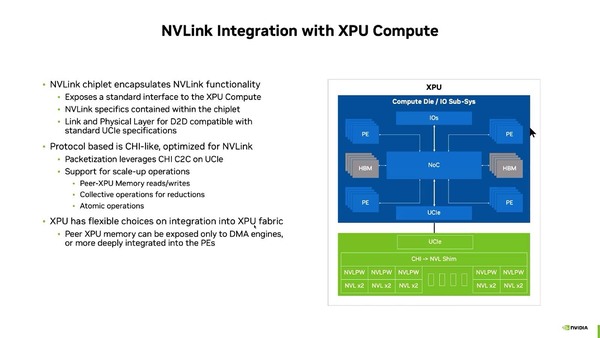
緑の部分はXPUとは別のダイとなり、間をUCIeでつなぐ形になる。NVLink Chiplet IPと書いたのは、NVIDIAがダイそのものを供給はしないだろう、という予測に基づくものである
なんとなくこれで、NVLinkとNVLink Fusionの違いがわかってきた気がする。まずCHIの利用だが、そもそもGrace Hopperの構成を考えたとき、GraceはArmのNeoverse V2ベースのコアなので、Grace内部の72コアのキャッシュ・コヒーレンシーを取るためにCHIを利用するのはごく当然の話で、Hopperとの接続にあたってのキャッシュ・コヒーレンシーはCHIを使っている可能性が非常に高い。
ということは、Hopperの方はGraceとの接続部にCHIとNVLinkの変換機構を当然持っていたはずである。つまり上の画像に出てくる"CHI->NLV Shim"のブロックはHopperにも搭載されていると思われる。
その一方でGrace/HopperやGrace/Blackwell、次世代のVera/Rubinの組み合わせに不要なのはUCIeである。そもそもGrace/HopperもGrace/BlackwellもUCIeを使わずに実装されているからで、おそらくVera/RubinもUCIeを使わずに実装されることになるだろう。
ただこれでは互換性がないので、物理層をUCIeにしたのがNVLink Fusionになる。3つ上の画像で、NVLink C2C PHYがカスタムCPUと同一ダイ内に収められているように見えるかもしれないが、実際にはこちらもNVLink C2C PHYは別のダイで、CPUを収めたダイとの間はUCIeで接続される可能性すらある。
これによるメリットは、業界標準のUCIeで接続できることだ。ではデメリットは? というと、速度がNVIDIAのCPU+GPUの場合より遅くなりそうなことだ。UCIeである以上信号速度は32Gbps/pinに制限される。16bit幅で64GB/秒ほど。Grace Hopperが実現している900GB/秒以上(片方向あたり450GB/秒以上)を実現するには、最低でも113bit以上の幅が必要になる。実際には128bit幅にして512GB/秒というところか。
Advanced Packageなら1mm程度の幅でなんとか配線は収まりそうだが、これではGrace Hopperと同程度の帯域でしかない。実際にはもっとバス幅を広げないと性能を十分に生かしきれないだろうし、配線幅が結構広くなりかねない。これをパッケージで収められるかどうか、というあたりだ。
このチップレットの詳細仕様が明らかになっていないので、現時点ではなんとも言いにくいのだが、このあたりがNVLinkとNVLink Fusionの違いになる。
NVLinkは銅配線ベースのままで、光ファイバーには当面移行しない
最後に余談を。この講演の発表者であるKrishnan Geeyarpuram氏(Senior Distinguished Engineer)に「NVLinkを光ケーブルにする計画は? NVLink 6もまだ銅配線ベースのままなのか?」と質問したところ、回答は「NVLink 6のOberon rackはBlackwellベースのNVLink5と同じ銅配線ベースのものとなる。我々のNVLinkに対しての目標は、可能な限り銅配線のままで、性能や消費電力、レイテンシーの目標を達成しつつスケールアップすることだ」という返事が返ってきた。
要するにNVLink C2Cだけでなく、その先のNVSwitchへの配線も引き続き銅配線ベースのままとし、光ファイバーには当面移行しない(少なくともNVLink 6は間違いなく銅配線だし、この書き方だとNVLink 7も銅配線のままっぽい)ことが明らかにされたのは、筆者には驚きだった。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































