




最近巷ではAIの話題で持ちきりだが、ユーザーと言語で対話する「言語モデル」をベースにしたAIには、現状大きく「クラウド推論」と「ローカル推論」の2つがある。
クラウド推論は大規模なデータセンターで推論エンジンを動かし、多数のユーザーに同時にサービスをする。これは、どちらかというと最近になって始まったものだ。Windows 11で動いているCopilotはクラウド推論で動作している。
ローカル推論は、目の前のPCで推論をするもので、問いあわせ内容(プロンプト)や推論エンジンに与えた情報は、PCから外には出ない。
クラウド推論はデータセンター側のハードウェアコストがあるため、一定時間内での利用回数を制限する、あるいは処理間隔を長くするという方法が使われる。このような制約はローカル推論にはなく、自分のマシンなので当然ながら独占して利用できる。
ただし、その推論性能はローカルマシンの性能に依存し、CPU/GPU/NPUやメモリサイズ(推論モデルは原則としてオンメモリで推論が実行される)で制限がかかる。前者は回答を得るまでの時間、後者は実行可能なモデルの大きさに影響する。
Foundryでローカル推論を動かす
対話型の言語モデルを使う方法としてマイクロソフトが提供しているのがFoundry Local(https://learn.microsoft.com/ja-jp/azure/ai-foundry/foundry-local/get-started)というソフトウェアだ。これはコマンドラインで動作し、複数の言語モデルをダウンロードしてローカル推論を実行できる。
Foundryが対応するモデルは、Azure Foundryカタログ(https://ai.azure.com/catalog/models)に登録されているものがベースになる。このFoundry Localで導入するモデルは、CPU/GPU/NPU対応というバリエーションがあり、NPUを搭載しておらずCopilot+ PCでなくとも実行できるものがある。
ただし、求められるGPUスペックなどにも条件があり、機種によって表示されるモデルに違いがある。基本的には実行可能なモデルのみが表示される。また、実行時にはモデルのバリエーションのうち、最も高い性能で実行できるものが選ばれる。
インストールは、Wingetで可能だ。
winget install Microsoft.FoundryLocal
コマンドは、Foundry.exeだが、アプリ実行エイリアスになっている。大きく3つのサブコマンドと単独コマンドがある。とりあえずは、「--help」でコマンドラインオプションの概要を見ることができる。
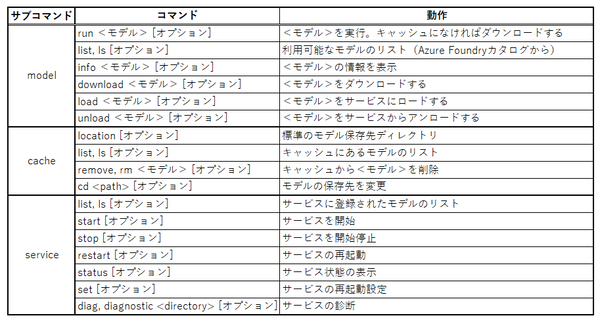
Foundryは、単純なコマンドではなく、モデルの管理や推論を実行する「サービス」と、モデルをローカルファイルとして管理する「キャッシュ」、そして「(言語)モデル」から構成されている。
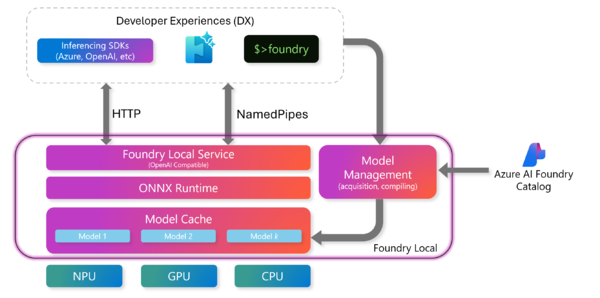
Foundryは、サービス、キャッシュ、モデルから構成されており、サービスは、アプリケーションにAPIを提供するほか、コマンドラインからプロンプトを受け付けてこれを処理する。マイクロソフトのサイト(https://learn.microsoft.com/ja-jp/azure/ai-foundry/foundry-local/concepts/foundry-local-architecture)から引用
インストールが終わったら、以下のコマンドで実行可能なモデルのリストを表示させてみる。Foundry.exeはアプリ実行エイリアスなのでPath環境変数などの設定は不要である。
Foundry model list
表示されるモデルが、現在のハードウェアでローカル実行が可能なものだ。高性能なGPUやNPUを装備しているマシンでは、Device欄にNPUやGPUが表示される。


ARMプロセッサのCopilot+ PCとNVIDIAのディスクリートGPUを搭載したPCでlistコマンドを実行させた。ハードウェアに合わせてモデルやDeviceの異なるモデルが表示される
ここにCPUと表示されるのは、CPUのみで推論可能なモデルを意味する。GPUの場合は性能により、表示されるモデルが異なる。アクセラレーターとして想定されているGPUは、NVIDIAの2000シリーズ以降、AMDの6000シリーズ以降、QualcommのSnapdragon X Elite、Intel iGPUとなっているが、GPUのVRAM容量やPCのメモリなども考慮してリストを出力する。
今回は手持ちの機材の関係から試すことができなかったが、16GB以上のVRAMを搭載したNVIDIA GPUを装備したマシンでは、オープンソース版GPT-OSSモデルの利用が可能だという。
とりあえず、適当にモデルを実行させてみる。このとき、listコマンド出力の先頭にある「Alias」を指定すると、適切なバリエーションを選択してモデルを実行できる。
Foundry model run phi-4
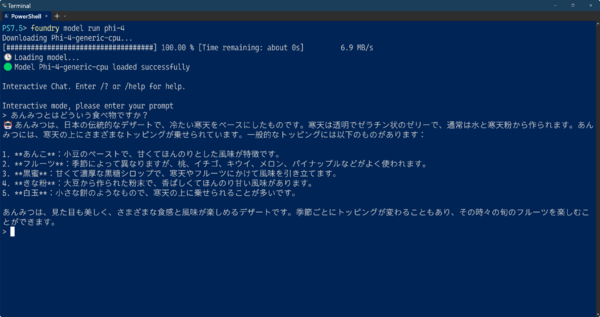
foundry model runコマンドでphi-4を実行したところ。ダウンロードが終わると、すぐにプロンプトを受け付けるモードに入る
初回は、モデルをダウンロードするが、1回モデルをダウンロードしたら、キャッシュとしてローカルファイルで保存される。ただし、保存されたモデルが使われるのは、ダウンロードしてから約10分間で、その後はrunコマンドなどの実行時に新規にダウンロードされる。
これは、モデルが常時更新されており、常に最新のモデルを使うためである。このような構造になっているので、モデルの保存は「キャッシュ」と呼ばれるわけだ。listコマンドの出力には、モデルのサイズがあり、これをダウンロード時間の目安にできる。
runコマンドでは、ダウンロード後、すぐにプロンプトの入力になる。モデルの多くは日本語の入力を受け付ける(一部文字化けすることがある)。
Foundryは、単にコマンドラインからモデルとチャットするだけでなく、APIとしても動作できる。また、Hugging Face(https://huggingface.co/)に登録されているモデルを変換してFoundry Localのモデルとして利用することも可能だ。
この連載の記事
-
第520回
PC
WindowsターミナルのPreview版 v1.25では「操作」設定に専用エディタが導入 -
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する -
第510回
PC
PowerShellの「共通パラメーター」を理解する - この連載の一覧へ













で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")













































