




48ノードが1ラックの定格
10ラック・480ノードで1つのグループを構成
そのGrace Hopperであるが、今回のJUPITER Boosterで使われたBullSequana X3000シリーズの場合は1つのキャリアボードに4つのGrace Hopperが載っており、これで1ノードを構成。ラックにはこのキャリアボードを2枚搭載する形で実装される。
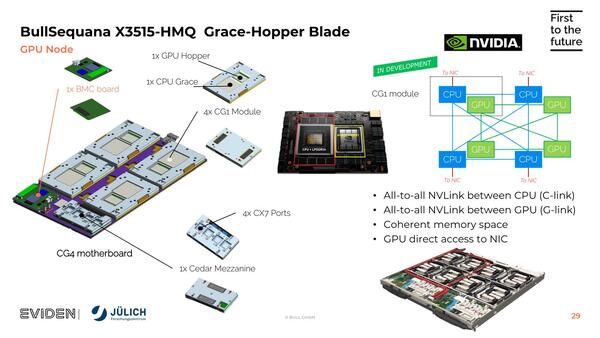
ここからは"Evolution of the Sequana System Architecture"という2024年5月のスライドより。左のGC4 マザーボードというのがキャリアボードで、右下がブレードサーバの構造。2つのCG4が搭載されている
つまり1ブレードあたり8つのGrace Hopperが載る形だ。4つのGH200で1つのノードを構成するということなので、要するにシステムのノード数は2万3536÷4=5884という計算になる。
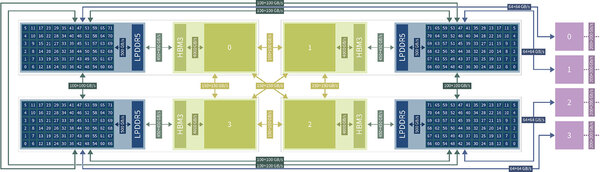
これは"JUPITER Technical Overview"より。1つのGraceからは2本の200Gb/s InfiniBandが出るので、1ノードあたり8本。シャーシには2ノードが載るので、1本のシャーシから16本の200Gb/s Infinibandが出る形
ラックそのものは、ご覧のように最大38個のブレードを格納可能だが、ブレードそのものは24枚、つまりノードとしては48ノードが1ラックの定格で、10ラック・480ノードで1つのグループを構成する。

実際にはこれ全部をGH200で埋めると電力供給と放熱容量的に足りないのだろう
そのグループ同士をDragonFly+で接続するというなかなか壮大な構成である。ちなみになぜ10ラック・480ノードで1つのグループを構成しているとわかるかというと、説明ビデオの中で、あるグループを簡単に置き換えできるモジュラー構造になっているという説明があったからで、この10ラックが1つのグループとしてまとめられているようだ。
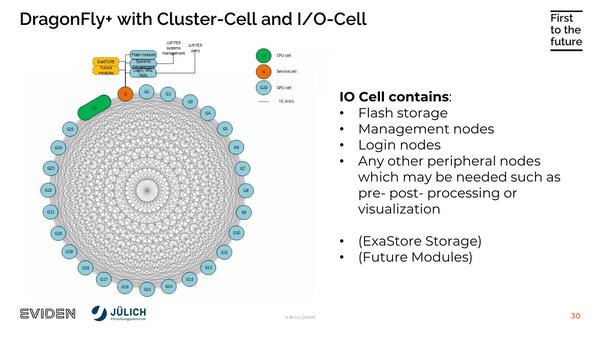
ネットワーク模式図。それぞれのクラスターと別のクラスターの間をPeer-to-Peerで接続する。接続はInfiniBand 200Gのままの模様

動画では、このグループを将来は量子コンピューターに置き換えることも可能、といった説明をしていた
ちなみにグループとは別の概念としてクラスターがあり、こちらはジョブを分散させる単位の模様だ。このクラスターは1300以上のノードから構成され、1つのクラスターの演算能力はFP64で5PFlopsを超える、という説明がある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































