



ロードマップでわかる!当世プロセッサー事情 第817回
実現困難と思われていたUCIe互換のチップレット間インターコネクトをTSMCとAMDが共同で発表 ISSCC 2025詳報
2025年03月31日 12時00分更新

クロック信号の品質補正回路はデジタル回路で構成し
Clock Gatingの解除に即時対応する必要がある
一方受信側回路が下の画像である。ここでのポイントはクロック信号の受信回路である。Clock Gatingが行なわれているケースで、Gatingが解除された場合、解除された直後の最初のクロック信号で直ちにデータを受信できるような仕組み(論文ではこれをMatched-delay Architectureとしている)が必要である。
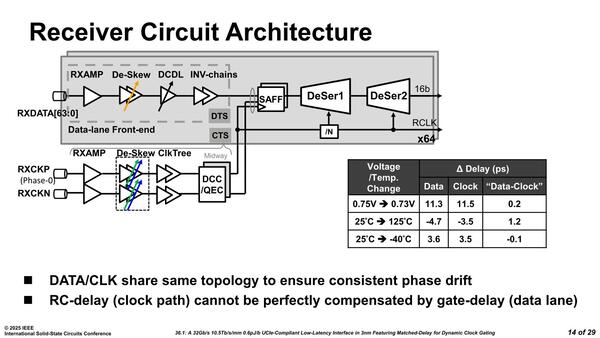
クロック信号とデータ信号の差を完全に補償することは不可能だが、この程度であれば許容範囲ということらしい
このために、DCC(Duty Cycle Corrector)およびQEC(Quadrature Error Corrector)というクロック信号の品質補正回路は、アナログではなくデジタル回路で構成され、Clock Gatingの解除に即時対応できるようにする必要がある、としている。
ちなみにこのDCCとQECでは、Duty Cycle Errorを0.3%未満、直交位相エラーを330fs以下に抑えられるように設計されているとのことだ。特に、激しい電圧降下が起きた場合、これはClock Preamble(クロック信号の先頭部分に付く特別な信号)だけではリカバリーできず、32GT/秒のレシーバー側のDLL(Delay Locked Loop:タイミング調整回路)でカバーできる能力を超えるとされる。
こうした状況への対策として、受信側はフロントエンドを通した後のSAFF(Sense Amp Flip Flop)でRXCKP/RXCKNのクロック信号でタイミングを同期させることで、クロック信号とデータ信号の位相を一致させるように工夫している。右の表は電圧あるいは温度変化があった場合のクロック信号とデータ信号のズレを測定したもので、例えば20mVの電圧変動があると11ps以上の遅れが発生するが、ズレそのものは0.2psに抑えられる。
また受信側は、Self-DeskewおよびRuntime Re-Calibration(自動でのタイミング調整と、動的な校正機能)を搭載しており、これによってさらにズレを抑え込める。
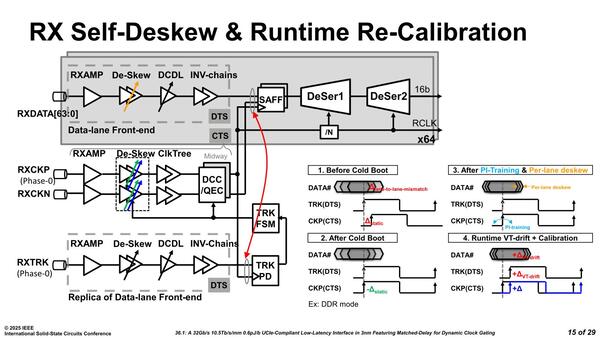
Self-DeskewおよびRuntime Re-Calibration。1.は赤、2は緑、3は黄色、4.は青色がそれぞれ調整を行なう部分となる
具体的には、以下のことが実行される。
- コールドブート、つまり初めて電源を入れたときには、各レーンごとに設けられたSKEW調整用のバッファを通して、クロック信号をTRK(Track信号)に合わせることで、データ信号とクロック信号の静的ミスマッチを最小限に抑える。それが終わった後は、De-Skew機能を利用して、ずれを最小限に抑える。
- After PI-Training & Per-lane deskewは、最初のタイミング調整が終わったら、データレーンごとにSKEW調整をして、個々のレーンに用意されたBIST(Build In Self Test)機能を利用しながらData Eyeを最大になるように自動調整する。
- Runtime VT-drift + Calibration、つまり実際にデータを送受信している間に再びCKPとTRKの不一致が確認された場合、Clock信号のDe-Skewバッファを一致するように自動調整する。
下の画像がインターポーザー(とその上に重なるSoCダイ)の物理的な配置である。問題としてKGD(Known Good Die:良品ダイ)の選別が品質テストには不可欠だが、バンプピッチが小さいため、電源/GNDのバンプへのアクセスが制限されることが挙げられているが、これをどう克服したかの説明はない。
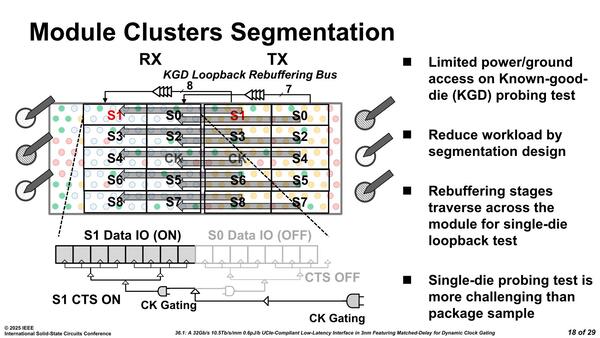
パッケージ全体の測定よりも、インターポーザー上の1つのダイのテストの方が大変だったとのこと。ただ具体的にそれをどう克服したか、の説明はなかった
ちなみに最大で32GT/秒の高速テストを、IRドロップや電源変動の影響を最小に抑えながら実施するため、信号はS0~S8まで9つのセグメントに分割され、BER(Bit Error Rate)のテスト時には1つのセグメントのみをアクティブにするように実施されたとのことである。
電源供給に関しては、SHDMIM(Super High-Density Metal-Insulator-Metal)コンデンサーをインターポーザーの上に配した場合と、これに加えてeDTC(embedded Deep Trench Capacitor)を組み合わせた場合の両方を比較し、eDTCを利用することで大幅にリップルを低減できた(102mV→32mV)ことを確認している(下のグラフの右側)。
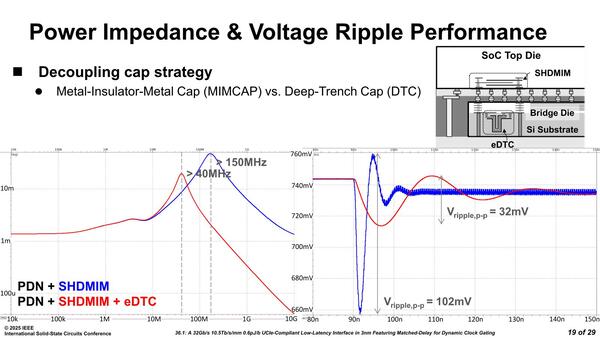
左のグラフはインピーダンス特性で、SHDMINは1mm2あたり50nF程度の容量しかないため、電源インピーダンスを軽減できるのは150MHz以上だが、eDTCは1mm2あたり1100nFの容量を確保できるため、40MHz以上の電源インピーダンスを軽減できるとしている
そもそもシリコンインターポーザーは表に露出しない(ダイかパッケージの下に隠れている)ので、シリコンインターポーザーの真上にSHDMINを載せることはできず、パッケージを経由して載せる格好になる。したがってeDTCよりも効果が薄いのは理解できるが、逆に言えばシリコンインターポーザーにeDTCを埋め込む(これは当然高コストになる)のがUCIeで安定動作を望む場合は必須ということかもしれない。
そのシリコンインターポーザーを横から見た断面図が下の画像で、5層の配線層を持つ構造となっている。Sが信号、GがGND、PがPower(電源)で、信号配線をGNDで囲うように配することで配線クロストークノイズ(信号同士の相互干渉)を最小限に抑えたとする。
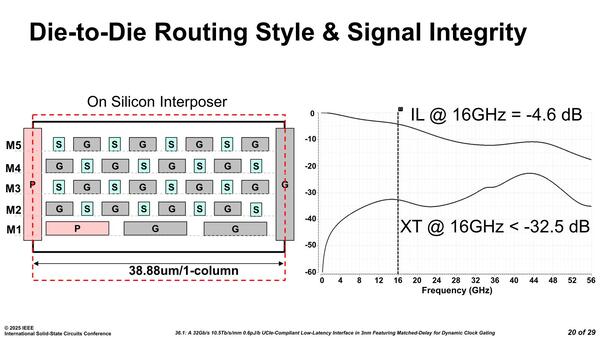
ILがInsertion Loss(配線の挿入損失)、XTがクロストークのSignal Integrityを示している。16GHzにおける数字はそれぞれ-4.6dB、-32.5dBで非常に良好として良いだろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































