



ロードマップでわかる!当世プロセッサー事情 第816回
シリコンインターポーザーを使わない限界の信号速度にチャレンジしたIBMのTelum II ISSCC 2025詳報
2025年03月24日 12時00分更新

性能はTelum比で1.3倍
AIアクセラレーターに関してはあまり新情報はないのだが、「自分のチップ内のAIアクセラレーターがBusyで、同じDrawer内の別のチップのAIアクセラレーターが空いている場合、そのAIアクセラレーターを利用できるので、最大192TOPSの性能」というのは、Virtual L4と同じような発想である。

連載790回の画像とあまり差がない。ただチップ右上にCompression Moduleがあることが今回明らかにされた
A-Bus経由で別のDrawerのAIアクセラレーターまで駆動できるかどうかは定かではないが、この書き方からするとVirtual L4に同一Drawer内に限られるようだ。これで足りなければ連載790回で書いたようにSpyreアクセラレーターを使うという形になる。
Telum IIにある個々のコアが下の画像で、パフォーマンス改善に関してはレジスター数の増加、ストアーバッファのライトバック機能の搭載、それと分岐予測の改善が挙げられている。逆に言えばこれと動作周波数向上が主な性能完全の要因とみられ、パイプラインの大幅変更などは特にされていないようだ。

Telum IIにある個々のコア。Area shrinkは主にプロセス微細化によるものと思われる
連載790回でDPUのブロック構造を紹介したが、実際の実装が下の画像だ。個々のクラスターには8つのMCUが配されるという説明があったが、スライドを見ていると最上段に4つ、左右に2つづつ配されているようだ。その真ん中になにが入っているのかは不明だが。
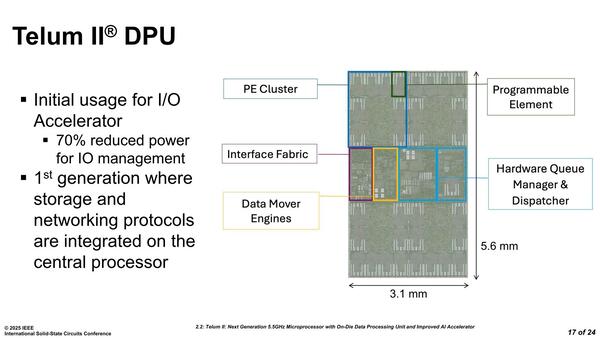
ブロック図でCluster A~Dに当たるのが上下に2つづつ配されたPE Clusterというブロックで、その間にCoherent FabricやHardware Queue Manager&Dispatcher、Data Mover Engineが配される
最後に性能について。下の画像は絶対性能ではなく、同一消費電力当たりのIPCを比較したものであるが、順調に性能を伸ばしているとする。ほぼどの処理でもTelum比で1.3倍ということになっており、世代ごとの性能比としては妥当なところと思われる。
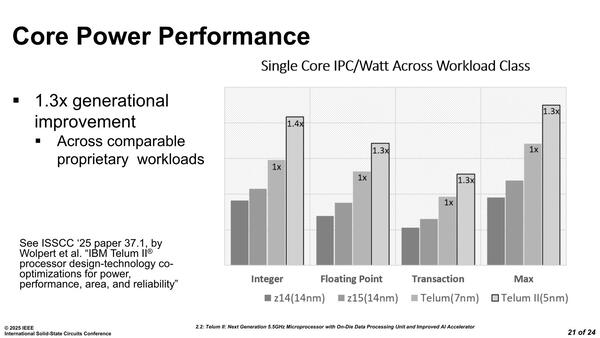
縦軸の単位が不明だが、Telumを1.0とした時には全項目でTelum IIは1.3~1.4倍の性能とされる。ところでMaxは何のテストなのだろう?
問題があるとすればチップあたりのコアの数が10→8に減っていることで、これはDPUを搭載したのが主な要因と思われる。記事冒頭の画像を見返すと、例えばDPUを2つに分割して"Package/Drawer interface"ブロックの両脇に配するなどの方法もありそうに思えるのだが、そうしなかったのはなにか理由があるのだろう。そのあたりの事情を知りたいものである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























