



ロードマップでわかる!当世プロセッサー事情 第814回
インテルがチップレット接続の標準化を画策、小さなチップレットを多数つなげて性能向上を目指す インテル CPUロードマップ
2025年03月10日 12時00分更新

6スレッドで動作をさせたところ6FPSの処理性能を実現
ハードウェアのスペック的には30fpsまで持っていける
メモリータイル×3+コンピュートタイル×1の構成でResNetを動かしてみた際の消費電流と所要時間が下の画像である。
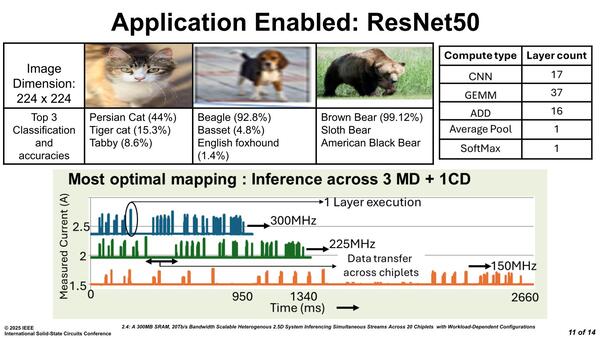
ResNet50を利用してのImage Classification(分類)の結果は、悪いものではない
CNNが17層、GEMMが37層、加算が16層、PoolingとSoftMaxがそれぞれ1層で合計72層の処理になるが、300MHzなら1秒程度で処理可能。150MHzになると大分間延びして2.7秒近くになっている。この間延びの理由の分析が下の画像だ。ただ今回は全部で4タイルでの処理なので、単純に言っても20タイルを全部動かせば5スレッドは同時に走らせられる計算になる。
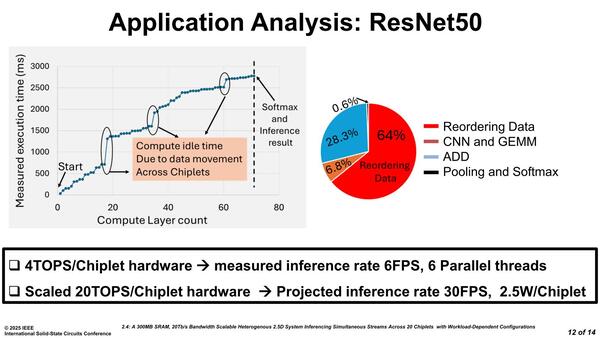
やはりタイル間の通信がレイテンシーの大きな要因となる。ちなみにこの数値は300MHz動作の場合の話であろう。これを例えば1.5GHzまで動作周波数を引き上げれば30fpsになり、その際の消費電力は2.5Wに収まるという推定だが、実際にはもう少し消費電力は増えそうな気がする
インテルによれば6スレッド動作をさせたところ6FPSの処理性能が実現でき、ハードウェアのスペック的には30fpsまで持っていけるとしている。ただしこのタイル間の通信がけっこう大きなボトルネックになっており、これをなくすだけで3倍高速になることを考えると、この方式で商用製品に持ち込むにはもう一捻り、二捻りする必要がありそうという結果になった。
このチップレットを使った複数コアの考え方は、IEDMで発表された「小さなチップレットを多数つなげる」に通じるものがあるのだが、実際にはまだ大きなチップレットを少数つなげる方が性能が出やすい、という結果に終わったのは(皮肉ではあるが)意味がある結果ではあったことになる。
これを改善するには、インターコネクトの方法を変更するか、やはり3D方向に積層するか、それともなにか別の手段をもってくるか、いずれにせよまだ研究が必要であることは間違いなさそうだ。
この連載の記事
-
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 - この連載の一覧へ




























")



















