



ロードマップでわかる!当世プロセッサー事情 第805回
1万5000以上のチップレットを数分で構築する新技法SLTは従来比で100倍以上早い! IEDM 2024レポート
2025年01月06日 12時00分更新

昨年12月7日~11日にかけ、サンフランシスコでIEDM(International Electron Device Meeting) 2024が開催された。前回と前々回に続いてこの内容について取り上げたい。
第3弾の今回は、Selective Layer Transfer。正式な名称は31-5の"Selective Layer Transfer: Industry First Heterogeneous Integration Technology Enabling Ultra-Fast Assembly & Sub-1um Chiplet Thickness for Next Generation AI & Compute Applications"という長いものである。
2枚のウェハーを重ねて接着して
1万5000以上のチップレットを数分で構築
インテルのプレビューでのスライドが下の画像だが、そもそもこれはなに? というものだった。

1枚のウェハー上に、1万5000以上のチップレットを数分で構築するための手法ということになる
この発表は、非常に小さなチップレット(それこそ上の画像にあるような1mm角のもの)を、きわめて高速にWafer on Waferの技法で、構築するのに赤外線レーザーを利用する、という内容である。
前回も触れたが、Hybrid Bondingは極めて有望なチップレットのための接続技術である。その一方で、「2つのダイの接続面が正しい位置関係にないと、うまく信号が伝わらないことになる。このための位置合わせの精度は1μm未満でないといけないわけで、これに猛烈な手間(とコスト)が掛かる」という問題が付きまとう。
特に難しいのは、チップレットのためのダイを一旦ウェハーから切り出し、改めて接続面をキレイにしたり、正確にインターポーザーなり別のダイなりとの位置を合わせて積層する作業である。
そもそも1mm角のチップレットの正確な位置合わせや、1mm角のチップのクリーニング、表面研磨という作業がとても難易度が高い。研磨にせよ位置合わせにせよ、1mm角という小さなダイに対して行なうことそのものが難易度を無駄に引き上げている。
加えるなら、300mmウェハーで1mm角のダイを取った場合、4万9000個弱(切り代0.2mmの場合)ものダイが取れる。ということはこの面倒な作業をウェハー1枚あたり4万9000回も繰り返すことになる。「数時間から数日」という上の画像の表現は大げさなものとは言いにくい。
こうした工程を効率化するために、WoW(Wafer on Wafer)の技法が提案されているわけだ。クリーニングなどはウェハー単位となるため、ダイ1個のクリーニングよりは時間がかかるにしても、4万9000回繰り返すよりは圧倒的に短時間で済む。位置合わせも、ウェハー単位で1回やればいいので、こちらも圧倒的に短時間である。
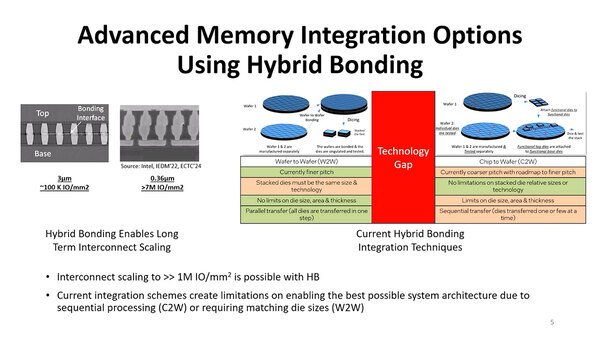
このスライドではCoW(Chip on Wafer)やWoW(Wafer on Wafer)の代わりにC2W(Chip to Wafer)/W2W(Wafer to Wafer)としているが、意味は同じである
ただ従来のWoWの問題は、「同じサイズのダイでないと積層できない」ことだった。要するに2枚のウェハーを重ねて接着後に、まとめてダイシング(切り出し)をするから異なるサイズのものは載せられない。これはチップレットには少し使いにくい制約であった。今回の論文はこれに対する解決法を提案するものである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































