



エンジニア魂が燃えたぎる!生成AI開発イベント「AI Challenge Day」 第3回
RAGとマルチモーダルにチャレンジするエンジニアの祭典が戻ってきた
生成AIの熱き戦いが品川でも! GPT-4oもフル活用されたAI Challenge Day 2nd
2024年07月19日 09時00分更新

事前学習とトライ&エラーが効を奏したパソナ
7社目はパソナの萬宮はるか氏。パソナというと人材系企業という印象が強いが、その強みを活かしたITカンパニーへの変革を進めており、今回のメンバーも生成AIの開発実績を持つ。具体的には派遣スタッフ向けのボットや提案の自動作成、プロンプトテンプレートなどを構築している。また、前回大会の情報はかなり読み込んできたという。

パソナの萬宮はるか氏
評価スクリプトは19.775点。生データのみの1回目は17.375点、Document Intelligenceを導入した2回目はファイル数が少なく15.125点に落ちたが、画像を追加した3回目は18.27点、プロンプト調整を行なった4回目でこの得点まで高めることができた。
アーキテクチャはPrompt Flow、AI Search、Document Intelligenceなどを用いた鉄板構成。ただ、事前に予定していたPrompt FlowからApp Serviceへのデプロイが時間内に行なえなかった。「App Serviceが立ち上がれば、仮想ネットワークでエンタープライズを意識したセキュアな構成ができたのかなと思っています」(萬宮氏)とのこと。Prompt Flow+App Serviceの代わりにContainer Appsでのデプロイを試して、完成までたどり着いた。質問応答FAQアシスタントの動作も動画で披露された。
RAGに関しては、質問応答FAQアシスタントとマルチモーダルアシスタントで異なる構成となった。前者は入力されたテキストを元にPrompt Flowでクエリを生成し、AI Searchに送信し、GPT-4oで回答を生成する。また、後者のマルチモーダルはテキストと画像を入力して、GPT-4 visionで画像を解説させ、AI Searchを経由し、GPT-4oで回答を生成する。本来は画像インデックスをいったん検索し、その結果を基に文書インデックスを検索するという構成が取りたかったが、今回は時間が足らなかったという。
RAGの構築で工夫した点としては、まずPrompt Flowを用いて、とりあえず動くものを作るという施策。評価スクリプトを回して改善を続けるというサイクルを細かく回したのは、前回の情報をきちんと読み込んで来たからこそと言える。
また、AI Searchのインデックスは文書と画像の2種類を用意した。文書は生データとDocument Intelligenceでの前処理を試した後、後者を採用。画像のインデックスはGPT-4oに画像を説明させ、JSON形式で出力した上で登録したという。精度向上を目指し、元データのファイル名をJSONに追加しているという。触って試してみるというのが、パソナ流のAI開発のようだ。
その他、プロンプトの精度を上げるために英語を使ってみたり、GitHub Actionsからデプロイできるようにしたり、PythonとSDKからAI Searchにアクセスできるようにしたり、とにかく工夫やチャレンジ満載。さらにコストを意識して、2日間の利用を安価に抑えたというのも実運用には必要な観点で感心した。
RAGの構築でコストを意識
カスタマーストーリーとしては、旅行客が直接利用したり、インバウンド利用を想定して、質問言語で回答する制御や文化財としての重要性や建築年数などの重要な情報は回答に含めるようにプロンプトを制御しているという。反省としては、「FAQアシスタントとマルチモーダルアシスタントを1つの画面から呼び出せるようにしたかった」(萬宮氏)のほか、想定したフローが時間内にできなかったり、Prompt Flowでデプロイまでいたらなかった点、セキュアな環境構築まで進めなかった点が挙げられた。
日本マイクロソフトの清水氏は、「普段からサービスを企画しているとのことで、コストの話や仮想ネットワークでのセキュリティの話など、SaaSビジネス化のポテンシャルを感じさせます。Prompt Flowをうまく使えなかったということでしたが、新しいツールにチャレンジしてもらったのが印象深かった。実験を繰り返して、いいものを探していくという姿勢は、ビジネス化においても重要で、普段からこうしたアプローチをしているんだなと見てとれました」と感想を語った。
・関連ブログ
「第2回 AI Challenge Dayに参加してきました!」
脳筋フル活用でLLMガチャにも強かったBIPROGY
8社目はBIPROGYの阿部 建氏。今回参加した5人のメンバーは、普段AI全般の技術検証や製品開発、運用を手がけているが、昨年からはほぼ生成AI一色となっているとのこと。Azureのスターターセットを開発したり、地方自治体、保険、金融、流通など業種横断でさまざまな PoCなど実績を持っているという。「今回2日間は考える脳筋だった。LLMガチャに負けないよう、評価が上振れするよう、最後は祈りながらいろいろ試しました」と安部氏は語る。

BIPROGYの阿部 建氏
評価スクリプトはここまでで最高の21.450点。内訳としてはテキストの30問が23点程度、画像系の10問が16~17点程度とのことで、やはりマルチモーダルは難しいという感想。一方で、「日本語としての流ちょうさ」という評価項目に関しては、GPT-4oの性能がすごすぎてつねに高いポイントを得られていたという。
アーキテクチャはオーソドックスで、AIオーケストレーターからAI SearchやAzure OpenAI ServiceのGPT-4oをたたきに行くというもの。インデックスはDocument Intelligenceで作られたテキスト用と、Azure AI Serviceで作られた画像用を用意。データに関してはローカルのPythonで処理を施したのちアップロードを行なっているとのこと。エンタープライズ実装も想定しており、管理者向けAppやAzure Functions、BlobStorageなどを利用したデータ入力の簡素化や、FrontDoor、Private Endpointなどを用いたセキュリティの実装を想定しているという。
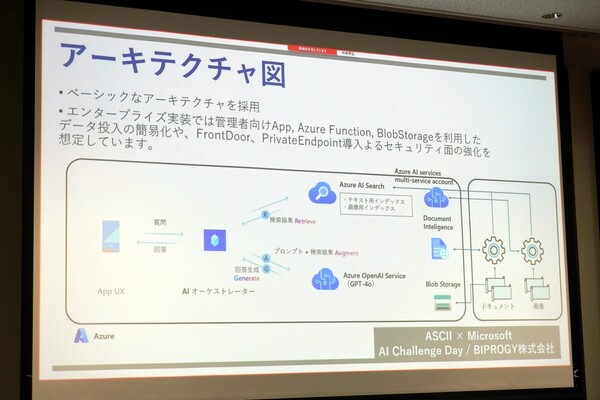
エンタープライズ実装も想定したアーキテクチャ
RAGについてはクエリを生成し、仮の正答を想定して類似検索をかけて、埋め込みを行ない、ハイブリッド検索を行なえるようにした。画像に関しては、一度画像インデックスに対して類似検索をかけ、どのようなコンテキストで使われているのかの情報を取得した上で、回答を生成しているという。
工夫としては、回答生成から評価までを自動実行させることで、サイクルの高速化を図った点が挙げられる。また、Azure DevOpsによるソースコードの管理も実施。試行錯誤したところはチャンクサイズ、オーバーラップサイズ、検索のtop_kなどのパラメーター調整、embeddingモデルの比較などを実施した。
テキスト化に関しては、試行錯誤の末、Document Intelligenceの採用がもっとも精度が高いと判断。「PDFやWordをPNGに変換し、GPT-4にぶちこむと、文字起こしもしつつ、画像の説明もきれいにしてくれるのでは?とも考えた」(阿部氏)とのこと。また、マルチステップ検索で画像検索を行なって画像のコンテキストを取得した上でテキスト検索をしたのは精度の向上に寄与したという。
さらに網羅性、背景をリッチにするためにシステムプロンプトを改修。「ここはどこ?と聞いて、寺の名前が返ってくるだけだと寂しい。この寺は、どんな寺という背景情報を入れるべきだと考えた」ということで、ユースケースも意識して付加情報も挿入するようにした。これにより、さらなる精度向上ができたのではないかと安部氏は語る。
審査員である日本マイクロソフトの花ヶ崎氏は、「LLMガチャとおっしゃっていましたが、僕から見るとベースラインをきちんと抑え、そこから精度を上げるというデータサイエンスの基礎をやってくれたのではないかと思う。さらにそれを回すためにLLM Opsとよばれるような自動化を実装して、精度向上させている。アイデアに関しても、僕もマルチステップ検索を実装してくれればいいなと思いながら作っていた。閉域化に関しても、Private Endpointを言及いただけたのがよかった」とコメントした。
・関連ブログ
ASCII × Microsoft の生成AIコンテスト「第2回 AI Challenge Day」参加レポート
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第9回
sponsored
便利なのに楽しくないネット通販 エンジニアたちが次の買い物体験を真剣に考えてみた -
第8回
sponsored
“買いたくなる体験”をAIでどう作る? ─ RAG×エージェントで火花を散らす12社の挑戦 -
第7回
sponsored
RAG、マルチモーダル、AIエージェント AI Challenge Dayで生成AIの高みを目指せ -
第6回
sponsored
生成AIのパートナー探しに最適 生配信が楽しみなAI Challenge Dayは11月14日開催 -
第5回
sponsored
AIエンジニアたちを熱狂させたAI Challenge Day その楽しさを審査員のオオタニが教えよう -
第4回
ビジネス・開発
AIコンテストの優勝チームが持ち合わせていたのはデータ処理と課題設定の強み -
第2回
sponsored
生成AIアプリ開発で精鋭10社が熱戦! 第2回「AI Challenge Day」の模様をお届け【YouTube配信中】 -
第1回
sponsored
日本マイクロソフトのAIパートナー10社が神戸に集合 RAGとマルチモーダルに挑む - この連載の一覧へ



